PEFT(高效微调)方法一览
PEFT论文解读2019-2023
本文旨在梳理2019-2023关于大模型高效微调的经典方法总结,如有遗漏的重要方法烦请告知,不胜感激
全参数微调(FFT) VS 参数高效微调(PEFT)
全参数微调的问题:
- 消费级显卡的全参数微调在时间上和硬件上不可行
- 全参数微调会损失多样性,出现灾难性遗忘,且下游部署、维护繁琐
高效微调:
- 冻结大部分预训练参数,仅仅更新一部分参数使得模型获得更好的能力
- 主要的方法包括:引入额外参数、选取部分参数
2019-Adapter Tuning
Parameter-Efficient Transfer Learning for NLP
故事:
- 当预训练模型的规模较大时,为每一个下游任务进行全参数微调会耗费很多计算资源和时间
- 研究表明fine-tuning比feature-base-transfer的效果要好(fine-tuning是保证模型结构的完整,针对下游任务,利用特定数据进行参数微调的过程;而feature-base-transfer则是保留预训练的embedding比如word、sentence,paragraph,然后将其迁移到其他任务中)
- 同时全参数微调的fine-tuning容易出现知识遗忘的问题(原文中写的是multi-task和continual learning会出现这种情况)
方法:
- 为了解决上述问题,本文提出了一种adapter-tuning的方法,通过添加adapter的方式来进行参数的部分更新,从而达到减少参数更新但是得到和FFT相competitive的效果
- 具体来说就是针对每个下游任务,给预训练模型添加两个adapter,一个添加在MHA投影之后,一个添加在两个前馈层后,两个adapter都添加在残差连接之前(如果在残差连接之后呢?)
- adapter的结构:两个前馈子层构成,将输入降维再升维,一般降维的维度m较小,所以adapter的参数量不会很大,同时其也具有skip connection结构,这样添加好处在于,adapter参数初始化接近0时,如果adapter起不到优化作用,其参数不更新(接近0)时不会损害原模型的能力
细节:
- 以BERT为backbone,在17个数据集上进行广泛的实验
- 参数微调时,只调整adapter和LN的参数
- Adapter 最佳的中间层特征维度m视数据集的大小而异
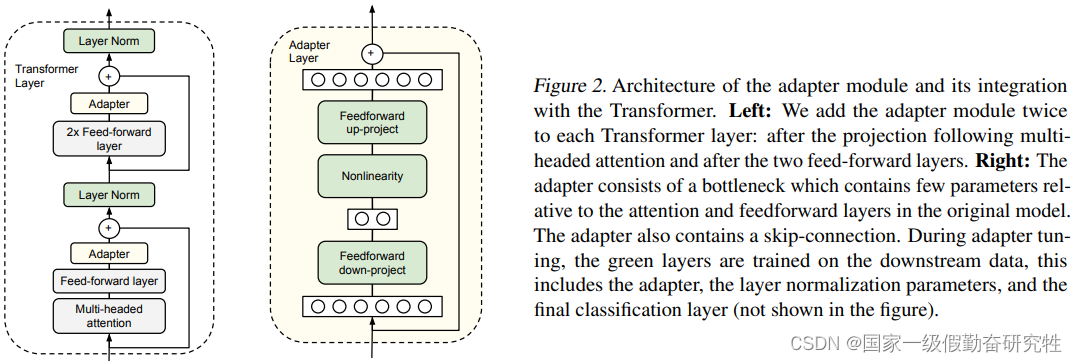
结果:通过引入adapter-tuning可以在仅仅调整5%以内的参数与FFT的结果相媲美

2019-PALs
BERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning
故事:
- 如何使得一个模型可以适配多个下游任务
方法:
- 提出PALs通过并行的参数添加来完成下游任务的适配
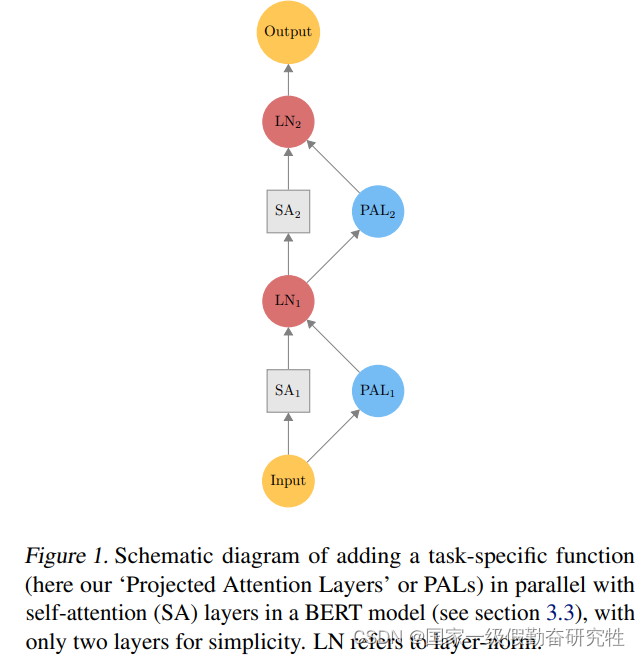
- 不同Bert在模型的上方加入参数来适配下游任务,PALs通过并行参数更新:
h l + 1 = L N ( h l + S A ( h l ) + T S ( h l ) ) \mathbf{h}^{l+1}=\mathrm{LN}(\mathbf{h}^l+\mathrm{SA}(\mathbf{h}^l)+\mathrm{TS}(\mathbf{h}^l)) hl+1=LN(hl+SA(hl)+TS(hl))
T S ( h ) = V D g ( V E h ) \mathrm{TS}(\mathbf{h})=V^{D}g(V^{E}\mathbf{h}) TS(h)=VDg(VEh)
- TS就是添加的并行参数模块
细节:
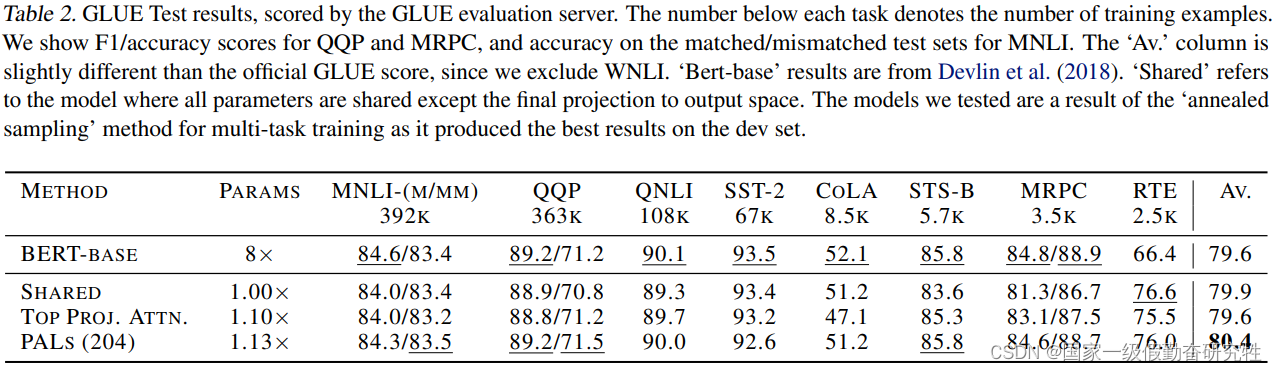
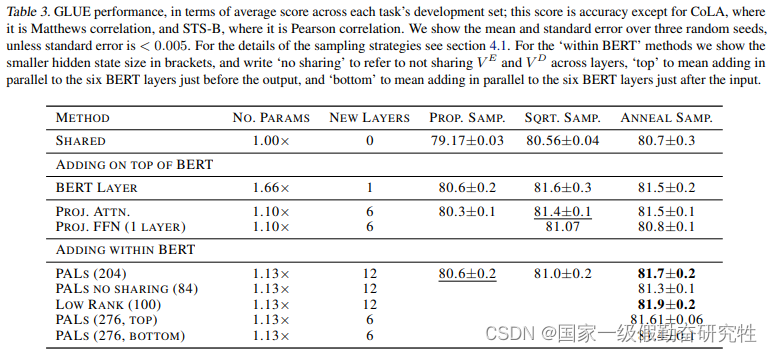
- 在GLUE的八个NLU任务上利用Bert进行实验
- 关于g函数的形式,作者实验了以下几种:
- 恒等映射(low-rank layers)
- MHA
- MHA+在不同层间共享 V E V^E VE和 V D V^D VD的参数(PALs)
- MLP+不同层间共享 V E V^E VE和 V D V^D VD的参数
结果:
- 实验可知serial connection(顺序连接)的效果比不添加任何adapter的效果还差(可能是添加了新初始化的LN所导致)
- 并行连接可以使得基础模型不容易丢失存储的知识
2020-Adapter-Fusion
AdapterFusion: Non-Destructive Task Composition for Transfer Learning
故事:
- sequential fine-tuning和multi-task learning存在遗忘和数据平衡的挑战。想在一个模型上实现多任务的信息共享有两种方法:sequential fine-tuning的数据训练顺序很重要,容易出现遗忘的风险;multi-task learning任务数据的大小和质量存在挑战( these models often overfit on low resource tasks and underfit on high resource tasks.)
- 而adapter-tuning方法仅仅提供了adapter的插入来解决全参数微调难以训练和知识遗忘的问题,而并没有将每个任务下游adapter收集的信息利用最大化,从而解决信息共享,下游通用,数据顺序的问题。
方法:
- 提出一个两阶段的迁移训练方法:首先在知识抽取阶段利用各下游任务训练adapter,然后在知识整合阶段将训练好的adapter通过adapterFusion进行信息共享。
- 提出一个adapter-fusion模块用于融合各adapter学习到的信息
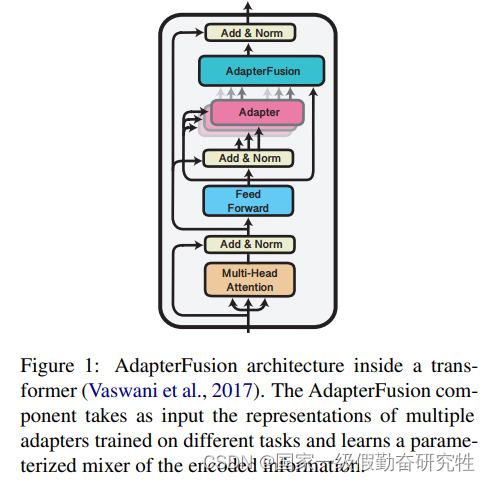
细节:
- 训练数据集会被使用两次:训练下游任务的adapter时和训练信息融合的adapter-fusion模块
- 以Bert为backbone,知识抽取阶段更新adapter的参数,知识融合阶段更新adapter-fusion的参数
- adapter-fusion模块直接添加到adapter后面,其本质是一个attention计算过程。Q是进入adapter前的输入,而K,V则是adapter的输出
- 第一阶段的训练方法分为两种:ST-A(一个任务使用一个adapter),MT-A(多个任务使用一个adapter联合优化)
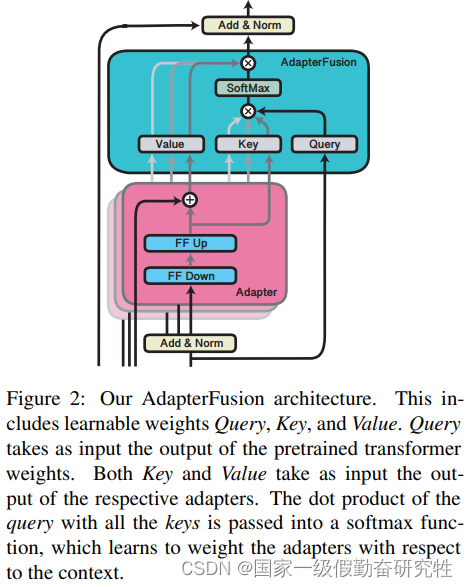
结果:
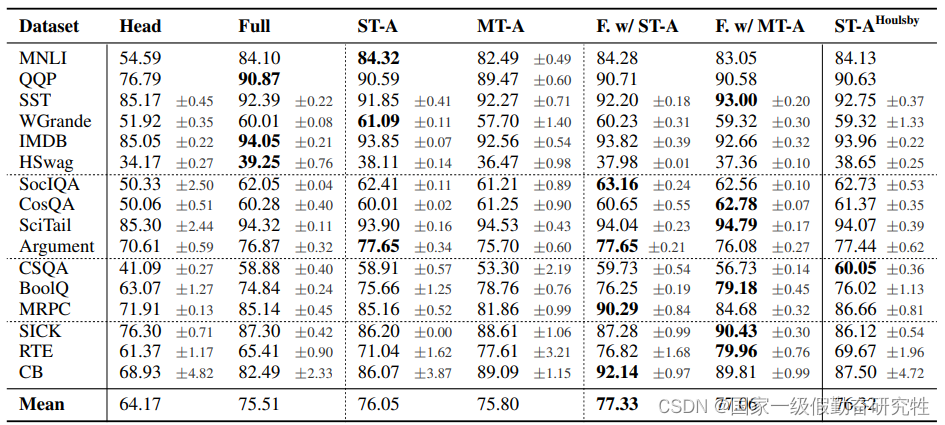
- Head:采用Bert中提到的分类头
- Full:全参数微调
- ST-A:单任务-adapter
- MT-A:多任务-adapter
- F.w/ST-A:ST-A + adapter-fusion
- F.w/MT-A:MT-A+adapter-fusion
- ST-A-Houlsby:adapter-Tunning的方法
2021-Adapter-Drop
AdapterDrop: On the Efficiency of Adapters in Transformers
故事:
- adapter参数的有效性并没有被充分发掘,存在参数冗余
方法:
- 提出adapterDrop, 对adapter和adapter-fusion进行参数优化(adapter的丢弃),但是不损害性能
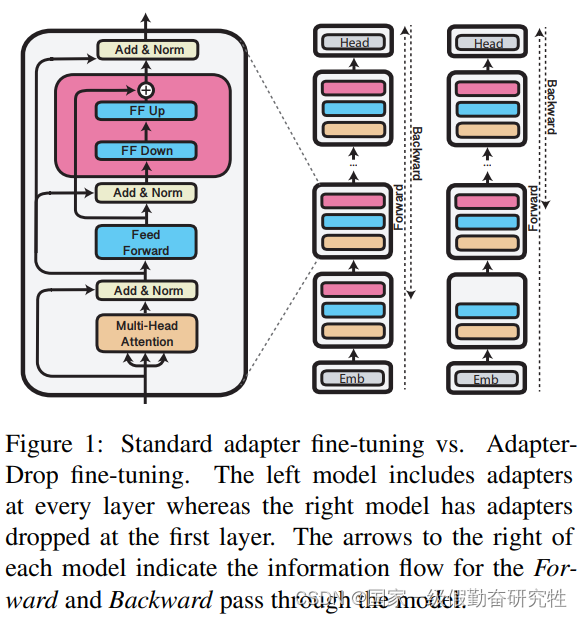
细节:
- 对于adapter而言,采用两种方法进行删减:第一种是从输入的transformer layer开始删除n个模块的adapter;另外一种是随机的删除n个模块
- 对于adapter-fusion而言,希望在inference推理时有更好的速度,两种删除方法:其一是删除整个AF结构;其二是删除重要性最小的adapter,使其不参与AF中的计算
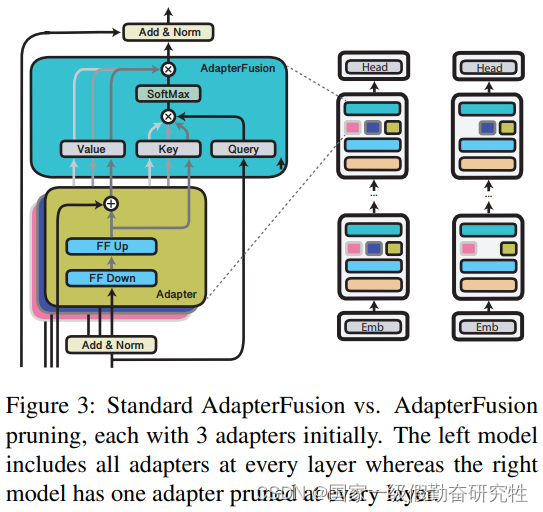
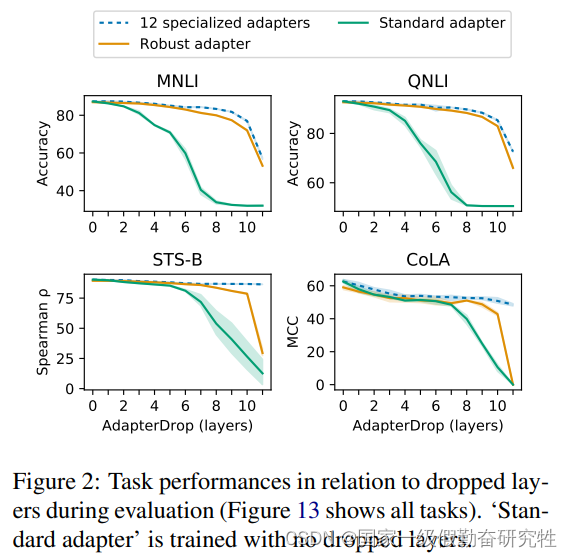
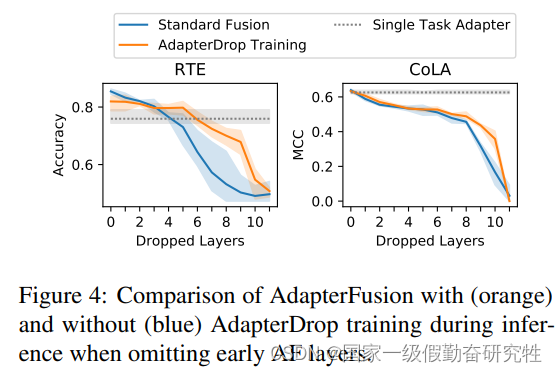
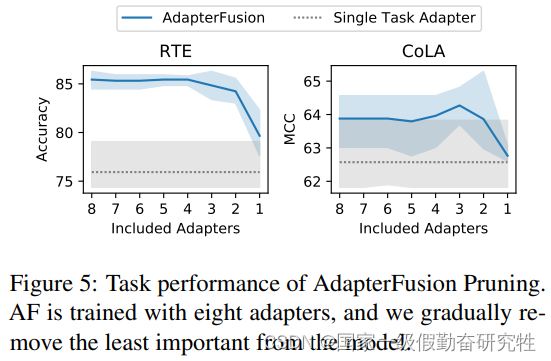
结果:
- 引入adapter后,与全量微调相比,训练快了60%,推理慢了4-6% (引入了额外的参数导致推理变慢是正常的现象)
- 删除底层transformer中的几个adapter可以加速推理并不损害task performance
- 对adapter-fusion的的删除以及adapter输入的剪枝也可以有效的提高推理速度,并获得较好的推理和训练性能
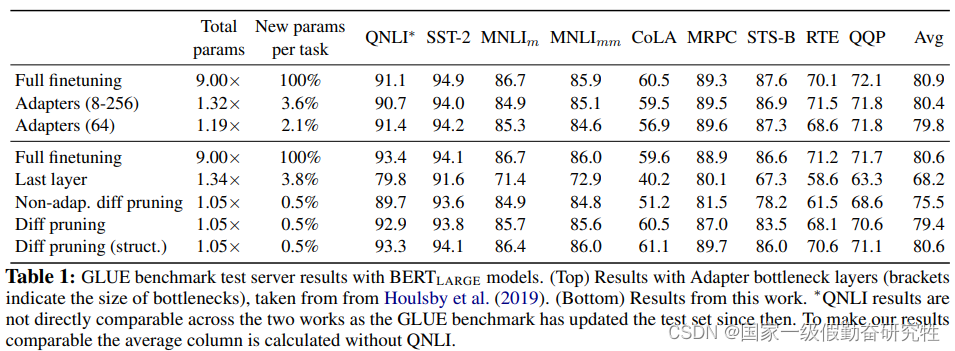
2021-Diff-Pruning
Parameter-Efficient Transfer Learning with Diff Pruning
故事:
-
希望不修改原模型的体系结构,通过特定任务的difference vector来扩展模型,提升下游任务性能
-
通过学习神经网络权重的稀疏更新来实现高效参数迁移
方法:
- 提出diffPruning:在权重上引入一个可学习的二值掩码,掩码参数在模型微调期间学习,作为正则化目标的一部分,它是更新向量的L0范数的可微逼近
- 但是这种方法比传统微调需要更多的内存,除了可学习的二值掩码外,训练期间还涉及优化所有参数
δ τ = z τ ⊙ w τ , z τ ∈ { 0 , 1 } d , w τ ∈ R d \mathbf{\delta}_\tau=\mathbf{z}_\tau\odot\mathbf{w}_\tau,\quad\mathbf{z}_\tau\in\{0,1\}^d,\mathbf{w}_\tau\in\mathbb{R}^d δτ?=zτ?⊙wτ?,zτ?∈{0,1}d,wτ?∈Rd
这里的 δ τ \mathbf{\delta}_\tau δτ?表示添加的diff vetor
由于其与其他PEFT相比涉及优化所有参数,在当前的模型规模下并不常用,所以这里细节不展开赘述
结果:
2021-Prefix-Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation
故事:
- 受prompt启发,模型对prompt比较敏感,在GPT-2, BART中想让prompt发挥作用需要精巧的设计,费时费力
- 一般的fine-tuning方法需要多次拷贝参数和重新训练整个transformer,计算开销大
- 所以想要一种soft-prompt方法可以真正通过参数来”引导“模型往下游任务上靠

方法:
- 提出了prefix-tuning, 在token前面加上prefix token,冻结住模型的参数,仅仅更新这部分prefix token的参数, 起到一个"提示任务"的作用, 从而在改善模型在下游任务的表现
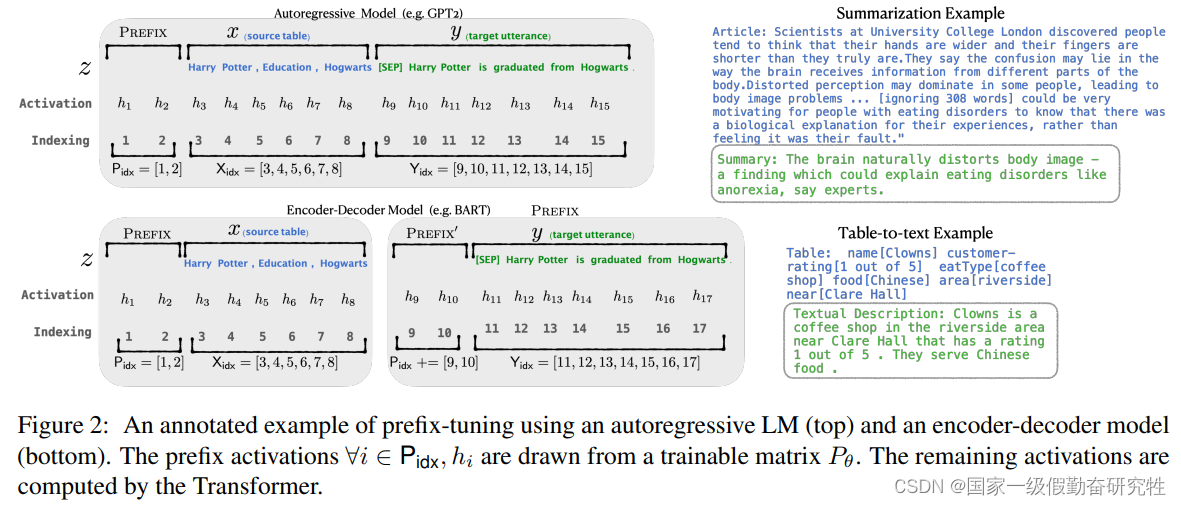
细节:
- 针对encoder-decoder架构,会在encoder的输入和decoder的输入embedding都加上prefix token
- 消融实验中对比了embedding-only和infix的效果,可以发现embedding-only和infix(virtual token加在embedding的中间)的效果并不好
- 由于训练的不稳定性,会在prefix token层前加上一层MLP来稳定训练,训练完成后会移除MLP
- 由消融实验embedding-only的结果进行改进,在所有layer的输入层都加上prefix token效果会更好
结果:
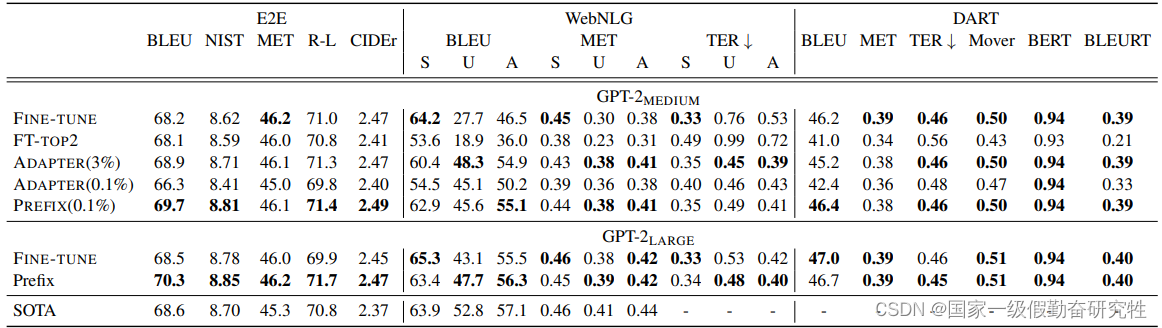
2021-Prompt-Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning
故事:
- 模型参数的进一步增加(GPT-3),使得全参数微调十分消耗资源,而prompt在GPT-3上表现出较好的效果
- 所以希望通过soft prompt的方法,使得在大模型上可以做高效的微调
方法:
- 可以看作prefixes-tuning的简化版本,移除了稳定训练所需要的MLP,仅仅在输入层添加prompt tokens
- 另外提出了一种prompt-ensemble的方法,通过对同一任务施加不同的prompt进行训练来达到集成的效果,大大减小了模型集成的开销
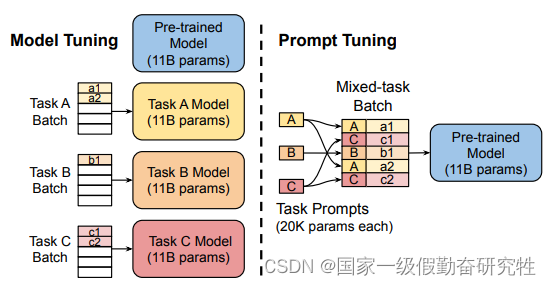
细节:
- 利用T5作为backbone
- 消融实验探究了prompt token的三种初始化方式(random,embedding from model’s vocabulary, embedding that enumerate the output classes ),第三种会更好,但是large scale will close the gap
- 三种T5的训练设置(normal, with sentinel, LM adaptation)
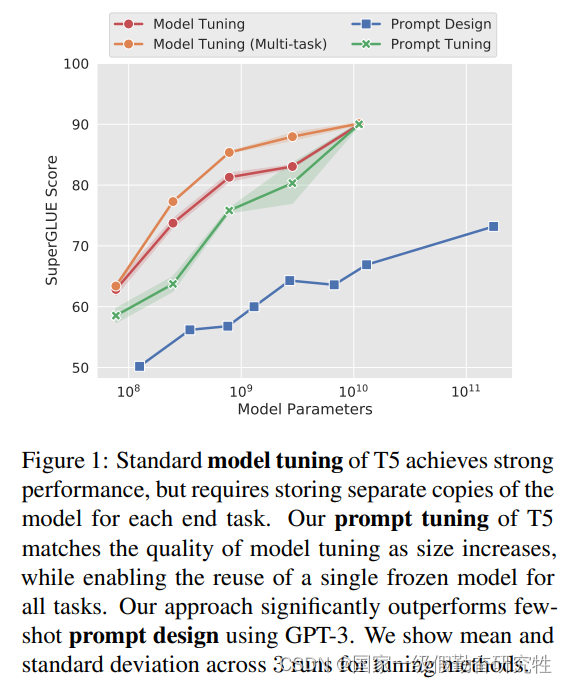
结果:
- 在模型足够大时(GPT-3 175B),prompt-tuning可以达到全参数微调的效果
2021-WARP
WARP: Word-level Adversarial ReProgramming
故事:
- 当前适配下游任务方法分为FFT, adapter, prompt,但是当前的prompt的能力需要在较大的模型上才能展现
- 文章由《Adversarial Reprogramming of Neural Networks》得到启发:给图形加入对抗性的扰动会使得分类效果得到提升。所以文章提出了WAPR来给模型加入word-level的扰动使得模型可以更好的适配下游任务
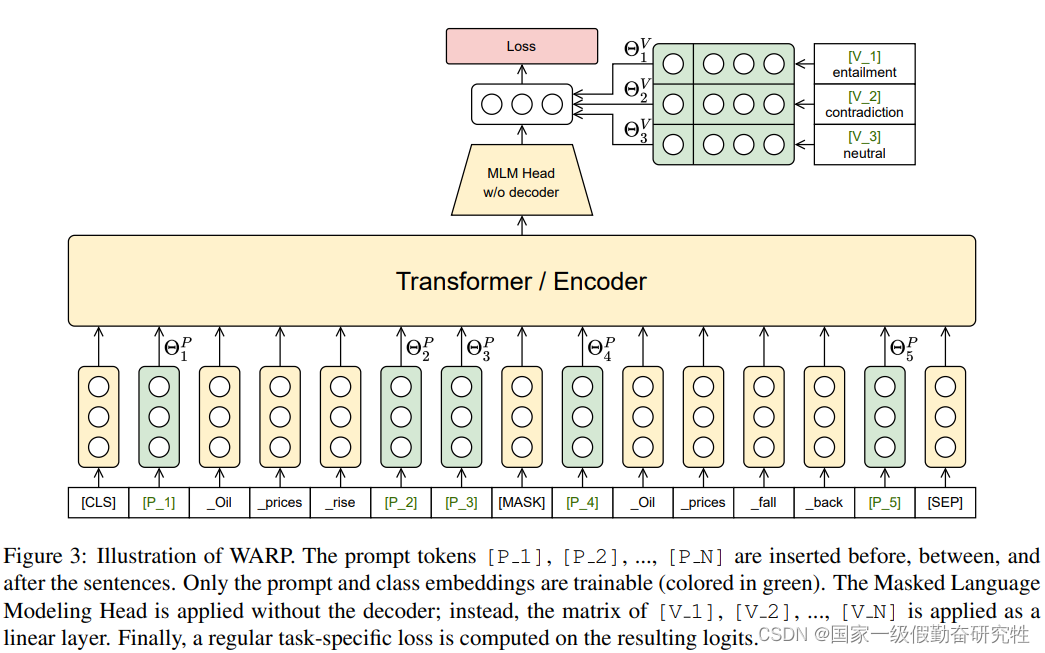
方法:
- 希望在prompt中加入扰动(P_i)使得模型的输出更好
- 在输入层插入特殊的prompt token(P_i)并且这些token的位置和数目都是可变的
- 在分类头上也加入verbalizer token(V_i)来和输出计算交叉熵损失
- 微调过程中仅更新P_i, V_i
细节:
- 使用Roberta-large完成GLUE, 使用alert-xxlarge-v2完成few-shot任务(FewGLUE, SuperGLUE)
- prompt token的初始化方法有两种:[MASK]的词嵌入或者word embedding layer的向量
- WAPR可以结合人类精细设计的discrete prompt使得下游任务效果更好
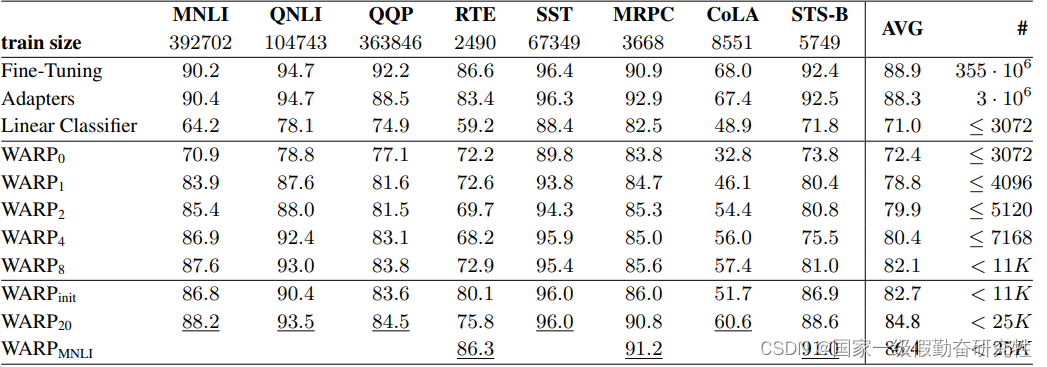
结果:
- GLUE
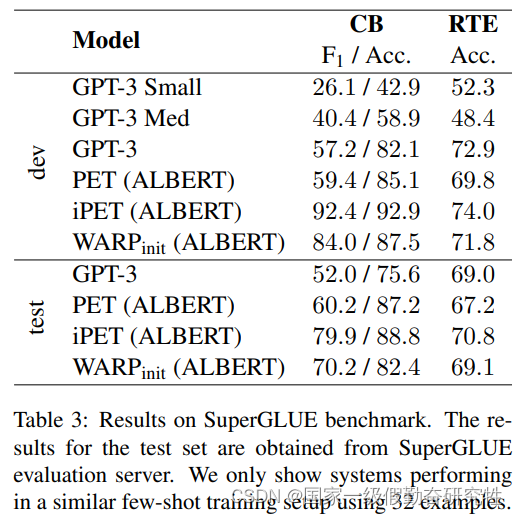
- few-shot
2021-LoRA
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
故事:
- 现有的一些方法比如adapter会存在inference latency的副作用,prompt tuning的优化十分困难等问题
- 且现有的方法大部分都要需要做效率和性能的trade off
- 而模型中的权重矩阵大部分是满秩的,Aghajanyan et al.(2020) 等人提出,预训练的语言模型具有较低的“内在维度”,所以即使投影到较小的子空间也可以有效的学习,所以文章假设权重的更新过程也具有低秩的特性,从而提出了LoRA,通过更新两个低秩矩阵的参数来间接更新原矩阵的参数
方法:
- 通过低秩分解的方法来模拟参数的改变,训练好的A,B矩阵权重直接加和就完成更新
- 并且LoRA可以和其他的peft方法结合(比如prefix-tuning)
h = W 0 x + Δ W x = W 0 x + B A x h = W_0x+\Delta{W}x=W_0x+BAx h=W0?x+ΔWx=W0?x+BAx
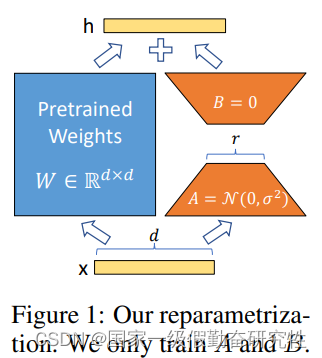
细节:
- A, B矩阵分别用于降维和升维,中间维度为 r r r,而 r r r可以非常小,叫做intrinsic rank,从而大大较少训练的参数量
- 训练完成后直接右边+左边完成参数更新后,可以直接舍弃右边的结构,所以推理的成本不会提高
- 而A由高斯函数初始化,B初始化为0,则BA=0,保证了其不会损害模型的能力
- LoRA主要应用在K, Q, V, 还有MHA的多头参数上
- 模型base:Roberta-base-large-XXL, GPT-2-M-L, GPT-3-175B
- 方法baseline:包括了adapter-tuning, adapterDrop, prefix-tuning, prompt-tuning, bitfit(2021年放到arxiv, 2022中的ACL, 所以目录上bitfit时间比LoRA晚)
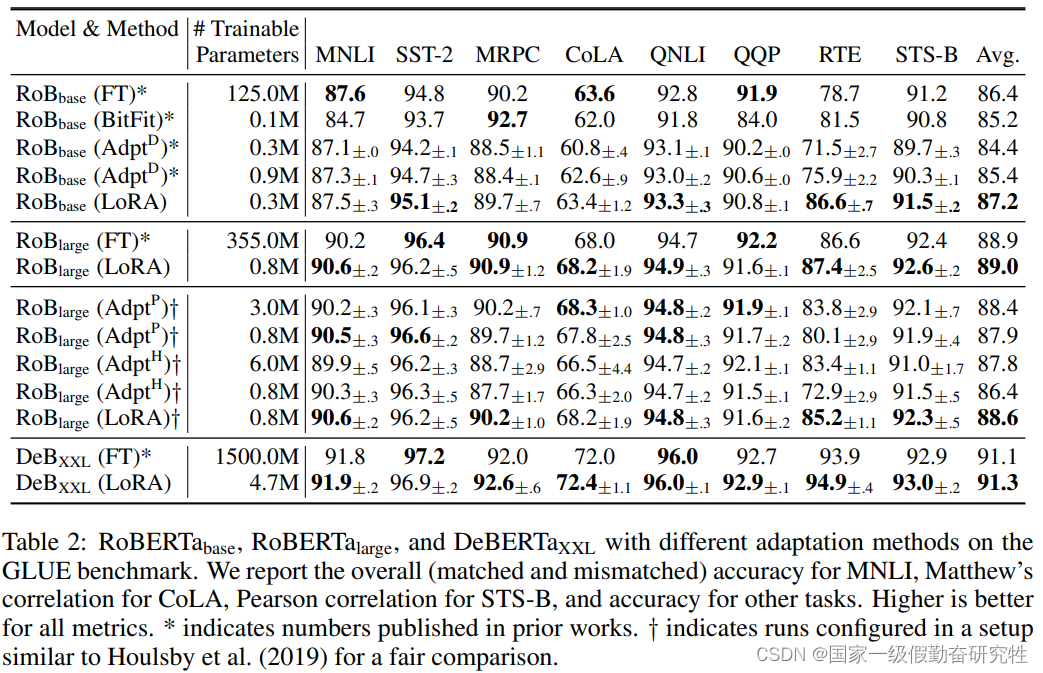
结果:(比较多,这里只放了一个基于Roberta的)
- 结果还包含对LoRA使用位置,不同模型,不同 r r r的影响等实验
2021-P-Tuning
GPT Understands, Too
故事:
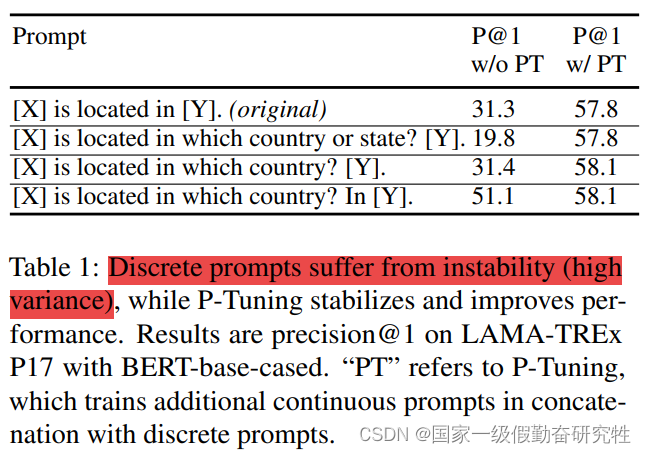
- discrete prompt非常sensitive,构造方式的细微差异都会使得性能的大幅度波动
方法:
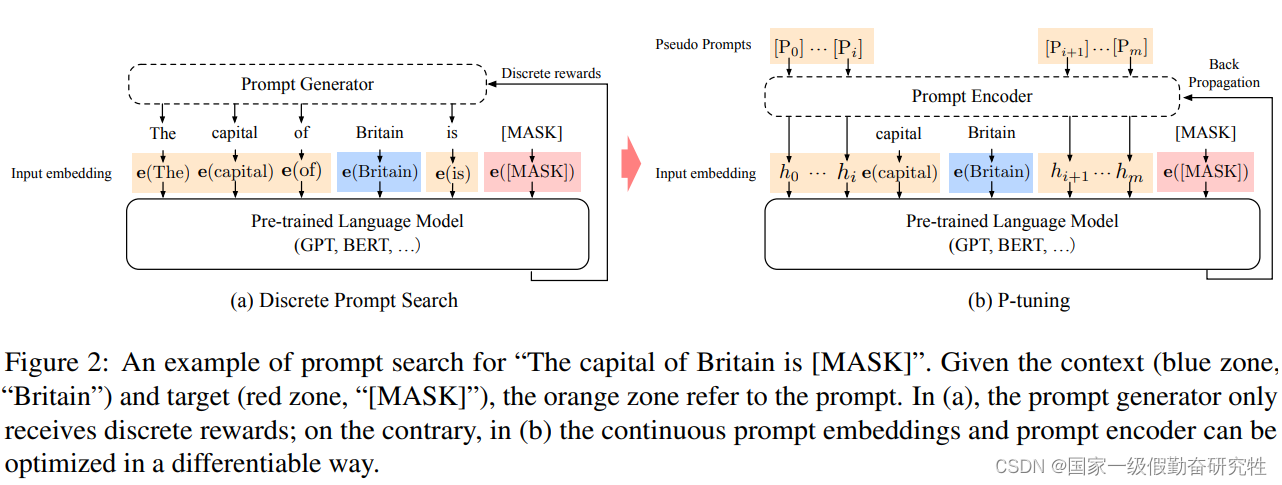
- 为了解决discrete prompt的不稳定性,提出一种P-Tuning的方法来进行soft prompt(和Prompt-Tuning类似),与prefix-tuning的区别在于,prefix-tuning注重生成任务,而P-Tuning注重理解任务NLU
- 具体来说,就是通过一个prompt encoder来对prompt进行编码和对齐(encoder采用LSTM或者MLP)
细节:
- 想法和prompt-tuning类似(同期工作),prompt-tuning论文中提到了P-Tuning
- 和prefix-tuning的不同还在于其prompt插入的位置不局限于prefix,并且仅仅在输入层添加,没有在所有的子层添加
- 本质上利用prompt encoder是为了对virtual token(soft prompt)做词嵌入空间上的alignment,使得其更加适配下游任务(个人观点,欢迎批评指正)
结果:
- P-Tuning可以取得与全参数微调相媲美的结果,并且效果远好于manual prompt
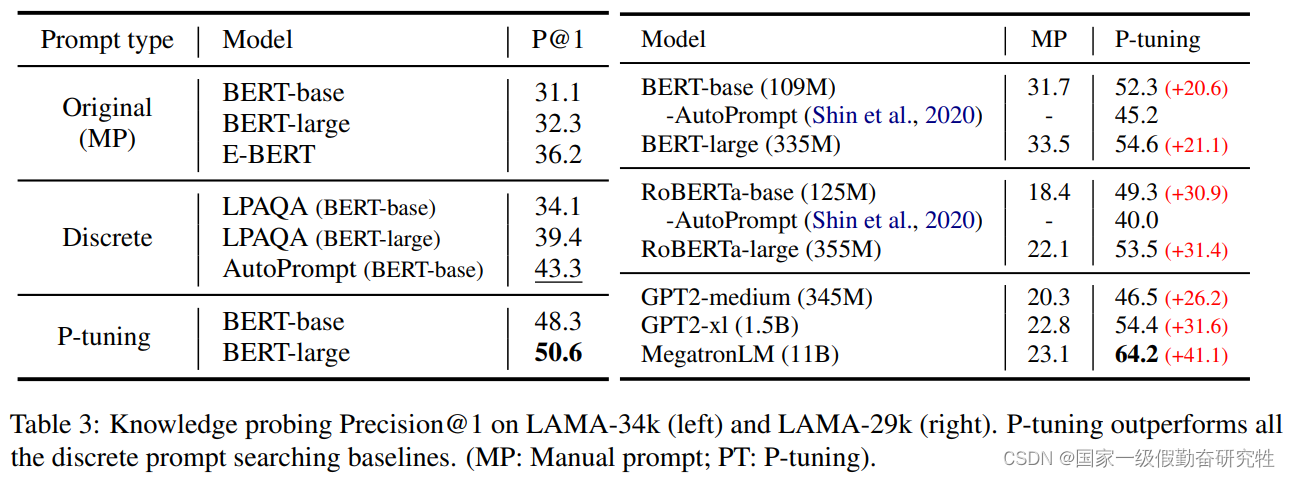
2021-P-Tuning-V2
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
故事:
- P-Tuning和prompt-tuning存在两个问题:对于正常规模的模型效果不好(10B以下的);对于序列标记任务表现不佳
- 而仅在输入层进行prompt tuning会有两个挑战:由于序列长度的限制,参数量较少;由于仅在输入的embedding上进行调整,对模型最终的预测没有直接影响
- 所以结合了prefix-tuning(文中称为deep prompt-tuning)+ P-Tuning,针对上述挑战和问题提出了P-Tuning-V2
方法:
- 每一层都加入prompts token作为prefix,冻结预训练的权重,微调时仅更新这些prefix,解决参数少和无法深度影响模型预测输出的两个挑战
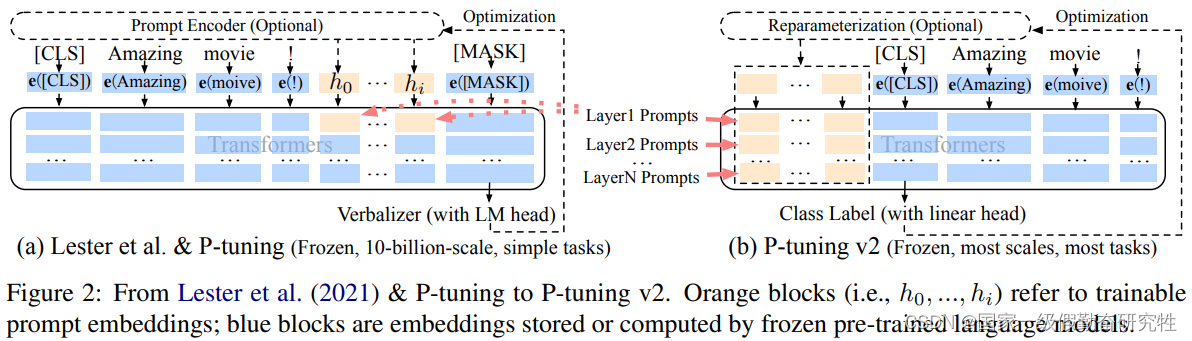
细节:
- 针对前人工作做了以下改进: (表中列出了对比)
- Reparameterization(重参数化)的操作(利用MLP, LSTM来提高prompt token训练的稳定性)仅在一些数据集和任务上有效,在某些任务甚至会掉点,所以进行了移除
- prompt的长度很关键,通常不同的NLU任务需要不同的长度来得到最佳性能,通常来说任务越难,prompt的长度越长(简单分类任务的提示长度小于20,序列标注任务的最佳提示长度在100左右)
- 多任务学习的引入:在针对单任务做fine-tuning时,可以先用multi-task learning来做多任务的prompt训练,效果会更好
- 重新使用传统的CLS分类头来识别序列标注
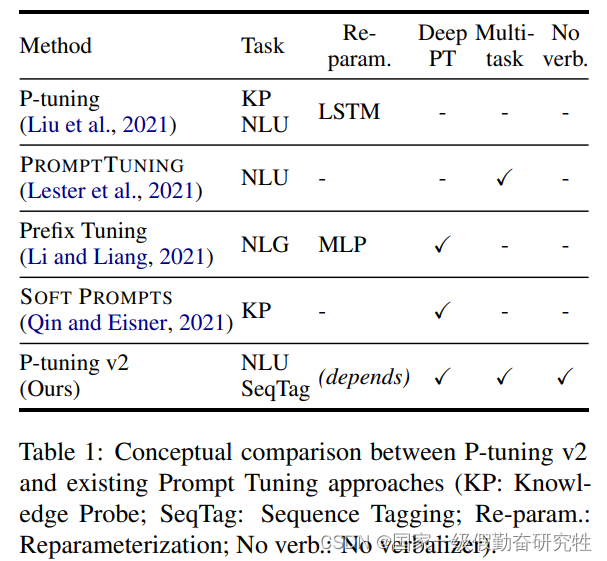
结果:
- 可以看到P-Tuning-V2在不同规模的模型和不同任务上都可以取得较好的结果
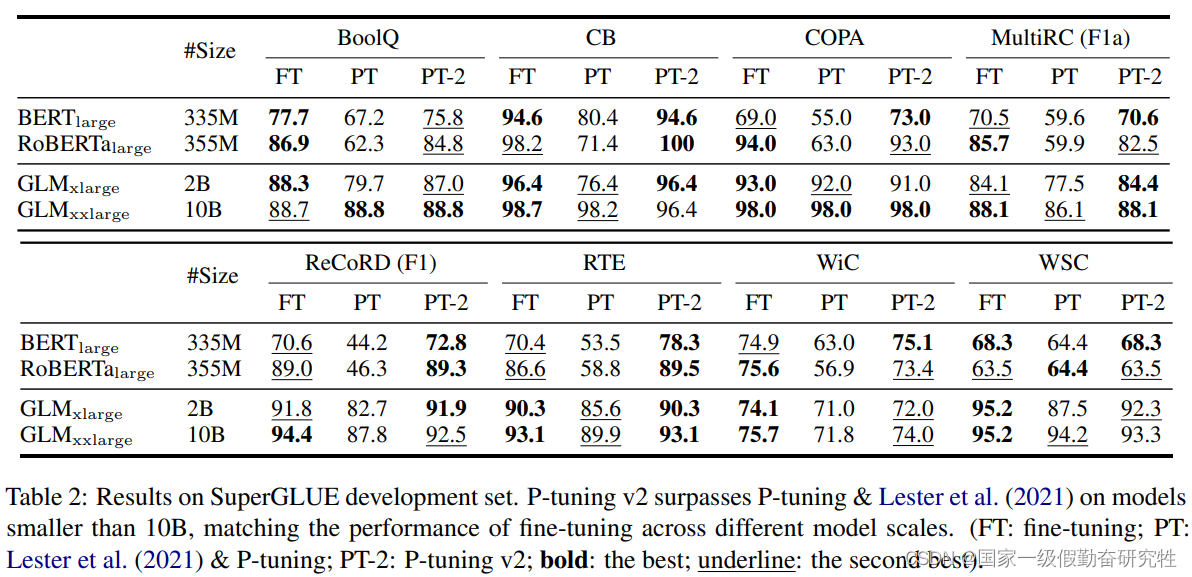
2022-BitFit
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
故事:
- 微调的问题在于研究者无法判断出哪部分参数的变化导致了结果的上升
- 而现有的adapter方法由于需要引入新参数,则为了适配下游任务,需要维护多个模型
- 并且本文还提出假设:微调的作用在于引导模型暴露其在预训练中所拥有的能力,而不是新能力的学习
方法:
- 冻结encoder的大部分参数,仅微调bias-term和task-specific classification layer
细节:
- bias包括K, Q, V,MLP层, layer norm层
- 也可以仅仅query和the second MLP Layer也可以在一些任务上匹敌FFT的效果
- 基于Bert-base, Bert-large, Roberta
结果:
- bitfit可以在微调0.08%-0.09%参数的情况下取得和全参数微调相当甚至超越的效果
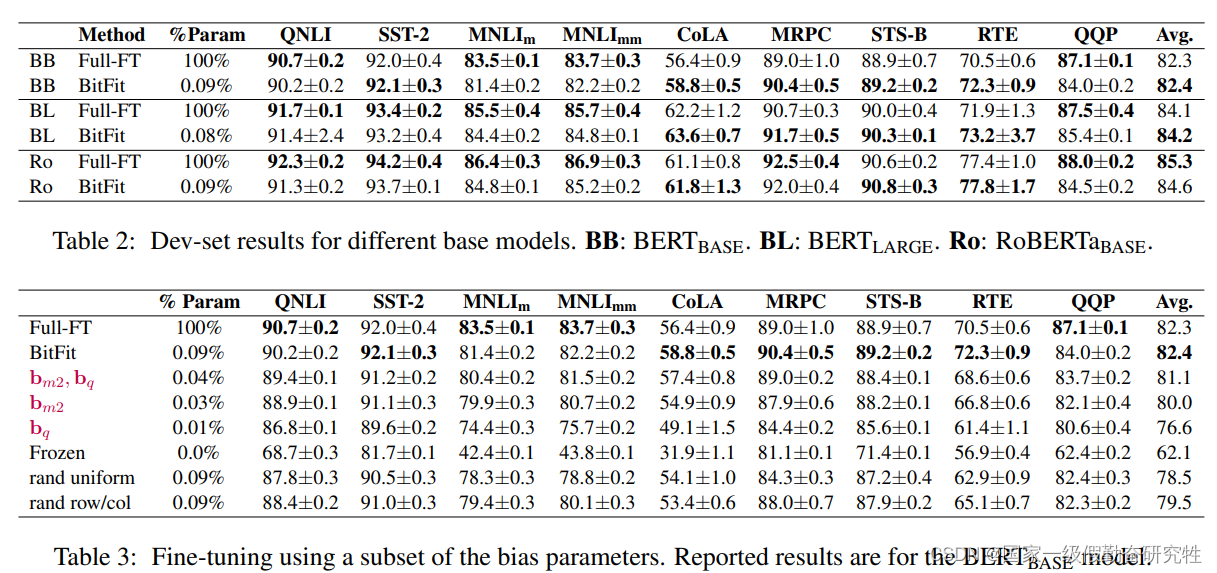
2022-MAM-Adpater
TOWARDS A UNIFIED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING
故事:
- peft可以在调整少量参数的情况下得到和FFT想媲美的结果
- adapter, prefix-tuning, Lora这些方法通常可以通过不到原模型1%的参数调整得到媲美FFT的效果
- 但是文章作者认为,促成这些方法成功的原因以及联系仍然不清楚,所以作者想要回答三个问题:
- 这些方法的联系是什么?
- 这些方法成功的关键是否有共通的地方?
- 是否可以结合这些方法的得到更有效的方法?
- 总结了三种方法的公式:
A d a p t e r : h ← h + f ( h W d o w n ) W u p Adapter:h\leftarrow h+f(h\boldsymbol{W_\mathrm{down}})\boldsymbol{W_\mathrm{up}} Adapter:h←h+f(hWdown?)Wup?
p r e f i x ? t u n i n g : head ? i = Attn ? ( x W q ( i ) , concat ? ( P k ( i ) , C W k ( i ) ) , concat ? ( P v ( i ) , C W v ( i ) ) ) prefix-tuning:\operatorname{head}_{i}=\operatorname{Attn}(\boldsymbol{xW}_{q}^{(i)},\operatorname{concat}(\boldsymbol{P}_{k}^{(i)},\boldsymbol{CW}_{k}^{(i)}),\operatorname{concat}(\boldsymbol{P}_{v}^{(i)},\boldsymbol{CW}_{v}^{(i)})) prefix?tuning:headi?=Attn(xWq(i)?,concat(Pk(i)?,CWk(i)?),concat(Pv(i)?,CWv(i)?))
L o R A : h ← h + s ? x W d o w n W u p LoRA:h\leftarrow h+s\cdot xW_\mathrm{down}W_\mathrm{up} LoRA:h←h+s?xWdown?Wup?
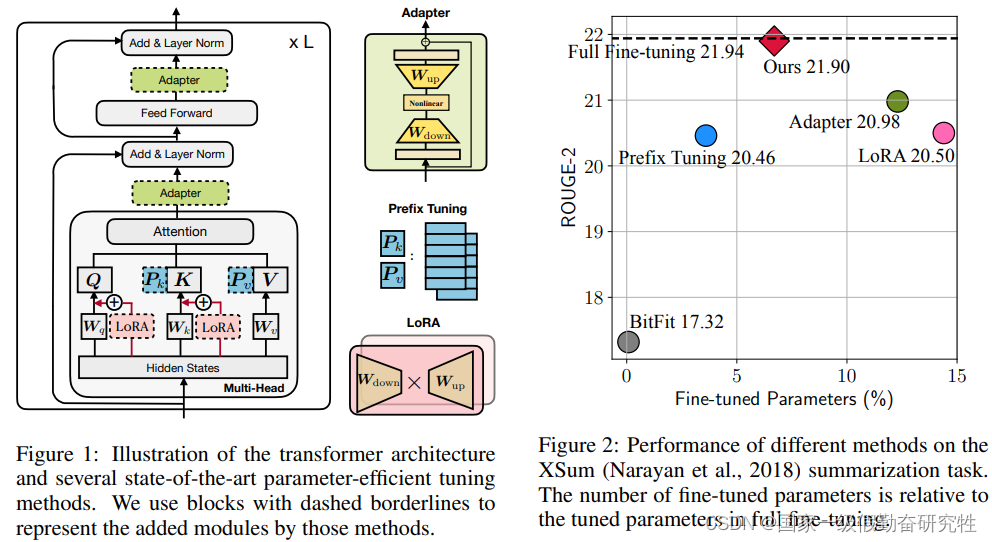
方法:
- 通过公式推导的方法发现prefix-tuning和adapter的关系, 其中 W 1 = W q P k ? , W 2 = P v , f = s o f t m a x \boldsymbol{W}_{1}{=}\boldsymbol{W}_{q}\boldsymbol{P}_{k}^{\top},\boldsymbol{W}_{2}{=}\boldsymbol{P}_{v},f{=}\mathrm{softmax} W1?=Wq?Pk??,W2?=Pv?,f=softmax
h ← ( 1 ? λ ( x ) ) h + λ ( x ) f ( x W 1 ) W 2 \boldsymbol{h}\leftarrow(1-\lambda(\boldsymbol{x}))\boldsymbol{h}+\lambda(\boldsymbol{x})f(\boldsymbol{xW}_1)\boldsymbol{W}_2 h←(1?λ(x))h+λ(x)f(xW1?)W2?
- 根据与这三种方法的区别和联系,作者设计了parallel adapter和scaled parallel adapter(scaled PA)
- 提出MAM-Adapter,一种结合了三种peft的框架
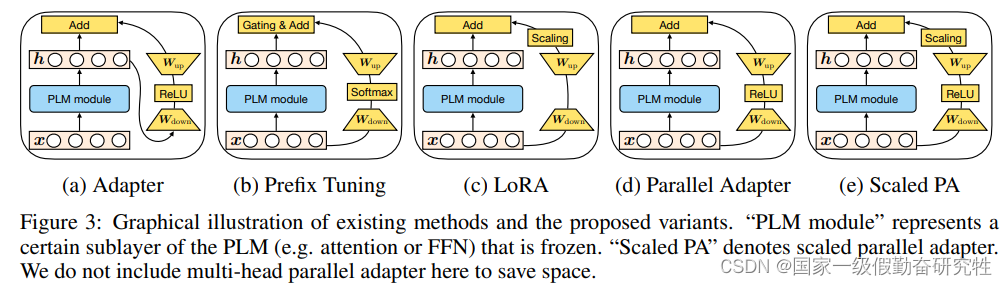
细节:(Table 1是几种方法的总结,包括公式,插入形式,插入位置)

- parallel adapter通过将prefix-tuning的并行插入与adapter结合后得到的新架构
- scaled PA则是结合了PA和LoRA
- 通过实验可以得到以下结论:
- scaled PA是修改FFN的最佳方法
- 修改head attention只需要0.1%的参数就可以work
- FFN较大时可以取得更好的微调效果
- 所以MAM-Adapter的组件(mix-and-match)
- 在注意力层和FFN层都使用scaled PA
结果:
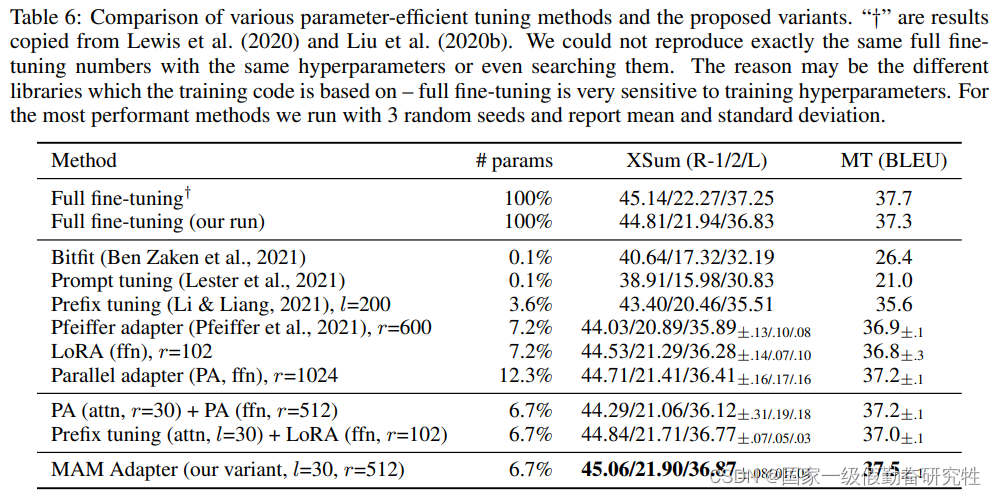
2022-UniPELT
UNIPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
故事:
- 不同的PELT方法在同一任务上执行的结果会大相径庭,所以需要为特定任务选取特定的PELT方法,但是种类繁多的PELT方法和任务使得选择成为一个难题
- 所以引入UniPELT框架,通过门机制来集成adapter,prefix-tuning,LoRA方法,使得模型自动激活合适的PELT方法
方法:(图中蓝色部分为微调过程中需要调整的参数模块)
- 在transformer架构中集成prefix-tuning、adapter,LoRA三种方法并分别通过门控来控制激活程度
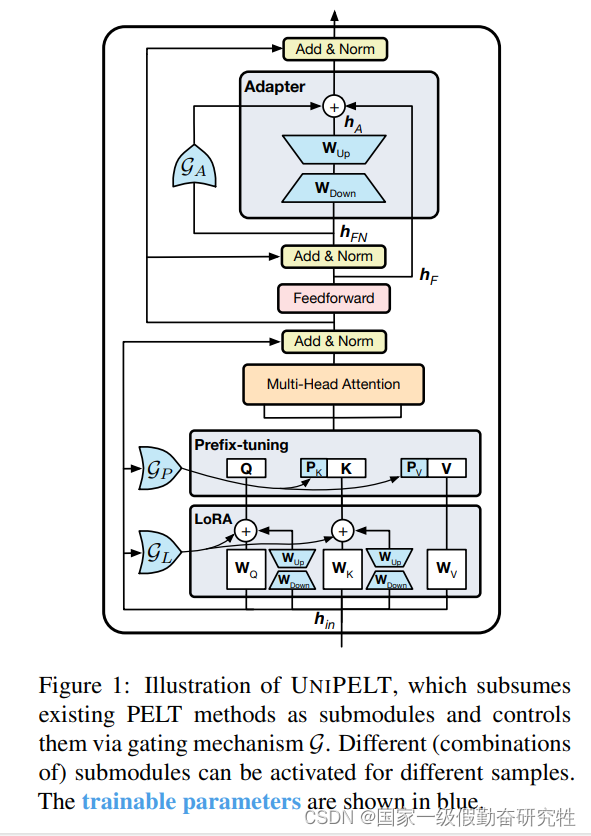
细节:
- 可以观察到不同的PELT方法适配的任务不同,比如prefix-tuning在NLI任务表现良好并且与训练数据大小无关
- 并且不同的PELT方法集成在模型的不同位置,比如prefix-tuning在MHA之前,adapter在FFN之后,方便组合
- 值得注意的是LoRA自带了缩放因子α,所以使得其可学习即可
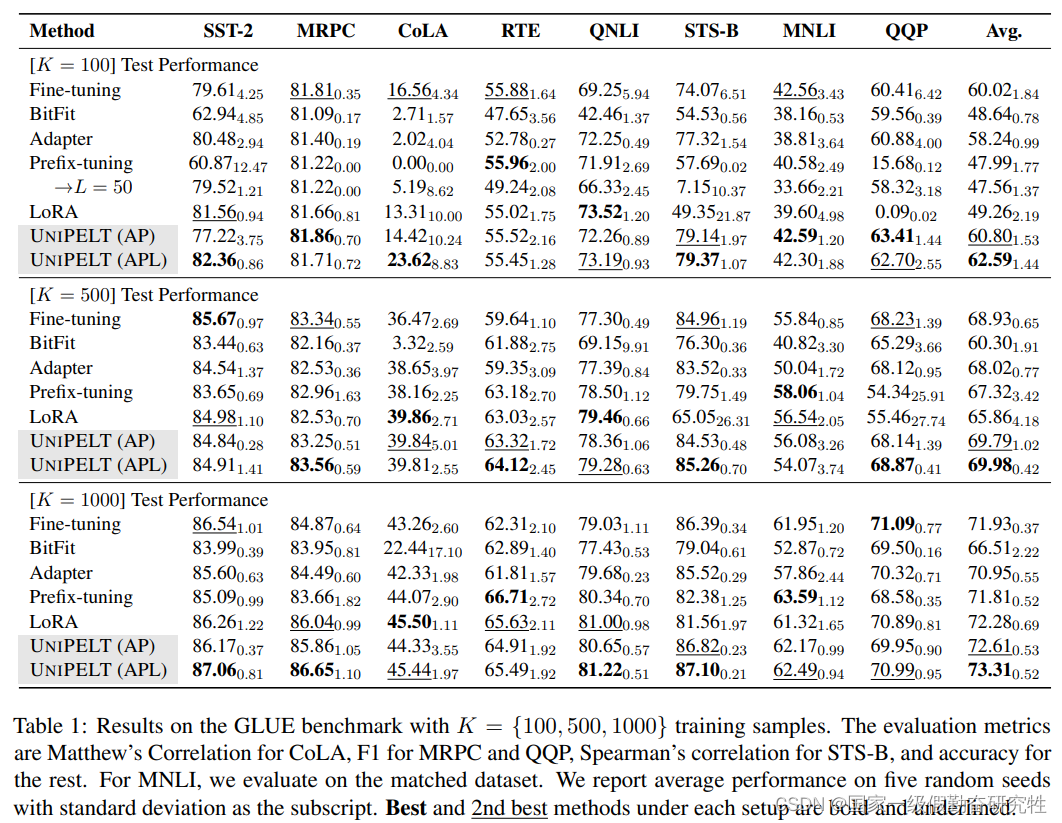
- 模型基于Bert-base和Bert-large
结果:
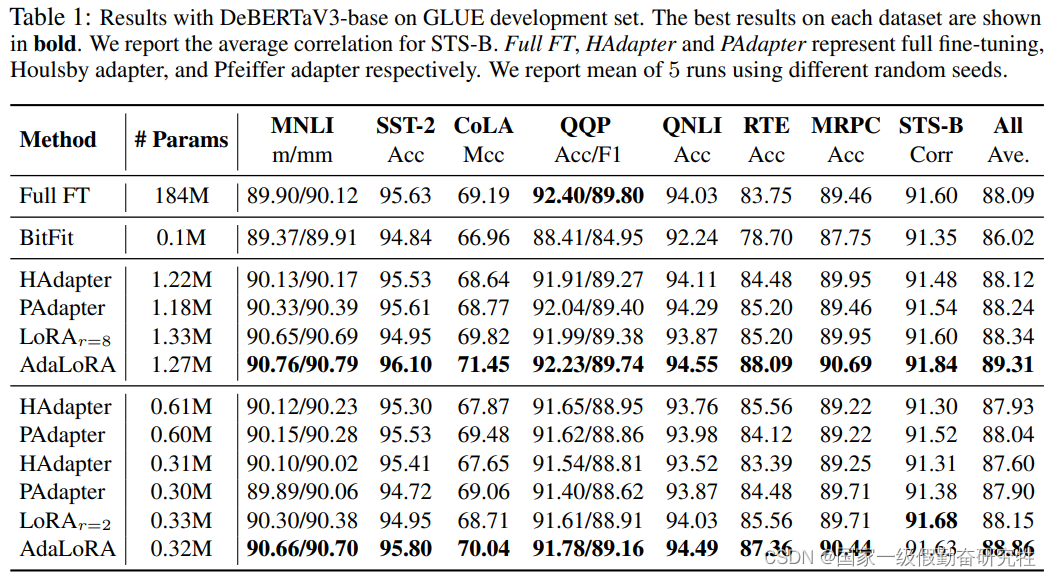
2023-AdaLoRA
ADALORA: ADAPTIVE BUDGET ALLOCATION FOR PARAMETER-EFFICIENT FINE-TUNING
故事:
- 传统的LoRA会均匀的更新所有的权重矩阵,而忽略了不同权重参数的重要性,而造成结果是次优的(suboptimal)
- 现今的peft的两个方向:添加额外的网络模块(比如adapter, prompt-tuning)和不改变原模型结构的增量更新的微调方式(比如bitfit, diff-pruning, lora)
- 但是adapter方法会使得推理速度下降,prompt-tuning或者prefix-tuning的方式很难调优;
- diff-pruning需要底层实现加速非结构化的稀疏矩阵的计算,在无法直接使用当前的框架的,其次训练过程中需要存储完全的矩阵,与全参数微调的计算成本相似
- LoRA的问题在于,向重要的权重矩阵加入更多可训练的参数可以提高模型性能,但是向那些不重要的,或者说不需要调优的权重矩阵添加更多参数无法得到较大的优化,甚至损害性能
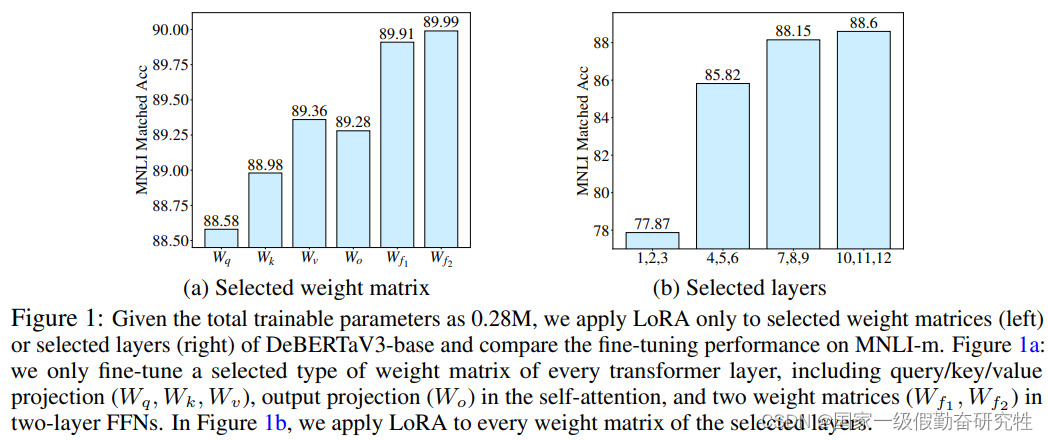
图1可以看到选择不同的权重矩阵,或者不同transformer层的权重矩阵都会对模型的性能有较大的影响
所以本文想要解决的问题:
How can we allocate the parameter budget adaptively according to importance
of modules to improve the performance of parameter-efficient fine-tuning?
方法:
- 基于奇异值分解(SVD)的AdaLora,将增量矩阵以奇异值分解的形式表达
- 基于设计的importance-aware rank allocation方法,来裁剪冗余的奇异值,从而减少计算开销
W = W ( 0 ) + Δ = W ( 0 ) + P Λ Q W=W^{(0)}+\Delta=W^{(0)}+P\Lambda{Q} W=W(0)+Δ=W(0)+PΛQ
细节:
- 基于 DeBERTaV3-base 和 BART-large
- 基于任务NLU:GLUE, QA : SQuADV1, SQuADV2, NLG : XSum, CNN/DailyMail
- 为了正则化PQ的正交性,在损失中添加一个额外的惩罚,避免SVD的密集计算。此外该方法的另外一个优点就是保证奇异值向量的同时,可以去掉不重要的奇异值。为未来保留了回复的可能性,并稳定了训练
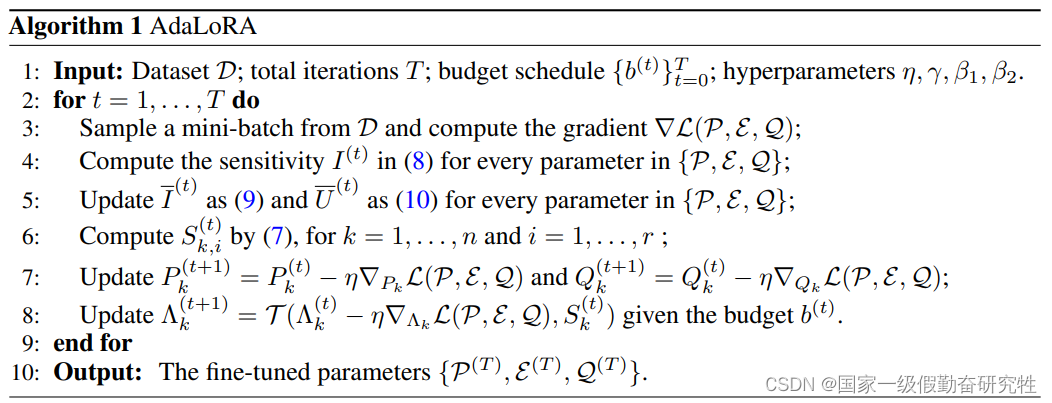
结果:(其一)
总结
当前的PEFT方法主要分为四类:
- 在原始模型框架中顺序添加可训练参数:adapter-tuning、adapter-fusion、adapter-drop、WAPR、prefix-tuning、prompt-tuning、P-Tuning、P-Tuning-V2
- 不修改原始模型框架,直接微调部分原始模型参数:diff-pruning、bitfit
- 在原始模型的框架中并行添加可训练参数:PALs、LoRA、AdaLoRA
- 混合模型(综合上述的PEFT方法):MAM-Adapter、UniPELT
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- KWin、libdrm、DRM从上到下全过程 —— drmModeAddFBxxx(27)
- 10个拿来即用的Python自动化脚本
- 算法训练day32|贪心算法part02
- 操作系统-第六章-磁盘调度算法(使用C++和vector实现)
- c++学习笔记-提高篇-案例-评委打分
- Day58|Leetcode 739. 每日温度 Leetcode 496. 下一个更大元素 I
- NumPy 高级教程——结构化数组
- C++类与对象【继承】
- 面向策略多样性的无人集群合作演化建模及仿真
- JavaScript 获取当前日期时间 年月日 时分秒的方法