最左前缀法则
概念
- 最左前缀法则是针对于复合索引而言的,也就是说一个索引有多个字段
- 那么索引的查询从最左列开始,并且不跳过索引的列,如果跳过索引中的某一列,那么,会导致索引部分失效(跳过列之后的索引失效)
- 如果出现了范围查询(>,<),那么会导致索引列后的索引失效
栗子
建表
CREATE TABLE IF NOT EXISTS `article` (
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT(10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL,
`views` INT(10) UNSIGNED NOT NULL,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES
(1, 1, 1, 1, '1', '1'),
(2, 2, 2, 2, '2', '2'),
(1, 1, 3, 3, '3', '3');
SELECT * FROM article;
例题一
查询 category_id 为1 且 comments 等于 1 的情况下,views 等于1 article_id
没有索引
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments =1 AND views = 1;
查询的执行结果为
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | article | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
我们可以看到他的执行计划,type为all,也就是全表扫描
复合索引
这个时候我们新建一个索引
CREATE INDEX idx_article_ccv ON article(category_id,comments,views);
全值匹配
再次执行
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments =1 AND views = 1;
执行计划为
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | article | NULL | ref | idx_article_ccv | idx_article_ccv | 12 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------------+------+----------+-------+
我们可以看到这次的type是ref,走的索引为idx_article_ccv,也就是我们刚刚新建的索引,索引的长度为 12
and顺序
我们把执行的sql改为
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND views = 1 AND comments =1 ;
我们可以发现他的执行计划一点没有变,也就是说与and的顺序无关
去掉views
我们去掉查询字段views,执行sql语句
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments =1;
执行计划如下
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | article | NULL | ref | idx_article_ccv | idx_article_ccv | 8 | const,const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------------+------+----------+-------+
我们可以看到结果key_len变成了8,没有全部走索引的列,能得出view的key_len为4
去掉views和comments
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 ;
执行计划为
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | article | NULL | ref | idx_article_ccv | idx_article_ccv | 4 | const | 2 | 100.00 | NULL |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------+
我们会发现他的key_len变成了4,也就是说能得出view的key_len为4,comments的key_len为4,category_id key_len也为4
上面的查询完全根据最左前缀,没有跳过索引中的列
例题二
以例题一为基础,我们跳过一个索引列,
中间列
跳过comments的这个列进行查询
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND views = 1;
执行计划如下
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | article | NULL | ref | idx_article_ccv | idx_article_ccv | 4 | const | 2 | 33.33 | Using index condition |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-----------------------+
我们会发现他的key_len为4,也就是说只走了最左列的category_id 这个索引列
跳过最左列
跳过category_id 查询,我们运行下面的sql
EXPLAIN SELECT id,author_id FROM article WHERE comments =1 AND views = 1;
执行计划为
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | article | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------------+
我们会发现他完全再走全表扫描
例题三
范围查询,以例题一为基础,查询comments大于1的
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND views = 1 AND comments > 1 ;
执行计划如下
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | article | NULL | range | idx_article_ccv | idx_article_ccv | 8 | NULL | 1 | 33.33 | Using index condition |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
我们会发现他的key_len为8,views的索引列失效了,这个范围查询导致了索引的失效,但是我们只要把>加上一个等号,就会发现views索引可以使用了
EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND views = 1 AND comments >= 1
执行计划如下
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | article | NULL | range | idx_article_ccv | idx_article_ccv | 12 | NULL | 2 | 33.33 | Using index condition |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+-----------------------+
原理
数据库中的索引是以Btree来进行存放的,其特点是定位高效、利用率高、自我平衡,特别适用于高基数字段,定位单条或小范围数据非常高效。
理论上,使用Btree在亿条数据与100条数据中定位记录的花销相同。
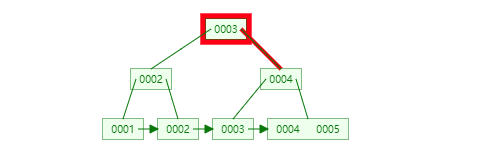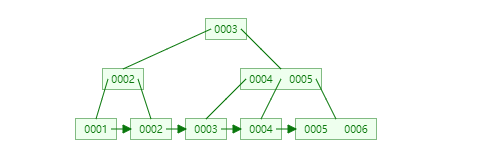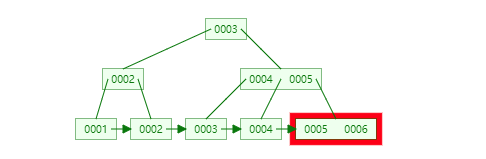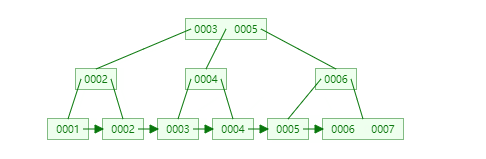
如下为插入数据的过程
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 抖音直播间爆品如何打造培训教程课件
- 我的应用我做主:扩展线程池
- 【网络工程师】三层交换机与HSRP
- 基于ssm线上学习网站论文
- 算法与数据结构--哈夫曼树与哈夫曼编码
- 基于Springboot的宠物领养系统(有报告)。Javaee项目,springboot项目。
- RockyLinux默认镜像源替换成阿里镜像源
- 内存泄漏检测组件的实现
- 给程序加个进度条吧!1行Python代码,快速搞定~
- paramiko 、netmiko抛出 No existing session的解决方法。