Mysql 索引 、事务、隔离级别
目录
索引(index)
索引是一种为了加快数据库查询(操作)速度而引入的一种手段,需要占用额外的磁盘空间,我们之前所学的主键,唯一键,外键都是自带了索引的。另外我们也可以自己手动为某个字段(列)设置索引。并且手动添加的可以删除索引,但是像主键这种自带索引的是无法删除索引的。一个表可以有多个索引。
1.为什么要有索引?
首先我们要了解数据库查询(select)操作具体是怎样执行的:
- 遍历整个表。
- 将每一行、每个记录带入查询条件,看条件是否成立。
- 条件成立,则保留这一行记录,不满足就跳过。
从上面的执行过程来看,查询操作的时间复杂度是O(n),如果这个表的数据量很大,遍历起来就会很费时间。并且数据库的数据都是存储在硬盘上的,读硬盘操作这个过程本身开销就大。
2.引入索引的代价
引入索引虽然能够提高查询速度,但同时也是有代价的:
- 会占用更多的磁盘空间。生成索引,是需要存储额外的数据结构以及数据的。
- 可能会降低插入、修改、删除数据的速度。
- 增加查询优化器的负担。
3.索引的操作
- 1.查看索引? show index from 表名;
例如:show index from student;
- 2.创建索引? create index 索引名?on 表名(列名);
例如:create index idx_student_name on student(name); //注意索引名的写法
其实创建索引操作,也是一个危险操作,特别是在你表已经创建好且表中数据量极大时,此时创建索引,会极容易把数据库服务器给卡住。一个有效的解决方法是:另外在弄一台机器,在这台机器上部署mysql服务器,并且创建一张同样的表,然后创建好索引,最后再将原服务器上的数据导入到新的mysql服务器上。导的过程中注意控制节奏。当所有数据都导入完毕,新的数据库就可以替代旧的数据库了。
- 3.删除索引 drop index 索引名 on 表名;
例如:drop index?idx_student_name on student;?//注意索引名的写法
实际开发中,查询(读)的频率是高于修改(写)的频率的。所以引入索引还是非常有必要的。
4.索引的使用场景
- 一个表的主键,外键,唯一键都是自动创建了索引的,且不能删除。
- 一个表中的某个字段(数据列)经常查询,查询频率高并且添加、修改、删除的频率低时建立索引。
- 数据量大,磁盘空间大时,要考虑建立索引。数据量大建立索引是因为可以优化查询的速度。磁盘空间大建立索引是因为建立索引需要额外的空间存储。
索引是针对某一列,某个字段。只有对加索引的列进行条件查询的时候,查询速度才能被优化。即就是假如有一个学生表,字段有学生id,name等。只有学生id加了索引。那么where后条件查询是id的话才会优化查询速度。但若where后跟name则不会优化。
5.索引的底层原理
数据库索引用的是何种数据结构?
引入数据库的目的就是使查询操作更快,时间复杂度低。我们所知的在查询方面时间复杂度低的数据结构有哈希表,红黑树等。但是哈希表只能精确查询,并不能进行范围查询和模糊查询,因此并不适合作为索引的数据结构。而红黑树虽然既可以精确查询,又可以范围查询,还可以模糊匹配(但是%开头的这种模糊查询不支持),缺点是红黑树是一个二叉树,树的高度可能会很高,会导致IO操作频繁。
其实数据库索引操作使用的数据结构是 B+树 (即N叉搜索树)。
先说说B树:
本质上还是N叉搜索树,特点是每个节点里有多个key值,每个节点的子树个数由key的个数决定,若一个节点上保存有N个key就会划分出N+1个区间,N+1个子树。并且每个节点中key的个数也不是无限制的,达到一定的规模,就会触发节点的分裂。当删除元素达到一定的数目后,也会触发节点的合并。
N越大,树的高度就越低,读硬盘的次数就越少。由于每个节点中的所有key值都是存储在硬盘的一个区域中的,一次读硬盘操作就能读取出一个节点中的所有值。树的高度越低越好。
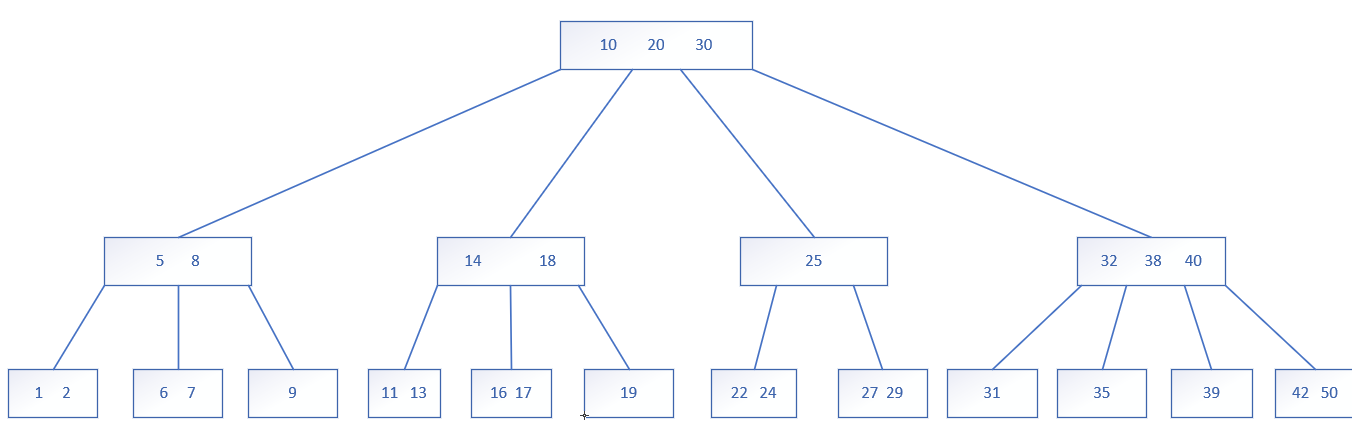
B+树是在B树的基础上做了一些改进,比如说范围查询更简单快速了。具体改进如下:
- B+树也是一个N叉搜索树,但其一个节点上若存在N个key,会划分成N个节点。
- 每个节点中的所有key值,都是按照从小到大排列的,最后一个key,就被认为是该节点下子树的最大值,就没有去划分区间。
- 父节点中的每个key值都会在子节点中出现(可能还会重复出现),所以在最下面的叶子结点这一层,就会包含整棵树的所有key值(全集)。?
- 在叶子结点这层,B+树用了链表这样的数据结构,把所有叶子结点串起来。对于范围查询操作来说更简单快速了。
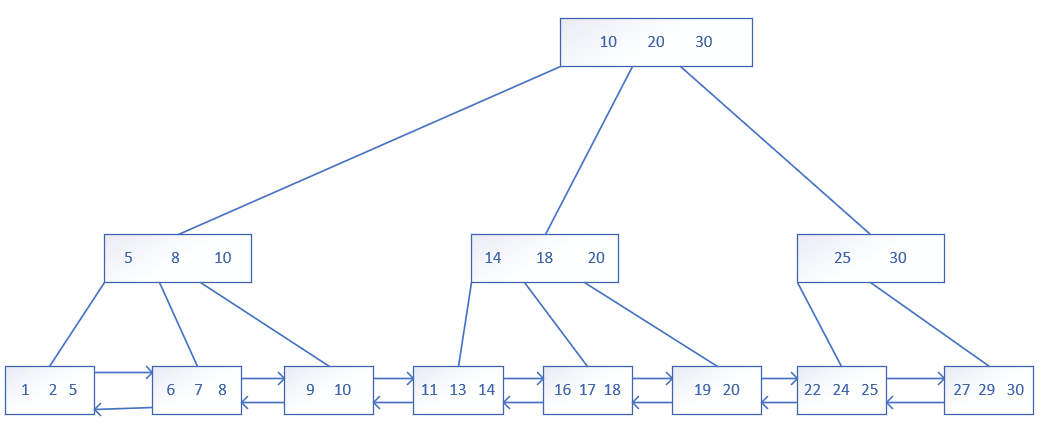
B+树的优点(相对于B树,哈希表,红黑树而言)
- 是一个N叉搜索树,树的高度低,减少读硬盘的操作(IO操作)。
- 叶子结点之间使用了链表,非常适合范围查询。
- 所有查询最终都是要查询到叶子结点这一层的,每次查询的时间是稳定的。即就算头结点就是你要查询的值,但还是会一步步查询到叶子结点的,并且叶子结点是全集。
- 由于叶子结点是全集,为了节省空间,会把行数据只存储在叶子结点上,非叶子节点只存储一个用来排序的key值。这样非叶子节点就不会占太大空间,当进行查询的时候再把非叶子节点缓存到内存中 (即就是非叶子节点也在硬盘中存储,但当我们查询的时候,可以把这些叶子结点加载到内存中,后续比较这些非叶子节点就不用去硬盘中读取了,减少IO操作次数) 。这就是第三点为啥每次都要查询到叶子结点那一层了的一部分原因。?
问题来了,非叶子节点存储到内存中,内存会不够吗?
假设排序的key值用int型,就是4个字节。假设表中有一亿条数据,就是一亿个key值,一亿个key值就是4亿字节,4亿字节约等于400MB,对于现在的内存空间来说是足够的。
字节单位转换:千字节对应KB、百万字节对应MB、十亿字节对应GB 。
另外mysql索引实现也并不只是B+树这一种,还有一种存储引擎,比如Innodb,就是mysql最常用的存储引擎。
事务 (transaction)
事务是指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。
假如做一件事,要么正确做完,要么"都不做",不能出现做一半的情况。都不做并不意味着都不做,在数据库中是指"回滚(rollback)"。
假如A给B转钱1000元,转钱是需要执行多条sql语句的,假如执行完第一句sql语句时,出现网络错误,或者是数据库挂掉了。A的账户会减少1000元,但是B的账户却没有多出1000元(因为第二条语sqi语句没有执行)。解决办法就是:使用事物来控制,保证以上两个sql语句要么全部执行成功,要全部执行失败。即就是事物的原子性。
事物的回滚是怎么做到的
使用日志的方式,记录事务中的关键操作(增删改查等操作),这种记录就是回滚的依据。
事物的四大特性
- 原子性。使用会滚的的方式
- 一致性。事务执行之前和之后,数据都不能出现离谱的情况。
- 持久性。事务作出的修改,都是在硬盘上持久保存的,重启服务器,数据依然存在。
- 隔离性。数据库并发执行多个事物时。
由于mysql数据库是一个客户端-服务器结构的程序。一个服务器经常会给多个客户端提供服务,很有可能会出现客户端1提交的事务执行了一半,客户端2提交的事务也来了。这时数据库就需要同时处理这两个事物,并发执行。如果事务之间穿行执行,即事物之间排队一个一个执行,效率就会非常低。所以事务并发执行是很有必要的。并发程度越高,执行的效率就越高。但是效率虽然高了,却也会出现一些"数据错误"的问题。比如:
并发执行事务带来的问题
1.脏读问题
例如事务A正在执行写数据操作的过程中,事务B读取这个数据。后续事务A又继续进行了修改(因为A还没执行完),这就会导致事务B读取到的数据不准确/过时/无效。也被称为脏数据。?
脏读解决方法:核心思路就是针对写操作加锁。写的时候不准读。写完才能读。并发性降低了,隔离性提高了,效率降低了,数据准确性提高了。??
上面虽然解决了脏读问题,但是只是约定了写的时候不能读,并没有约定读的时候不能写,就会造成不可重复度问题。
2.不可重复读问题
一个事物在内部多次读取到同一个数据却出现数据不同的情况。这是因为事务A在两次读取数据的期间,事务B对该数据进行了修改并提交了事务。
不可重复读解决方法:对读操作进行加锁。约定读的时候不能写。并发性降低了,隔离性进一步提高了,效率降低了,数据准确性也进一步提高了。??
3 .幻读问题
主要是结果集发生变化 。上面虽然解决了脏读和不可重复度问题。但是不可重复读约定的是事务A读a文件时,事务B不能写(修改)a文件,但是没规定事务B不能写b文件呀。此处说的问题不是说我读一个文件时,这个文件内容刷一下的变化了,而是我一次查询本来只有几个文件,结果一会又多出来或少了几个文件。主要指的是结果集的变化。即就是数据内容没变化,但是结果集变了。
幻读解决办法:引入串行化的方式,保证事务穿行执行,此时便完全没有并发了。此时隔离性是最高的,效率是最低的,数据是最准确的。?
综上所述,并发程度越高,隔离性越低,虽然效率高了,但带来的问题也越多。并发程度越低,隔离性越高,虽然效率低了,但是问题少。
隔离级别
对于注重效率还是注重数据正确不同的需求场景有不同的要求。mysql服务器也提供了"隔离级别",使我们针对不同的需求场景可以自行设置。具体是在mysql的配置文件中修改数据库的隔离级别,总共有四种隔离级别。?
隔离级别
就是在"数据正确"和"效率"之间做权衡。往往我们提升了效率,就会牺牲正确性;提升了正确性,就回牺牲效率。如果两个事物之间的影响越大,隔离性就越低;影响越小,隔离性就越高。
使用场景
充值、转账等一些与钱相关的场景,宁可不要效率,也要保证数据的准确性。
短视频、点赞、转发的数量等等这些场景下,对于准确性就不用要求太高。
四种隔离级别
- read uncommitted(读未提交)并发程度最高,速度最快,隔离性最低,准确性最低。
- read committed(读已提交)引入了写加锁。只能在写完之后再读。并发程度降低了,速度降低了;隔离性提高了,准确性提高了。
- repeatable read (可重复读) 引入了写加锁和读加锁,写的时候不能读,读的时候不能写。并发程度又进一步降低了,速度降低了;隔离性提高了,准确性提高了。mysql默认的级别。
- serialiazble(串行化)严格按照串行执行的方式,一个一个的执行事务。无并发,速度最低;隔离性最高,准确性最高。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于策略模式和简单工厂模式实现zip、tar、rar、7z四种压缩文件格式的解压
- 面试题:总结Iterator,Collection,Set,Map和他们之间的关系
- Arm汇编在线仿真及编辑器
- 安装ansible
- 行为型设计模式——命令模式
- x-cmd pkg | sd - sed 命令的现代化替代品
- 校园期刊网络投稿系统(JSP+java+springmvc+mysql+MyBatis)
- Activiti7工作流引擎:多租户
- Python学习(6)|字符串_转义字符_字符串拼接_字符串复制_input()获取键盘输入
- 15个最好的数据恢复软件工具—免费产品分享【合集】