大数据-hive函数与mysql函数的辨析及练习-将多行聚合成一行
发布时间:2024年01月10日
目录
1. 🥙collect_list: 聚合-不去重
将组内的元素收集成数组 不会去重
2. 🥙collect_set(col): 聚合-去重
函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生 Array 类型字段。
//创建一张实验用表,存放用户每天点播视频的记录
create table t_visit_video (
username string,
video_name string
) partitioned by (day string)
row format delimited fields terminated by ',';
//创建visit.txt数据文件
张三,大唐双龙传
李四,天下无贼
张三,神探狄仁杰
李四,霸王别姬
李四,霸王别姬
王五,机器人总动员
王五,放牛班的春天
王五,盗梦空间
//导入数据
load data local inpath '/opt/testDemo/visit.txt' into table t_visit_video partition (day='20180516');
?1)按用户分组,取出每个用户每天看过的所有视频的名字(不去重)
select username,collect_list(video_name)
from t_visit_video
group by username;结果:
 2)按用户2)分组,取出每个用户每天看过的所有视频的名字(去重)
2)按用户2)分组,取出每个用户每天看过的所有视频的名字(去重)
select username,collect_set(video_name)
from t_visit_video
group by username;结果:

3. 🥙mysql的聚合函数-group_concat
GROUP_CONCAT([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator ‘分隔符’])
将结果集中的多行结果连接成一个字符串
-- group_concat对于收集的字段只能是string,varchar,char类型
--当不指定分隔符的时候,默认使用 ','//创建一张实验用表,存放用户每天点播视频的记录
create table t_visit_video (
username varchar(20),
video_name varchar(20)
);
//插入数据
insert into t_visit_video values
('张三','大唐双龙传'),
('李四','天下无贼'),
('张三','神探狄仁杰'),
('李四','霸王别姬'),
('李四','霸王别姬'),
('王五','机器人总动员'),
('王五','放牛班的春天'),
('王五','盗梦空间');
3)按用户分组,取出每个用户每天看过的所有视频的名字(不去重)
select username,group_concat(video_name)
from t_visit_video
group by username;结果:

?4)按用户分组,取出每个用户每天看过的所有视频的名字(去重)
select username,group_concat(distinct video_name)
from t_visit_video
group by username; 5)按用户分组,取出每个用户每天看过的所有视频的名字(去重,用;分割视频名字)
5)按用户分组,取出每个用户每天看过的所有视频的名字(去重,用;分割视频名字)
select username,group_concat(distinct video_name separator ';')
from t_visit_video
group by username;结果:

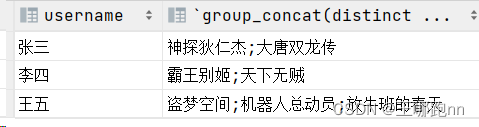
6)按用户分组,取出每个用户每天看过的所有视频的名字(去重,用;分割视频名字,并将视频名字按照字典顺序降序排序)?
select username,group_concat(distinct video_name order by video_name desc separator ';')
from t_visit_video
group by username;结果:
4. leetcode练习题
文章来源:https://blog.csdn.net/weixin_40968325/article/details/135499220
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TypeScript 基础知识:类型兼容性
- Google Earth Engine(GEE)——如何将写好的代码块引入到新的脚本中
- DOS命令
- Flink窗口API、窗口分配器和窗口函数
- VMware虚拟化——开启ssh登录ESXI
- 恢复.EKING勒索病毒加密数据:数据安全的必备知识
- Python 猎户星空Orion-14B,截止到目前为止,各评测指标均名列前茅,综合指标最强;Orion-14B表现强大,LLMs大模型
- 从董宇辉小作文风波,我们普通人能学到些什么?
- Oracle11g登录方法
- 从来如此,便对么-UMLChina建模知识竞赛第5赛季第2轮