机器学习_8、支持向量机
发布时间:2024年01月11日
?支持向量机解决鸢尾花数据集分类问题
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
iris_data = load_iris()
X=iris_data.data
y=iris_data.target
# 划分训练集与测试集
from sklearn.model_selection import train_test_split
# 让参数stratify=y,使测试集与训练集中各类别样本数量的比例与原数据集中
# 各类别的样本数量比例相同
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.1,stratify=y,random_state=5)
# 特征数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train) # 从训练集中学习标准化参数
X_train_std = scaler.transform(X_train)
# 测试集特征数据的标准化也要使用训练集的标准化模型
X_test_std = scaler.transform(X_test)
# 创建并训练分类线性支持向量机模型
from sklearn.svm import SVC
model = SVC(C=1.0, kernel="linear", class_weight='balanced',
decision_function_shape="ovr", #采用一对其余策略
probability=True, random_state=0)
model.fit(X_train_std, y_train) #用标准化后的特征数据训练模型
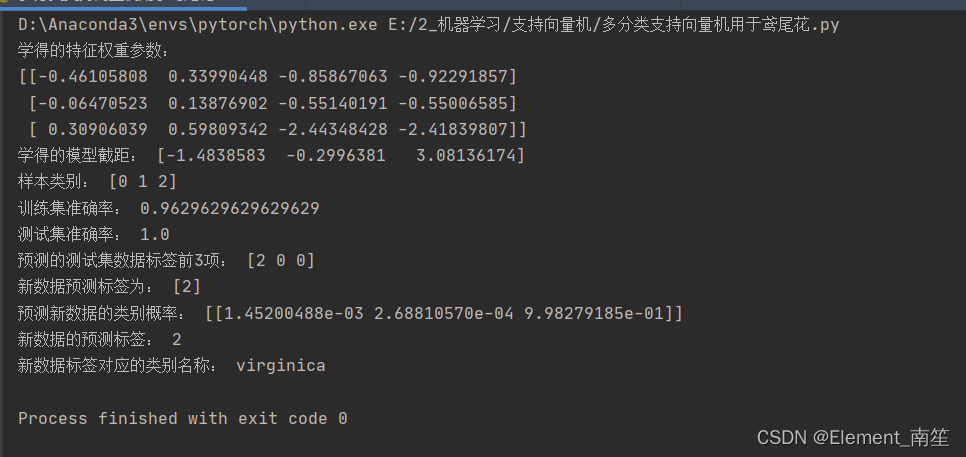
print("学得的特征权重参数:\n",model.coef_, sep="")
print("学得的模型截距:",model.intercept_)
print("样本类别:",model.classes_)
# 性能评估
print("训练集准确率:", model.score(X_train_std, y_train))
print("测试集准确率:", model.score(X_test_std, y_test))
# 预测测试集数据
y_test_pred = model.predict(X_test_std)
print("预测的测试集数据标签前3项:",y_test_pred[:3])
# 预测新数据
X_new = np.array([[8, 2.6, 6.5, 2.1]])
X_new_std = scaler.transform(X_new)
y_new = model.predict(X_new_std)
print("新数据预测标签为:",y_new)
y_new_proba = model.predict_proba(X_new_std)
print("预测新数据的类别概率:", y_new_proba)
# 最大概率对应的标签序号
y_new_label_local = np.argmax(y_new_proba)
y_new_label = model.classes_[y_new_label_local]
print("新数据的预测标签:", y_new_label)
print("新数据标签对应的类别名称:", iris_data.target_names[y_new_label])
文章来源:https://blog.csdn.net/cfy2401926342/article/details/135538660
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!