[MySQL] SQL优化之性能分析
🌈键盘敲烂,年薪30万🌈

目录
?
一、索引优化
1、索引是什么:
通过一些约束,快速查询到相应字段的一种数据结构
索引在sql优化中占有非常重要的地位,因为索引与查询挂钩,查询是我们最常做的一个操作。
2、索引的数据结构:
Hash索引:查询快,但是不支持范围查询,只能精确定位某个数据。
B+树索引:查询较快,支持范围查询,这也是InnoDB存储引擎中默认的索引结构
B+树结构:
多路平衡树,每个节点存放key和指针,指针数量等于key数量+1

插播小知识:
B+树与B树,有什么区别,为什么不用二叉树???
B+树没个非叶子结点只存放指针,可以最大限度的降低树的高度,提高查询效率。
所有数据存放在叶子节点,查询稳定,而二叉树层次会更深,也会有退化为链表的风险
3、索引种类:
聚簇索引:叶子节点中主键下面挂的是每一行的数据
二级索引:叶子节点中索引值下面挂的是主键id
4、sql分析(回表查询)
现有user表,id为主键,name有唯一约束和唯一索引结构,分析下面sql语句。
-- select * from user where id = 1;
-- select * from user where name = 'zhang';
分析:
①where 后面是id,从主键索引里面查找,找到了id为1的,再看前面select 后面是 * 主键下面包含了这些字段信息,直接返回。
②where 后面是name,并且有唯一索引结构,从该索引查找,找到了姓名为zhang的,同样select * 也是查询所有字段,但是此时name下面只有主键id的值,他要根据id再次查询主键索引,性能低
二、定位慢查询语句
1、慢查询日志
- mysql带有慢查询日志,该日志会记录超过指定时间的sql语句,
注意:
慢查询日志默认为不开启,开启之后默认指定时间为10s。
可通过修改配置文件来设置这两参数。
- 修改mysql的配置文件?

缺点:
有些sql在规定的时间之内,但是查询花了9.9秒,并且性能很低,慢查询日志无法记录这样的sql我们也就无法优化.
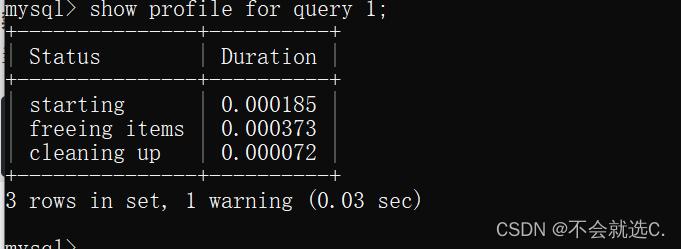
2、profile详情
- show profiles 查看sql语句的执行时间

- show profile for query query_id; 查看指定语句的执行时间
3、explain执行计划(重点)
- explain执行计划:他记录了sql查询的一些详细信息
例如:查询部门和员工信息,
控制台返回这么一张表,我们重点关注这5个字段。

type:
- 表示访问表的方式,是性能分析中重要的一个指标。常见的取值有:
ALL:全表扫描。index:通过索引扫描。range:通过索引范围扫描。ref:非唯一性索引扫描。eq_ref:唯一性索引扫描。const:单表中最多有一个匹配行的情况。
反应查询效率 从高到底分别是NULL->system->const->eq_ref->ref->range->index->all
all性能最差,也就是它是全表扫描,没有使用索引,NULL 只有像select 'A' 这样的没有查表才会这样,所以开发中我们尽量优化到system 或者const或者ref级别。
possible_keys:
- 可能使用的索引,但不一定用到
key:
- 使用的索引
key_len:
- 使用索引的长度(字节为单位)
Extra:
- 包含有关查询的额外信息,可能包括:
Using index:表示查询使用了覆盖索引。Using where:表示 MySQL 会在存储引擎层使用 WHERE 条件过滤行。Using temporary:表示查询需要创建临时表。Using filesort:表示 MySQL 会对结果使用文件排序。
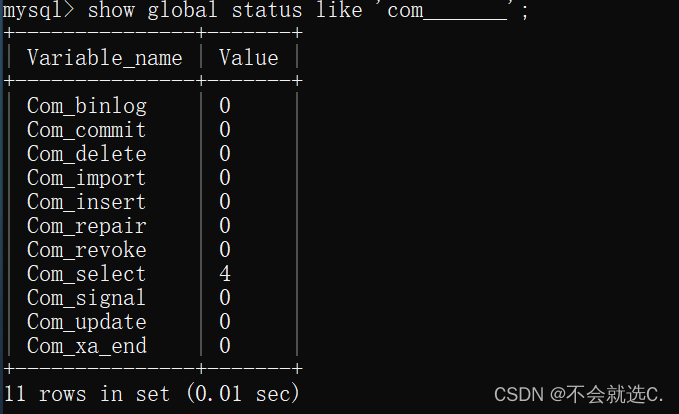
4、查看执行频次
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!