YOLOv5改进系列(27)——添加SCConv注意力卷积(CVPR 2023|即插即用的高效卷积模块)

 【YOLOv5改进系列】前期回顾:
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析
YOLOv5改进系列(5)——替换主干网络之 MobileNetV3
YOLOv5改进系列(6)——替换主干网络之 ShuffleNetV2
YOLOv5改进系列(9)——替换主干网络之EfficientNetv2
??????YOLOv5改进系列(10)——替换主干网络之GhostNet
YOLOv5改进系列(11)——添加损失函数之EIoU、AlphaIoU、SIoU、WIoU
YOLOv5改进系列(13)——更换激活函数之SiLU,ReLU,ELU,Hardswish,Mish,Softplus,AconC系列等
YOLOv5改进系列(14)——更换NMS(非极大抑制)之 DIoU-NMS、CIoU-NMS、EIoU-NMS、GIoU-NMS 、SIoU-NMS、Soft-NMS
YOLOv5改进系列(16)——添加EMA注意力机制(ICASSP2023|实测涨点)
YOLOv5改进系列(17)——更换IoU之MPDIoU(ELSEVIER 2023|超越WIoU、EIoU等|实测涨点)
YOLOv5改进系列(18)——更换Neck之AFPN(全新渐进特征金字塔|超越PAFPN|实测涨点)
YOLOv5改进系列(19)——替换主干网络之Swin TransformerV1(参数量更小的ViT模型)
YOLOv5改进系列(20)——添加BiFormer注意力机制(CVPR2023|小目标涨点神器)
YOLOv5改进系列(21)——替换主干网络之RepViT(清华 ICCV 2023|最新开源移动端ViT)
YOLOv5改进系列(22)——替换主干网络之MobileViTv1(一种轻量级的、通用的移动设备 ViT)
YOLOv5改进系列(23)——替换主干网络之MobileViTv2(移动视觉 Transformer 的高效可分离自注意力机制)
YOLOv5改进系列(24)——替换主干网络之MobileViTv3(移动端轻量化网络的进一步升级)

目录

🚀?一、SCCONV介绍?
- 论文题目:《SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy》
- 论文地址:https://openaccess.thecvf.com/content/CVPR2023/papers/Li_SCConv_Spatial_and_Channel_Reconstruction_Convolution_for_Feature_Redundancy_CVPR_2023_paper.pdf
- 大佬复现:https://github.com/cheng-haha/ScConv
1.1?SCCONV简介?
传统的网络压缩模型的方法:
- network pruning(网络剪枝)
- weight quantization(权重量化)
- low-rank factorization(低秩分解)
- knowledge distillation(知识蒸馏)
不足:虽然这些方法能够达到减少参数的效果,但是往往都会导致模型性能的衰减。
SCConv (spatial and channel reconstruction convolution),这是一个可以即插即用的,同时能够减少参数提升性能的模块。作者从空间和通道的角度分别提出spatial reconstruction unit(SRU,空间重构单元)和channel reconstruction unit(CRU,通道重构单元),核心思想是希望能够实现减少特征冗余从而提高算法的效率。
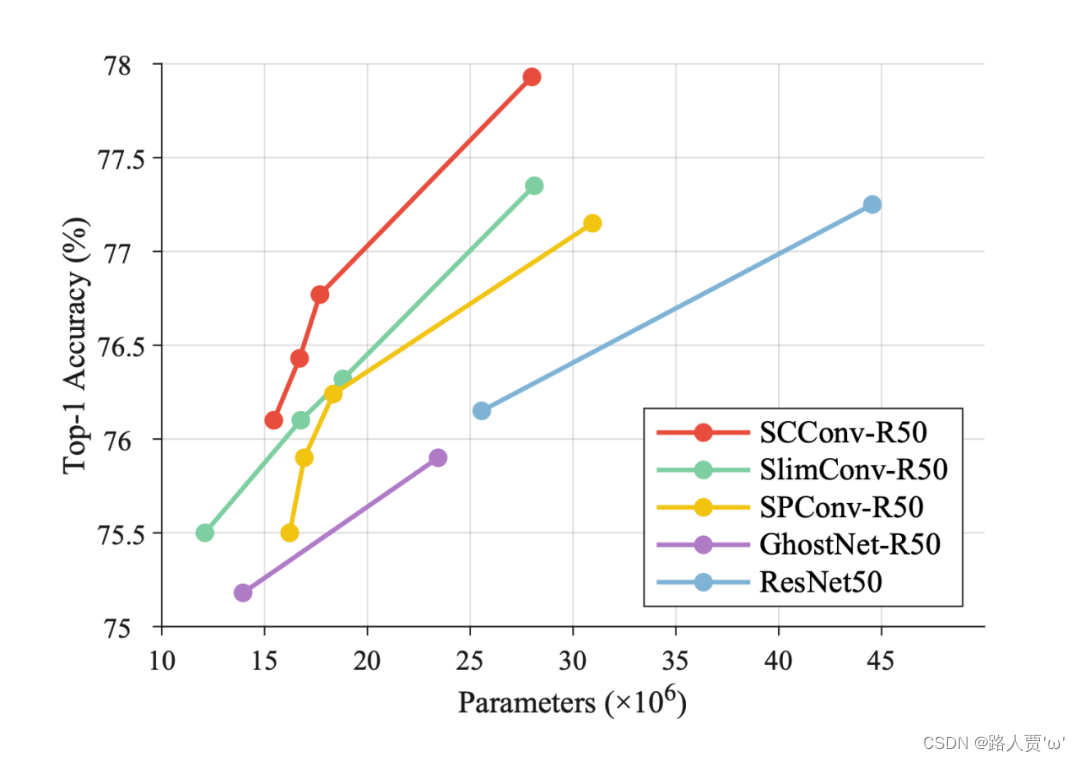
1.2?SCCONV网络结构
(1)SCCONV总模块
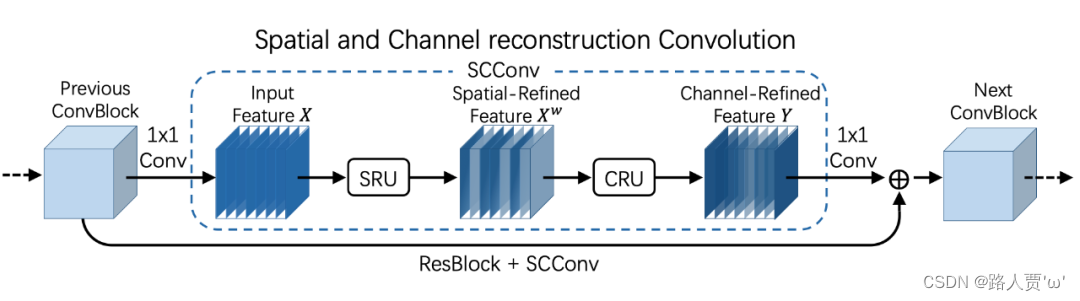 通过上图我们可以看出,首先输入的特征图通过1x1的卷积降维,然后进入SCConv的核心部分,第一步将输入的特征
通过上图我们可以看出,首先输入的特征图通过1x1的卷积降维,然后进入SCConv的核心部分,第一步将输入的特征 通过SRU得到空间细化的特征
,再经过CRU?输出通道提炼的特征
,最后再通过1x1的卷积将特征通道数恢复并进行残差操作。
(2)SRU(空间重建单元)
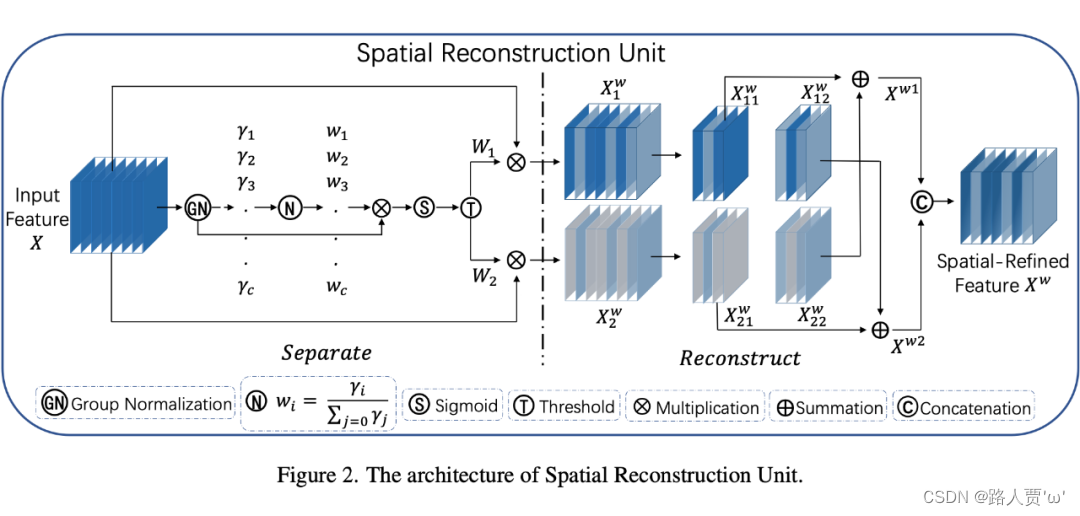
SRU结构如上图所示,采用分离-重构的方法。
分离:目的是将信息量大的特征图从信息量小的特征图中分离出来,与空间内容相对应。作者利用组归一化(GN)层中的比例因子来评估不同特征图的信息内容。

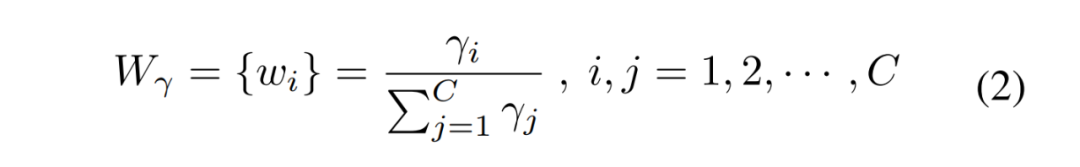
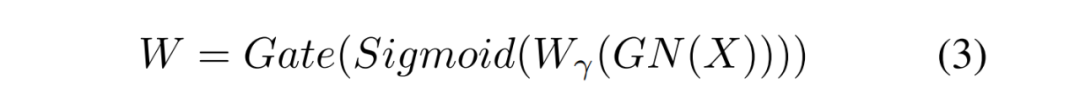
其中,和
是
的均值和标准差,
是为了除法稳定性而加入的一个小的正常数,
和
是可训练的仿射变换。?
重构:目的是将信息量较多的特征和信息量较少的特征相加,生成信息量更多的特征并节省空间。采用交叉重构运算,将加权后的两个不同的信息特征充分结合起来,加强它们之间的信息流。然后将交叉重构的特征和
进行拼接,得到空间精细特征映射
。
公式如下图所示:
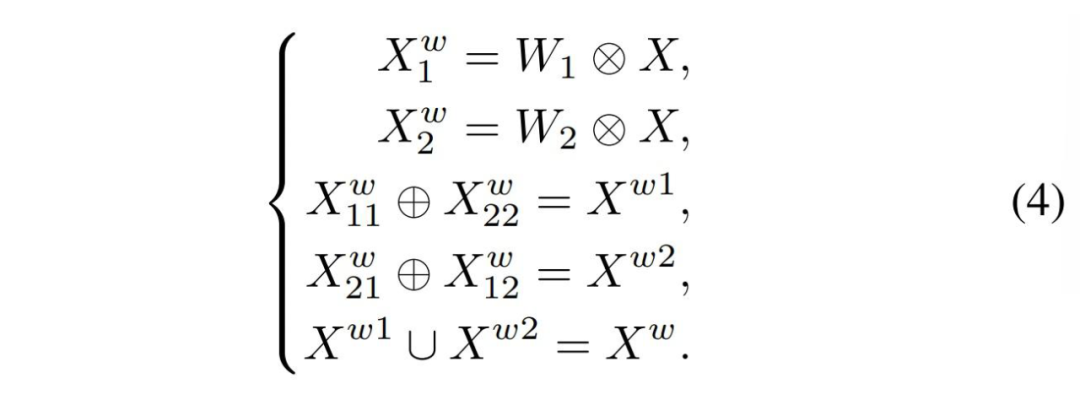
其中是元素乘法,
是元素加法,
是求并集。
效果:经过 SRU 处理后,信息量大的特征从信息量小的特征中分离出来,减少了空间维度上的冗余特征。
代码实现
class SRU(nn.Module):
def __init__(self,
oup_channels:int,
group_num:int = 16,
gate_treshold:float = 0.5
):
super().__init__()
self.gn = GroupBatchnorm2d( oup_channels, group_num = group_num )
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self,x):
gn_x = self.gn(x)
w_gamma = F.softmax(self.gn.gamma,dim=0)
reweigts = self.sigomid( gn_x * w_gamma )
# Gate
info_mask = w_gamma>self.gate_treshold
noninfo_mask= w_gamma<=self.gate_treshold
x_1 = info_mask*reweigts * x
x_2 = noninfo_mask*reweigts * x
x = self.reconstruct(x_1,x_2)
return x
def reconstruct(self,x_1,x_2):
x_11,x_12 = torch.split(x_1, x_1.size(1)//2, dim=1)
x_21,x_22 = torch.split(x_2, x_2.size(1)//2, dim=1)
return torch.cat([ x_11+x_22, x_12+x_21 ],dim=1)(3)CRU 通道重建单元
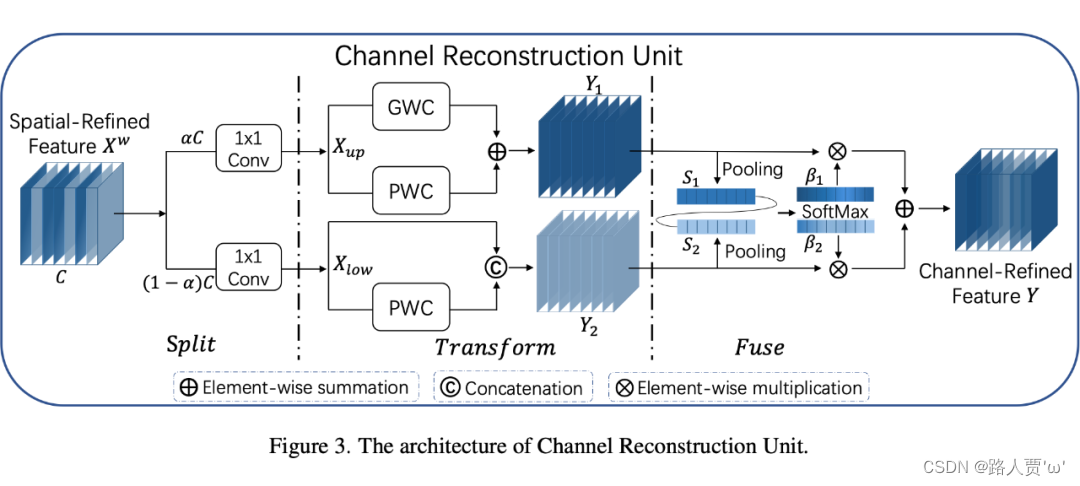
CRU结构如上图所示,采用分割-转换-融合的方法。
分割:首先将输入的空间细化特征分割成两个部分,一部分通道数是
,另一部分通道数是
,随后对两组特征的通道数使用1 * 1卷积核进行压缩,分别得到
和
。
转换:?首先将输入的作为“富特征提取”的输入,分别进行GWC和PWC,然后相加得到输出Y1,将输入
作为“富特征提取”的补充,进行PWC,得到的记过和原来的输入取并集得到
。
融合:?首先使用简化的SKNet方法来自适应合并和
。具体说是首先使用全局平均池化将全局空间信息和通道统计信息结合起来,得到经过池化德S1和S2。然后对S1和S2做Softmax得到特征权重向量
和
,最后使用特征权重向量得到输出
![]()
即为通道提炼的特征。
代码实现
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel: int,
alpha: float = 1 / 2,
squeeze_radio: int = 2,
group_size: int = 2,
group_kernel_size: int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha * op_channel)
self.low_channel = low_channel = op_channel - up_channel
self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False)
self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False)
# up
self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1,
padding=group_kernel_size // 2, groups=group_size)
self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False)
# low
self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1,
bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
# Split
up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1)
up, low = self.squeeze1(up), self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat([self.PWC2(low), low], dim=1)
# Fuse
out = torch.cat([Y1, Y2], dim=1)
out = F.softmax(self.advavg(out), dim=1) * out
out1, out2 = torch.split(out, out.size(1) // 2, dim=1)
return out1 + out2🚀二、具体添加方法
2.1 添加顺序?
(1)models/common.py ? ?--> ?加入新增的网络结构
(2) ? ? models/yolo.py ? ? ? --> ?设定网络结构的传参细节,将ScConv类名加入其中。(当新的自定义模块中存在输入输出维度时,要使用qw调整输出维度)
(3) models/yolov5*.yaml ?--> ?新建一个文件夹,如yolov5s_ScConv.yaml,修改现有模型结构配置文件。(当引入新的层时,要修改后续的结构中的from参数)
(4) ? ? ? ? train.py ? ? ? ? ? ? ? ?--> ?修改‘--cfg’默认参数,训练时指定模型结构配置文件?
2.2 具体添加步骤?
第①步:在common.py中添加ScConv模块?
将下面的ScConv代码复制粘贴到common.py文件的末尾。
# ScConv
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num:int,
group_num:int = 16,
eps:float = 1e-10
):
super(GroupBatchnorm2d,self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.gamma = nn.Parameter( torch.randn(c_num, 1, 1) )
self.beta = nn.Parameter( torch.zeros(c_num, 1, 1) )
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view( N, self.group_num, -1 )
mean = x.mean( dim = 2, keepdim = True )
std = x.std ( dim = 2, keepdim = True )
x = (x - mean) / (std+self.eps)
x = x.view(N, C, H, W)
return x * self.gamma + self.beta
class SRU(nn.Module):
def __init__(self,
oup_channels:int,
group_num:int = 16,
gate_treshold:float = 0.5
):
super().__init__()
self.gn = GroupBatchnorm2d( oup_channels, group_num = group_num )
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self,x):
gn_x = self.gn(x)
w_gamma = F.softmax(self.gn.gamma,dim=0)
reweigts = self.sigomid( gn_x * w_gamma )
# Gate
info_mask = w_gamma>self.gate_treshold
noninfo_mask= w_gamma<=self.gate_treshold
x_1 = info_mask*reweigts * x
x_2 = noninfo_mask*reweigts * x
x = self.reconstruct(x_1,x_2)
return x
def reconstruct(self,x_1,x_2):
x_11,x_12 = torch.split(x_1, x_1.size(1)//2, dim=1)
x_21,x_22 = torch.split(x_2, x_2.size(1)//2, dim=1)
return torch.cat([ x_11+x_22, x_12+x_21 ],dim=1)
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel:int,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha*op_channel)
self.low_channel = low_channel = op_channel-up_channel
self.squeeze1 = nn.Conv2d(up_channel,up_channel//squeeze_radio,kernel_size=1,bias=False)
self.squeeze2 = nn.Conv2d(low_channel,low_channel//squeeze_radio,kernel_size=1,bias=False)
#up
self.GWC = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=group_kernel_size, stride=1,padding=group_kernel_size//2, groups = group_size)
self.PWC1 = nn.Conv2d(up_channel//squeeze_radio, op_channel,kernel_size=1, bias=False)
#low
self.PWC2 = nn.Conv2d(low_channel//squeeze_radio, op_channel-low_channel//squeeze_radio,kernel_size=1, bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self,x):
# Split
up,low = torch.split(x,[self.up_channel,self.low_channel],dim=1)
up,low = self.squeeze1(up),self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat( [self.PWC2(low), low], dim= 1 )
# Fuse
out = torch.cat( [Y1,Y2], dim= 1 )
out = F.softmax( self.advavg(out), dim=1 ) * out
out1,out2 = torch.split(out,out.size(1)//2,dim=1)
return out1+out2
class ScConv(nn.Module):
def __init__(self,
op_channel:int,
group_num:int = 16,
gate_treshold:float = 0.5,
alpha:float = 1/2,
squeeze_radio:int = 2 ,
group_size:int = 2,
group_kernel_size:int = 3,
):
super().__init__()
self.SRU = SRU( op_channel,
group_num = group_num,
gate_treshold = gate_treshold )
self.CRU = CRU( op_channel,
alpha = alpha,
squeeze_radio = squeeze_radio ,
group_size = group_size ,
group_kernel_size = group_kernel_size )
def forward(self,x):
x = self.SRU(x)
x = self.CRU(x)
return x
class C3_ScConv(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(ScConv(c_) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
if __name__ == '__main__':
x = torch.randn(1,32,16,16)
model = ScConv(32)
print(model(x).shape)第②步:修改yolo.py文件?
首先找到yolo.py里面parse_model函数的这一行
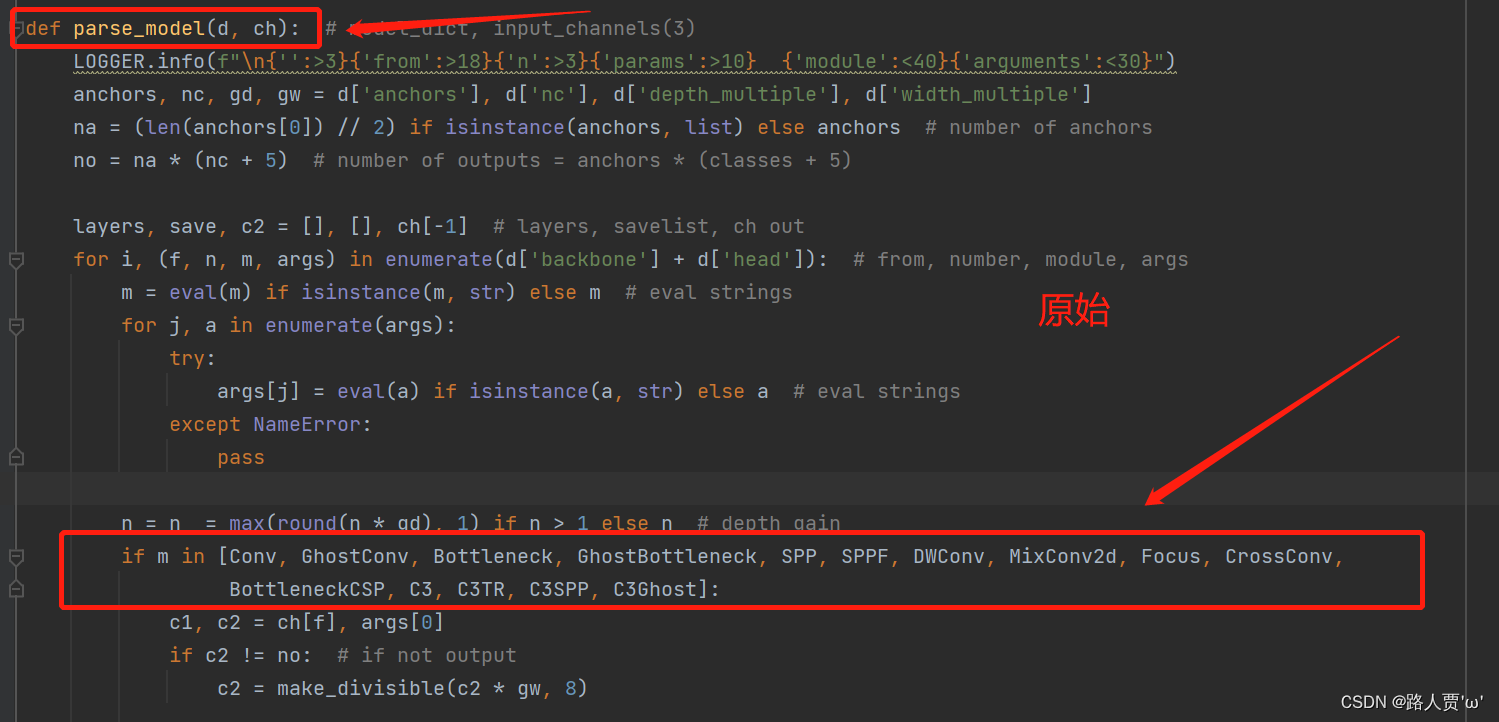 加入?ScConv、C3_ScConv 这两个模块
加入?ScConv、C3_ScConv 这两个模块
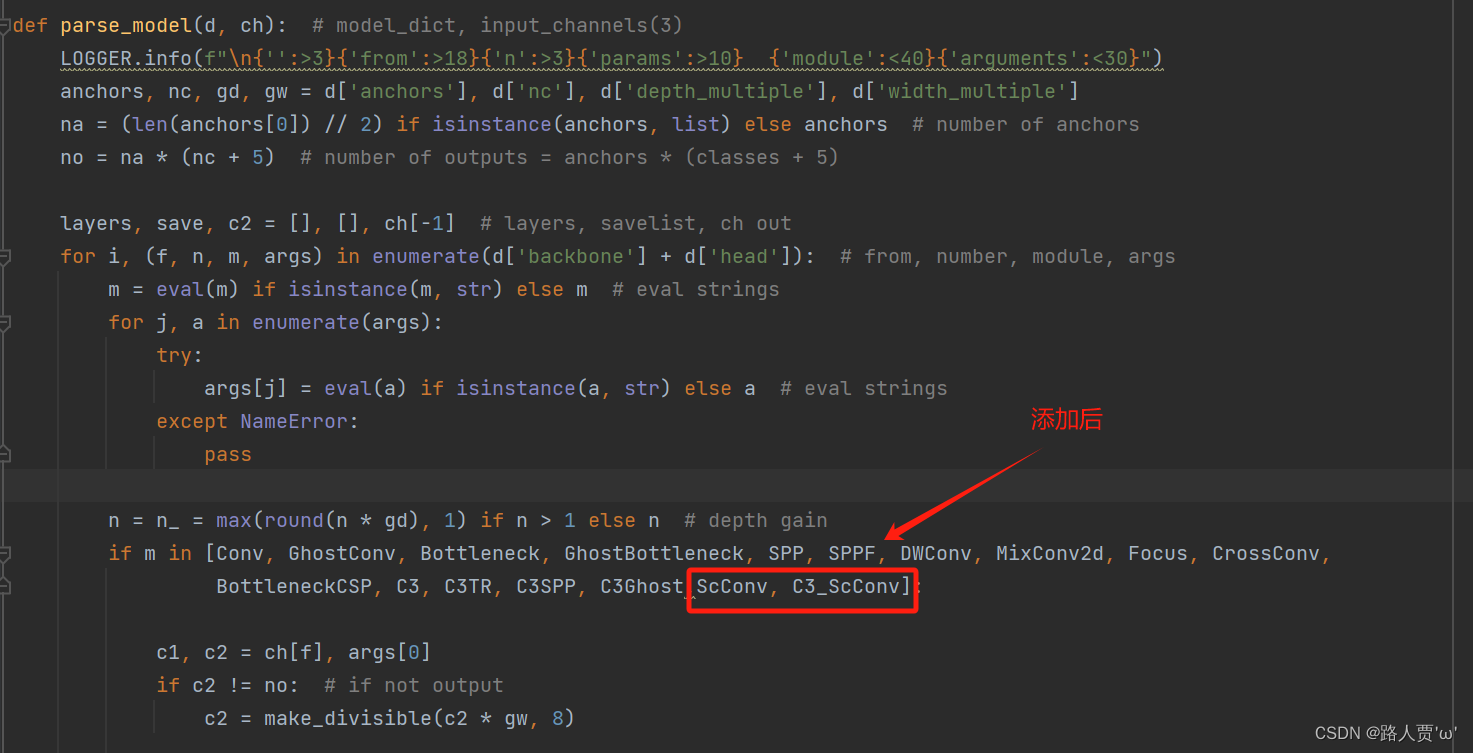
?第③步:创建自定义的yaml文件???
?第1种,在SPPF前单独加一层
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 3, ScConv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
??第2种,替换conv结构
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, ScConv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]第3种,替换C3模块
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3_ScConv, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3_ScConv, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3_ScConv, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, Conv, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3_ScConv, [512]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3_ScConv, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3_ScConv, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3_ScConv, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]第④步:验证是否加入成功
运行yolo.py
第1种
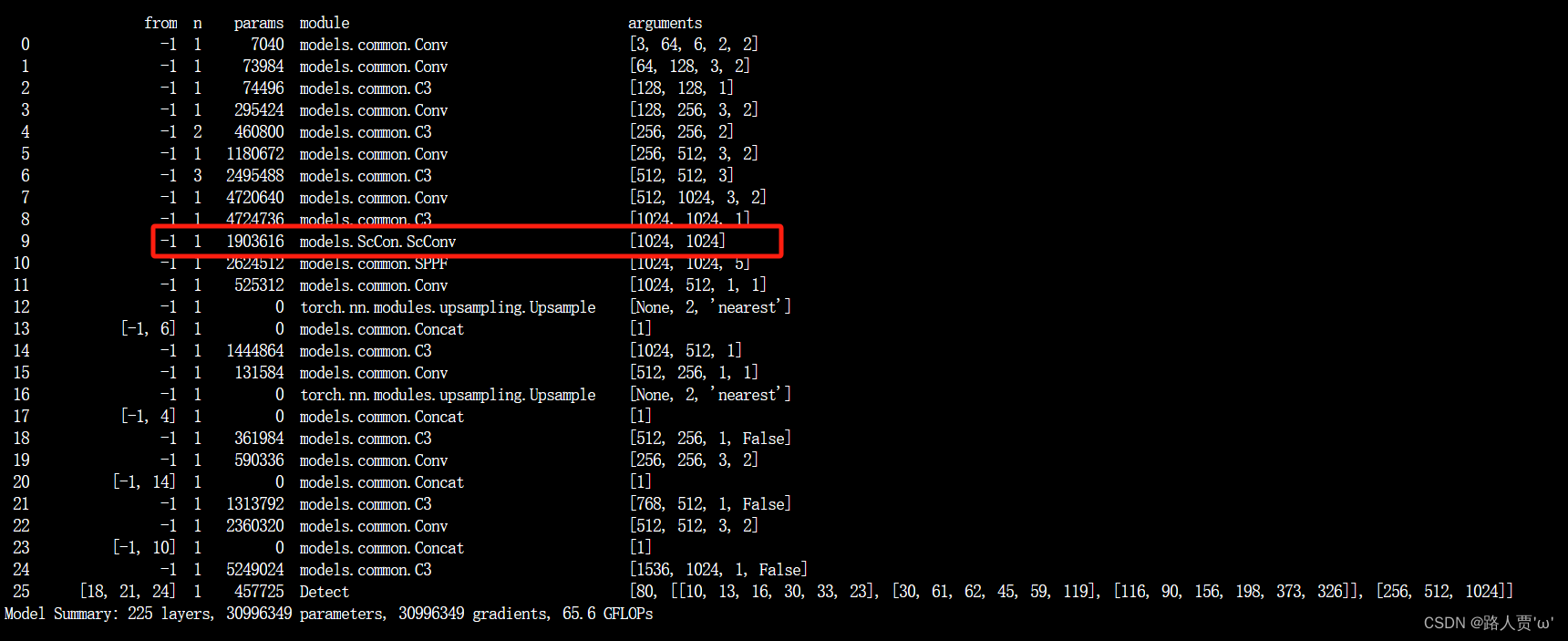
第2种?
 第3种
第3种
 这样就OK啦!?
这样就OK啦!?
🌟本人YOLOv5系列导航
??? ?🍀YOLOv5源码详解系列:??
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
??????YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
???? ?🍀YOLOv5入门实践系列:??
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
YOLOv5入门实践(5)——从零开始,手把手教你训练自己的目标检测模型(包含pyqt5界面)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RPA 培训前期准备指南——安装Uibot(RPA设计软件)
- 组态王与S7-1200PLC之间 Profinet无线以太网通信
- 中职网络安全Server2002——Web隐藏信息获取
- docker 安装redis
- Python基础(十七、函数进阶用法)
- 【C++】顺序栈入栈、出栈、取栈顶元素操作以及计算一位数加减乘除
- LeetCode-移除元素(27)&& 合并两个有序数组(88)
- FreeRTOS的heap文件
- CC工具箱使用指南:【三调名称转用地用海名称】
- VLAN协议与单臂路由