Raft算法
Raft
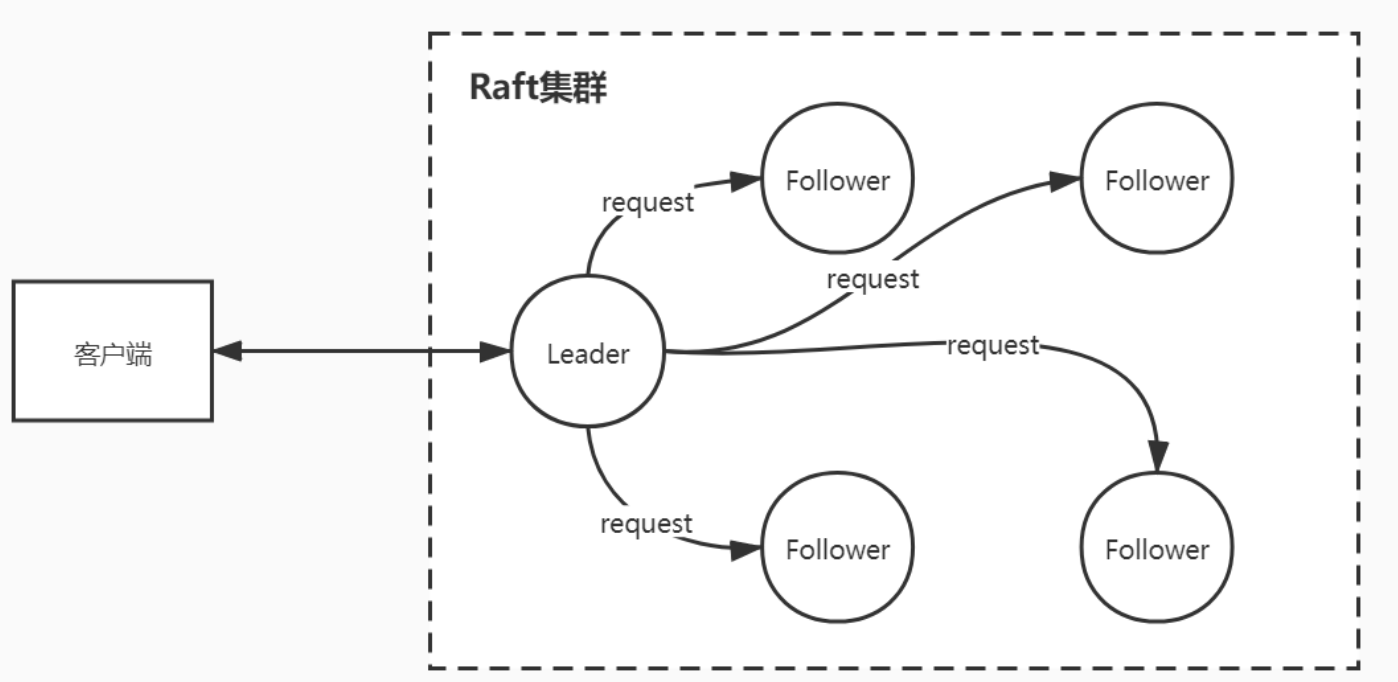
与 Paxos 不同 Raft 强调的是易懂(Understandability),Raft 和 Paxos 一样只要保证 n/2+1 节点正常就能够提供服务;raft 把算法流程分为三个子问题:选举(Leader election)、日志复制(Log replication)、安全性(Safety)三个子问题。
角色
Raft 把集群中的节点分为三种状态:Leader、 Follower 、Candidate,理所当然每种状态负责的任务也是不一样的,Raft 运行时提供服务的时候只存在 Leader 与 Follower 两种状态;
Leader(领导者-日志管理)
负责日志的同步管理,处理来自客户端的请求,与 Follower 保持这 heartBeat 的联系;
Follower(追随者-日志同步)
刚启动时所有节点为Follower状态,响应Leader的日志同步请求,响应Candidate的请求,把请求到 Follower 的事务转发给 Leader;
Candidate(候选者-负责选票)
负责选举投票,Raft 刚启动时由一个节点从 Follower 转为 Candidate 发起选举,选举出Leader 后从 Candidate 转为 Leader 状态;
Term(任期)
在 Raft 中使用了一个可以理解为周期(第几届、任期)的概念,用 Term 作为一个周期,每个 Term 都是一个连续递增的编号,每一轮选举都是一个 Term 周期,在一个 Term 中只能产生一个 Leader;当某节点收到的请求中 Term 比当前 Term 小时则拒绝该请求。
选举(Election)
选举定时器
Raft 的选举由定时器来触发,每个节点的选举定时器时间都是不一样的,开始时状态都为Follower 某个节点定时器触发选举后 Term 递增,状态由 Follower 转为 Candidate,向其他节点发起 RequestVote RPC 请求,这时候有三种可能的情况发生:
1:该 RequestVote 请求接收到 n/2+1(过半数)个节点的投票,从 Candidate 转为 Leader,向其他节点发送 heartBeat 以保持 Leader 的正常运转。
2:在此期间如果收到其他节点发送过来的 AppendEntries RPC 请求,如该节点的 Term 大则当前节点转为 Follower,否则保持 Candidate 拒绝该请求。
3:Election timeout 发生则 Term 递增,重新发起选举 在一个 Term 期间每个节点只能投票一次,所以当有多个 Candidate 存在时就会出现每个Candidate 发起的选举都存在接收到的投票数都不过半的问题,这时每个 Candidate 都将 Term递增、重启定时器并重新发起选举,由于每个节点中定时器的时间都是随机的,所以就不会多次存在有多个 Candidate 同时发起投票的问题。
在 Raft 中当接收到客户端的日志(事务请求)后先把该日志追加到本地的 Log 中,然后通过heartbeat 把该 Entry 同步给其他 Follower,Follower 接收到日志后记录日志然后向 Leader 发送ACK,当 Leader 收到大多数(n/2+1)Follower 的 ACK 信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下个 heartbeat 中 Leader 将通知所有的 Follower 将该日志存储在自己的本地磁盘中。
20.1.3.4. 安全性(Safety)
安全性是用于保证每个节点都执行相同序列的安全机制如当某个 Follower 在当前 Leader commit Log 时变得不可用了,稍后可能该 Follower 又会倍选举为 Leader,这时新 Leader 可能会用新的Log 覆盖先前已 committed 的 Log,这就是导致节点执行不同序列;Safety 就是用于保证选举出来的 Leader 一定包含先前 commited Log 的机制;
选举安全性(Election Safety):每个 Term 只能选举出一个 Leader
Leadr 完整性(Leader Completeness):这里所说的完整性是指 Leader 日志的完整性,Raft 在选举阶段就使用 Term 的判断用于保证完整性:当请求投票的该 Candidate 的 Term 较大或 Term 相同 Index 更大则投票,该节点将容易变成 leader。
raft 协议和 zab 协议区别
相同点
- ? 采用 quorum 来确定整个系统的一致性,这个 quorum 一般实现是集群中半数以上的服务器,?
- zookeeper 里还提供了带权重的 quorum 实现.
- ? 都由 leader 来发起写操作.?
- 都采用心跳检测存活性
- ? leader election 都采用先到先得的投票方式
不同点
- ? zab 用的是 epoch 和 count 的组合来唯一表示一个值, 而 raft 用的是 term 和 index?
- zab 的 follower 在投票给一个 leader 之前必须和 leader 的日志达成一致,而 raft 的 follower则简单地说是谁的 term 高就投票给谁?
- raft 协议的心跳是从 leader 到 follower, 而 zab 协议则相反? raft 协议数据只有单向地从 leader 到 follower(成为 leader 的条件之一就是拥有最新的 log), 而 zab 协议在 discovery 阶段, 一个 prospective leader 需要将自己的 log 更新为 quorum 里面最新的 log,然后才好在 synchronization 阶段将 quorum 里的其他机器的 log 都同步到一致.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 笔记:VS C++ 使用NuGut包管理器下载和使用第三方库
- 基于Vue开发的一个仿京东电商购物平台系统(附源码下载)
- 解析js之构造函数
- 压力测试+接口测试(工具jmeter)
- 助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv3开发构建生活场景下城市部件检测识别系统
- python爬取豆瓣影评,涉及知识点:bs4,requests、time、random
- JavaScript中alter、confrim、prompt的区别及使用
- 美国证券交易委员会 X 账户被黑,引发比特币市场震荡
- 基于JavaWeb实验室预约管理系统(源码+数据库+文档)
- 求A~Z所有的大写字母的Unicode值的和