【java八股文】之Redis基础篇
1、Redis有哪几种基本的数据类型
- 字符串类型:用于存储文章的访问量
- Hash:用来存储key-value的数据结构,当单个元素比较小和元素数量比较少的时候 ,底层是用ziplist存储。通常可以用来存储一些对象之类的
- List: 底层采用的quicklist 和 ziplist进行存储的,quicklist就是类似于双端的链表,这样做的好处就是提高存取的效率。通常用作微信公众号的推送消息队列
- Set:底层就是hashtable的value为空的数据结构,通常用作点赞 + 收藏 之类
- ZSet: 底层使用的跳表和字典,调表方便于对排好序的数据查询 , 通常用作类似于微博的热搜
- bitmap:一般用于签到功能或者是统计是否登录的功能上
2、Redis持久化机制
- 快照持久化RDB
在默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。
? redis的默认持久化机制,通过父进程fork一个子进程,子进程可以共享主线程的所有内存数据。bgsave 子进程 运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些数据也都是读操作, 那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那么,这块数据就会被复制 一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程 仍然 可以直接修改原来的数据。
- 追加持久化AOF
? 以日志形式记录每一次的写入和删除操作,策略有每秒同步、每次操作同步、不同步,优点是数据完整性高, 缺点是运行效率低,恢复时间长
3、Redis是单线程吗
redis单线程仅局限于他的网络IO流,和他的键值对读写操作。但是redis对于其他的功能,比如持久化、异步的删除、集群同步等操作,都是额外的线程操作的。
4、为什么Redis单线程还这么快
因为redis所有数据都是在内存中,所有的运算都是内存级别的,而且单线程避免了多线程切换的性能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
5、Redis单线程还能处理那么多的并发客户端连接
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
6、什么是缓存穿透
缓存穿透就是查询到一些不存在的数据,本来缓存层就是为了保护存储层的,而这样直接穿透到存储层就起不到保护的作用。
如何解决:在缓存存这是访问的key 为 一个null的值,并设置一个过期时间。或者提前在接口层做好校验工作
7、什么是缓存击穿
由于大批量的缓存在同一时刻失效,大量请求过来就穿透缓存到达存储层,可能造成存储层压力过大甚至挂掉。
如何解决:设置一个随机的过期时间,而不是同一时刻都过期。或者加上互斥锁。
8、什么是缓存雪崩
缓存雪崩指的是缓存层支撑不住或宕掉后,流量会像奔逃的野牛一样, 打向后端存储层。由于缓存层承载着大量请求, 有效地保护了存储层, 但是如果缓存层由于某些原因不能提供服务(比如超大并发过来,缓存层支撑不住,或者由于缓存设计不好,类似大量请求访问bigkey,导致缓存能支撑的并发急剧下降), 于是大量请求都会打到存储层, 存储层的调用量会暴增, 造成存储层也会级联宕机的情况。
预防和解决缓存雪崩问题:
- 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster。
- 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
- 提前演练。 在项目上线前, 演练缓存层宕掉后, 应用以及后端的负载情况以及可能出现的问题, 在此基础上做一些预案设定。
9、Redis如何实现key的过期删除?
采用的定期过期 + 惰性过期
- 定期删除 :Redis 每隔一段时间从设置过期时间的 key 集合中,随机抽取一些 key ,检查是否过期,如果已经过期做删除处理。
- 惰性删除 :Redis 在 key 被访问的时候检查 key 是否过期,如果过期则删除。
10、缓存与数据库双写不一致
在大并发下,同时操作数据库与缓存会存在数据不一致性问题
1)双写不一致情况
2)读写并发不一致
3)解决方案
- 对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
- 就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
- 如果不能容忍缓存数据不一致,可以通过加读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
- 也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。


11、Redis集群方案
(1)主从模式:多个master节点,多个slave节点,master节点宕机slave自动变成主节点
(2)哨兵模式:在主从集群基础上添加哨兵节点或哨兵集群,用于监控master节点健康状态,通过投票机制选择slave成为主节点
(3)分片集群:主从模式和哨兵模式解决了并发读的问题,但没有解决并发写的问题,因此有了分片集群。分片集群有多个master节点并且不同master保存不同的数据,master之间通过ping相互监测健康状态。客户端请求任意一个节点都会转发到正确节点,因为每个master都被映射到0-16384个插槽上,集群的key是根据key的hash值与插槽绑定
12、Redis集群主从同步原理
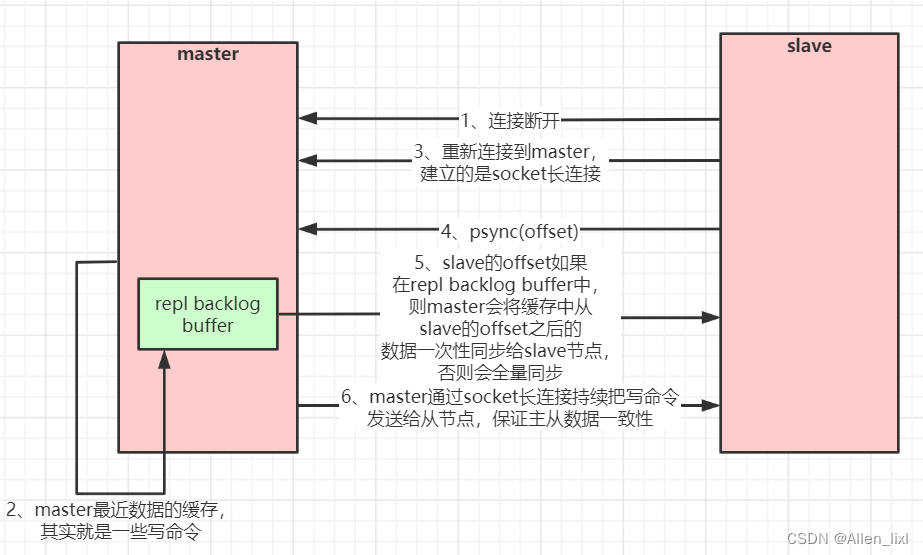
主从同步第一次是全量同步:slave第一次请求master节点会根据replid判断是否是第一次同步,是的话master会生成RDB发送给slave。
主从复制(全量复制)流程图:
后续为增量同步:在发送RDB期间,会产生一个缓存区间记录发送RDB期间产生的新的命令,slave节点在加载完后,会持续读取缓存区间中的数据。
主从复制(部分复制,断点续传)流程图:

13、Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
新master的选举需要大于半数的集群master节点同意才能选举成功,如果只有两个master节点,当其中一个挂了,是达不到选举新master的条件的。
奇数个master节点可以在满足选举该条件的基础上节省一个节点,比如三个master节点和四个master节点的集群相比,大家如果都挂了一个master节点都能选举新master节点,如果都挂了两个master节点都没法选举新master节点了,所以奇数的master节点更多的是从节省机器资源角度出发说的。
14、Redis集群选举原理分析
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
- slave发现自己的master变为FAIL
- 将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
- 其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
- 尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
- slave收到超过半数master的ack后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两个,当其中一个挂了,只剩一个主节点是不能选举成功的)
- slave广播Pong消息通知其他集群节点。
?
?可以查看学习以下关于Redis的博文,希望对您有用。
Redis入门学习笔记【三】Redis淘汰策略-CSDN博客
Redis入门学习笔记【五】Redis在分布式环境下常见的应用场景_redis与分布式id的运用场景-CSDN博客
Redis入门学习笔记【六】如何解决 Redis 的并发竞争Key问题_redis中的key并发获取-CSDN博客
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【python】生成器是什么?
- 关于搭建Devops平台的高级运维面试题
- centos7 安装nnDetection环境
- 美客多本土店与跨境店有何区别?本土店如何入驻运营?
- 线程和进程的区别
- 聊聊PowerJob的HttpProcessor
- Microsoft Copilot Android App已经发布
- Java 实现微信扫码登录方法(提供前端及后端核心代码)
- 【漏洞复现】Kubernetes PPROF内存泄漏漏洞(CVE-2019-11248)
- 【FPGA】分享一些FPGA视频图像处理相关的书籍