Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
发布时间:2024年01月20日
大开眼界?探索多模态模型种视觉编码器的缺陷。

论文中指出,上面这些VQA问题,人类可以瞬间给出正确的答案,但是多模态给出的结果却是错误的。是哪个环节出了问题呢?视觉编码器的问题?大语言模型出现了幻觉?还是视觉特征与语言模型间的特征没有对齐?
作者将上述问题分成了9个类别(通过将涉及的问题和选项提供chatgpt,让chatgpt将这些问题归类)

- 通过实验发现,增加模型规模/训练数据的数量,多模态模型仅在颜色/外观任务和物体状态/状况这两项任务上的表现有提升。
- 通过实验发现,两张很相似的图片(如下图的两只蝴蝶),视觉编码器(CLIP)给出两张图片的相似度很高,但是自编码器(DINO)给出的相似度不是很高,作者定义这两幅图片为
CLIP-blind pairs

clip和多模态模型在这9项任务上的表现

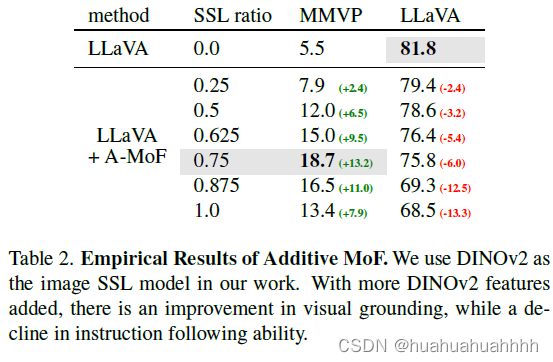
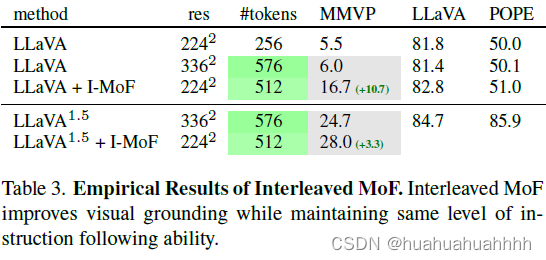
通过增加自监督特征,多模态模型的能力有了提升
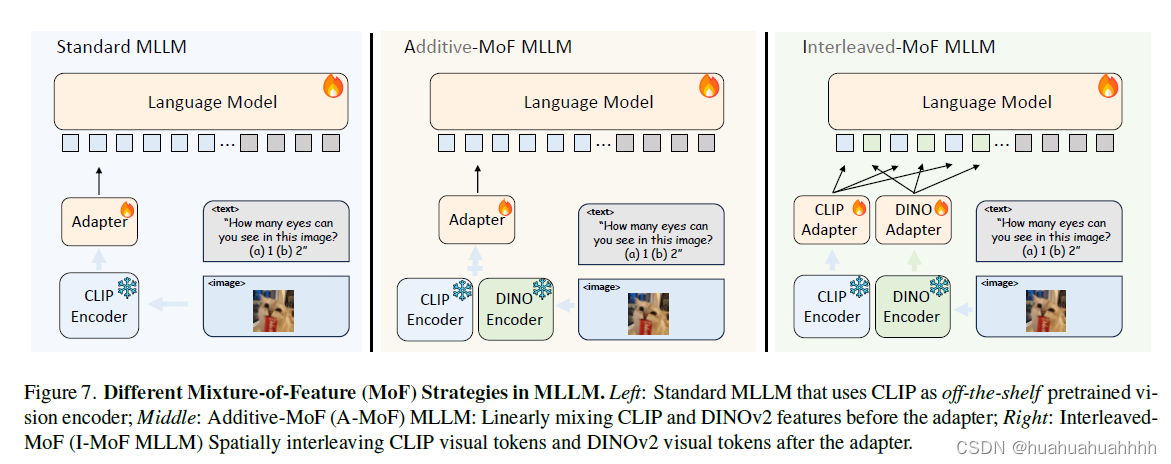
上图种左边是目前的多模态结构,中间部分是两部分特征线性相加,右边是交错混合的方式。
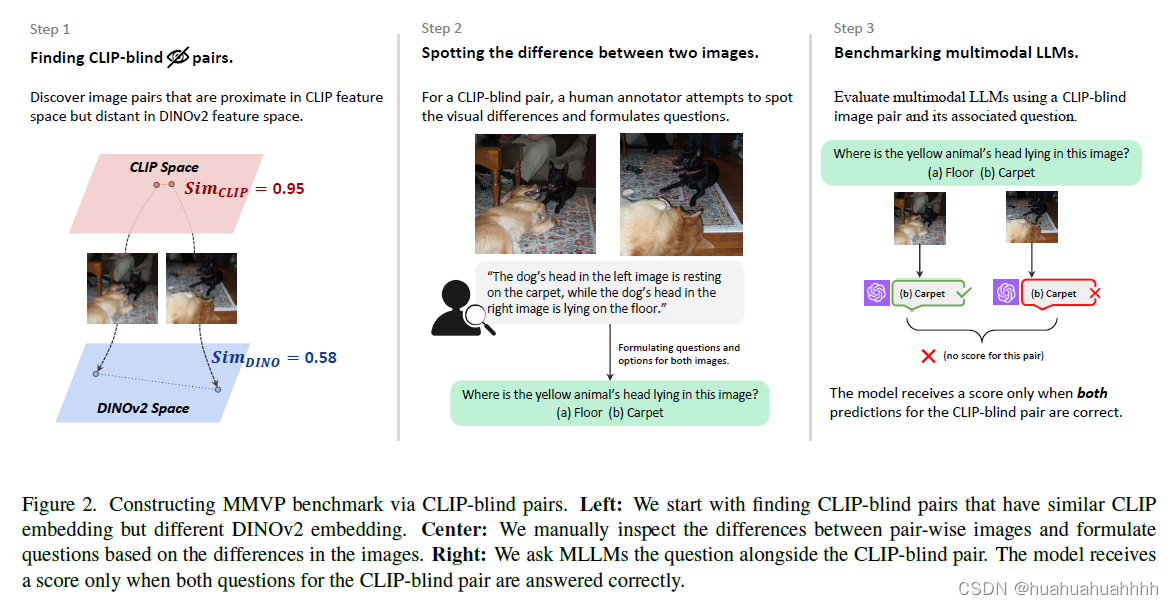
为了评价多模态模型在这些任务上的表现,建立了MMVP-VLM的测试集。
MMVP-VLM的建立过程
文章来源:https://blog.csdn.net/Blankit1/article/details/135716633
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HiddenDesktop:一款针对Cobalt Strike设计的HVNC隐藏桌面工具
- STM32WL学习
- 国密SSL证书算法
- Echarts 图表自适应
- redis-学习笔记(Jedis hash简单命令)
- 11 装饰器模式
- 人才招聘网站(JSP+java+springmvc+mysql+MyBatis)
- VSCode之PowerShell中创建项目踩坑
- Python——通过统计图像像素值初步分析图像噪声类型
- Swagger2以及Spring Boot整合Swagger2教程