线程安全的集合类
原来的集合类,大部分都是线程不安全的.
Vector,Stack,HashTable,是线程安全的(不建议用),其它的集合类不是线程安全的.
多线程使用ArrayList
1.自己使用同步机制(Synchronized或者ReentrantLock),前面已经做过许多讨论了,这里不再展开.
2.Collections.synchronizedList(new ArrayList);?
相当于给ArrayList套壳->得到了新的对象,新对象里面的方法都是加锁的.
synchronizedList是标准库提供的一个基于synchronized进行线程同步的List.synchronizedList的关键操作上都带有synchronized.
3.使用CopyOnWriteArrayList.
CopyOnWrite容器即写时复制的容器,这个主要用于解决多个线程修改一个数据的问题.
当我们往一个容器添加元素的时候,不直接往当前容器里添加,而是先将当前容器进行Copy,复制出一个新的容器,然后向新的容器里添加元素,
添加完元素之后,再将原容器的引用指向新容器.
一旦有线程修改值时,把顺序表复制一份,修改这个顺序表的内容,并修改引用的指向(这个操作是原子的)
这样写的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素.
所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器.
比如服务器在加载配置文件时,就需要把配置文件解析出来放到内存数据结构.
优点:在读多写少的场景下,性能很高,不需要加锁竞争.
缺点:1.占用内存较多(因此修改不能太频繁). 2.新写的数据不能被第一时间读取到.
多线程环境使用队列
1.ArrayBlockingQueue? (基于数组实现的阻塞队列)
2.LinkedBlockingQueue (基于链表实现的阻塞队列)
3.PriorityBlockingQueue (基于堆实现的带优先级的阻塞队列)
4.TransferQueue (最多只包含一个元素的阻塞队列)
多线程环境使用哈希表
HashMap本身是不安全的.
在多线程环境下可以使用: HashTable, ConcurrentHashMap.
HashTable
只是简单的把关键方法加上了synchronized关键字.
public synchronized V put(K key, V value) {
public synchronized V get(Object key) {
这相当于直接针对HashTable对象加锁.
如果多线程访问同一个HashTable就会造成锁冲突.
size属性也通过synchronized来控制同步,也是比较慢的.
一旦触发扩容,就由该线程完成整个扩容过程,这个过程就会涉及到大量的元素拷贝,效率非常低.
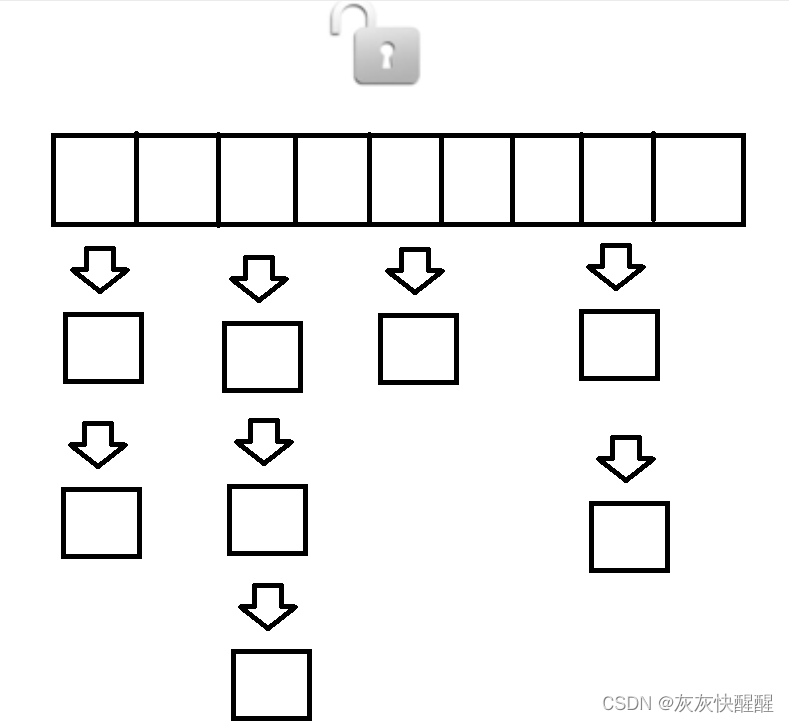
一个HashTable只有一把锁.两个线程访问HashTable中的任意数据都会出现锁竞争.?
我们认为这样的类仍然不好用.我们希望:如果修改两个不同链表上的元素,不涉及线程安全的问题(因为修改的是不同变量).但如果在同一个链表上修改,涉及线程安全问题.操作引用时,就可能涉及到操作同一引用.因此我们在这里引入ConcurrentHashMap.
ConcurrentHashMap
相比于HashTable做出了一系列的改进和优化.它就解决了HashTable出现的部分问题:即针对同一个链表操作再加锁,针对不同链表操作,不必加锁(不要产生锁冲突)->缩小了锁的粒度
下面来看一下详细介绍:
读操作没有加锁(但是使用volatile保证从内存中读取结果),只对写操作进行加锁.加锁的方式仍然是使用synchronized,但是不是锁整个对象,而是"锁桶"(用每个链表的头结点作为锁对象),大大降低了锁冲突的概率.
充分利用了CAS的特性.比如size属性通过CAS来更新.避免出现重量级锁的情况.
优化了扩容方式:化整为零
? ? (1)发现需要扩容的线程,只需要创建一个新的数组,同时搬几个元素过去.
? ? (2)扩容期间,新老数组同时存在
? ? (3)后续每个来操作ConcurrentHashMap的线程,都会参与搬家的过程.每个操作负责搬运一小部分元素
? ? (4)搬完最后一个元素再把老数组删掉
? ? (5)这个期间,插入只往新数组中加.
? ? (6)这个期间,查找需要同时查新数组和老数组.
这种设定,不会产生更多的空间代价.因为java中任何一个对象都可以直接作为锁对象.本身,在哈希表中,就得有数组,数组元素都是存在的(每个链表的头节点),用其做对象加锁即可.
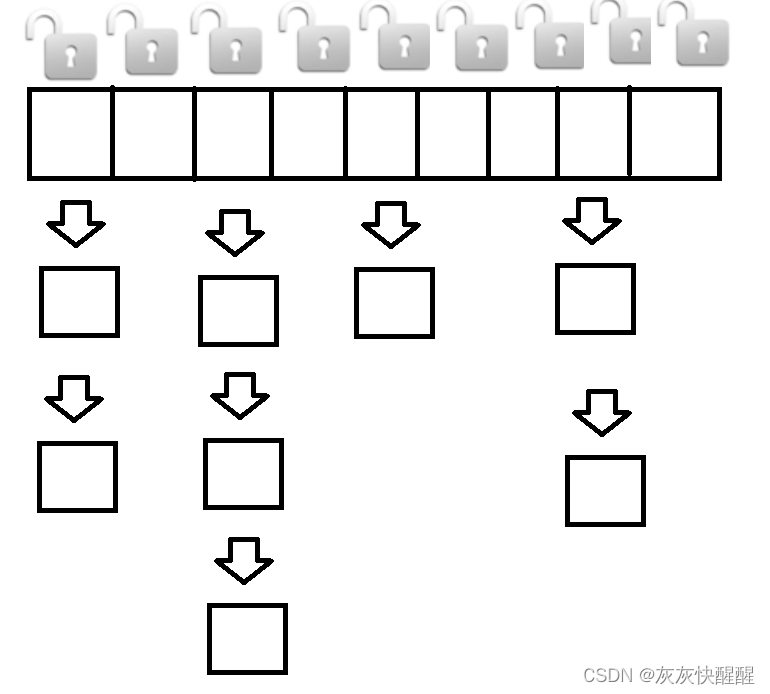 ?
?
ConcurrentHashMap每个哈希桶上都有一把锁.只有两个线程访问的恰好是同一个哈希桶上的数据才出现锁冲突.
相关面试题
1.ConcurrentHashMap的读是否要加锁,为什么?
?读操作没有加锁.目的是为了进一步降低锁冲突的概率.为了保证读到刚修改的数据,搭配了volatile关键字.
2.介绍下ConcurrentHashMap的锁分段技术?
这个是Java1.7所采取的技术.Java1.8中已经不再使用了.简单的说就是把若干个哈希桶分成一个"段"(Segment),针对每个段分别加锁.
目的也是为了降低锁冲突的概率.当两个线程访问的数据恰好在同一个段上时,才会触发锁竞争
3.ConcurrentHashMap在jdk1.8做了哪些优化?
取消了分段锁,直接给每个哈希桶(每个链表)分配了一个锁(就是以每个链表的头节点对象作为锁对象).
将原来的数组 + 链表的实现方式改进成 数组 + 链表 /红黑树的方式.当链表较长的时候(大于等于8个元素)就转换成红黑树.?
4.HashMap和HashTable,ConcurrentHashMap之间的区别?
HashMap: 线程不安全.key允许为null
HashTable:线程安全.使用synchronized锁HashTable对象,效率较低.key不允许设置为null.
ConcurrentHashMap: 线程安全.使用synchronized锁每个链表的头节点,锁冲突概率较低,充分利用CAS机制,优化了扩容方式.key不允许为null.?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java minio 创建bucket
- 海思越影系列3516DV500/3519DV500/3519AV200/SD3403平台的AI一体化工业相机设计思路
- 构建公共场景消防安全,基于YOLOv8【n/s/m/l/x】全系列参数模型开发构建公共消防场景下火点烟雾检测识别系统
- 2024阿里云优惠活动有哪些?
- 力扣hot100 多数元素 摩尔投票
- el-select multiple表单校验问题
- C#,计算几何,鼠标点击绘制 (二维,三次)B样条曲线的代码
- 算法题系列5·移除元素
- C++ 虚函数详解:多态性实现原理及其在面向对象编程中的应用
- 腾讯云优惠券怎样领取?附最新优惠券领取教程