如何利用Guava优化Java网络编程

第1章:引言
大家好!今天小黑要和咱们聊聊一个很酷的话题:如何利用Google的Guava库来优化Java网络编程。网络编程,这玩意儿听起来就高大上,不是吗?但实际上,它充满了各种挑战。从处理复杂的数据结构到管理资源和保证性能,每一步都不容小觑。但别担心,有了Guava,这些问题就变得小菜一碟了。
首先,让小黑给咱们快速回顾一下Java网络编程的常见挑战。我们要处理的东西有很多,比如网络请求的发送和接收、数据格式的转换、错误处理、还有最头疼的——性能优化。这些都是每个Java网络程序员必须面对的问题。特别是在处理大量数据或高并发请求时,一点小疏忽就可能导致程序慢如蜗牛,甚至崩溃。
但是,有了Guava,咱们就能以更简洁、更高效的方式解决这些问题。Guava提供了一系列工具和库,从基础的集合操作到高级的缓存机制,都能让咱们的网络编程之旅变得轻松愉快。
所以,本章节的目标就是让咱们对Java网络编程的挑战有个大致的了解,并简单介绍一下Guava如何帮助咱们克服这些挑战。接下来,小黑会带咱们深入Guava的世界,看看它是怎样让咱们的代码变得更加优雅和高效的。
第2章:Guava库简介
说到Guava,这可是一个宝藏库!它是Google开源的一套Java核心库,包含了各种各样的好用工具,让Java编程变得更简单、更快乐。Guava提供了大量的集合、缓存、并发工具,还有函数式风格的编程支持。简直就是Java程序员的小助手!
但Guava在网络编程中能发挥什么作用呢?咱们来看几个关键点:
- 集合工具:Guava提供了比JDK更丰富、更高效的集合操作工具,帮助咱们更好地处理数据。
- 缓存机制:Guava的缓存工具既简单又强大,可以帮助咱们提升应用性能,特别是在处理重复的数据查询时。
- 并发支持:在处理高并发网络请求时,Guava的并发工具能帮咱们大忙。
- 函数式编程支持:Guava的函数式编程工具让代码更加简洁、易读,让咱们的程序更易于维护。
接下来,小黑要展示一些代码示例,让咱们看看Guava是如何在实际中发挥作用的。比如说,咱们来看看Guava的缓存机制如何使用。假设小黑有个应用,需要频繁查询用户信息。如果不使用缓存,每次查询都要去数据库里抓数据,这可是相当耗时的。
import com.google.common.cache.CacheBuilder;
import com.google.common.cache.CacheLoader;
import com.google.common.cache.LoadingCache;
public class UserInfoCache {
private static final LoadingCache<String, UserInfo> userCache = CacheBuilder.newBuilder()
.maximumSize(1000) // 设置缓存大小
.build(
new CacheLoader<String, UserInfo>() {
public UserInfo load(String userId) {
return getUserInfoFromDatabase(userId); // 这里是从数据库获取数据的方法
}
});
public static UserInfo getUserInfo(String userId) {
return userCache.getUnchecked(userId);
}
// 假设这是从数据库获取用户信息的方法
private static UserInfo getUserInfoFromDatabase(String userId) {
// 数据库查询操作...
return new UserInfo(userId, "小黑", 28); // 这里只是一个示例
}
// 用户信息类
static class UserInfo {
String userId;
String name;
int age;
UserInfo(String userId, String name, int age) {
this.userId = userId;
this.name = name;
this.age = age;
}
}
}
这段代码展示了如何使用Guava的缓存机制来缓存用户信息。咱们先创建了一个LoadingCache,然后定义了如何加载数据。当咱们需要用户信息时,先检查缓存中是否有,如果没有,Guava会自动调用load方法从数据库加载数据,并将结果存入缓存。
通过这种方式,小黑的程序不仅运行得更快,而且代码也更简洁、更易于维护。
第3章:Guava优化网络编程的关键特性
Guava不仅仅是提高代码效率的利器,它还能让咱们的网络应用跑得飞快。怎么做到的?一起来看看吧!
1. 集合工具的魔法
首先说说Guava的集合工具,这可是它的看家本领。Guava提供了一系列超级强大的集合类,比如Multimap、BiMap、Table等,它们能在处理复杂数据结构时大大简化代码。
比如说,咱们常常需要处理键对应多个值的情况。用传统的Java集合,咱们可能得这样写:
Map<String, List<String>> map = new HashMap<>();
// ... 填充数据 ...
但用Guava的Multimap,就简单多了:
Multimap<String, String> multimap = ArrayListMultimap.create();
// ... 填充数据 ...
看到没?代码清爽多了,而且更易于管理和维护。
2. 缓存机制,提速关键
接下来说说缓存。网络编程中,咱们经常会遇到需要重复访问某些数据的情况。如果每次都去数据库或远程服务查询,那速度可就慢了。这时,Guava的缓存机制就能大显身手了。
Guava的缓存机制简单而强大。它提供了LoadingCache,可以自动加载缓存,还有CacheBuilder,让咱们可以自定义缓存行为。来看个示例:
LoadingCache<Key, Graph> graphs = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(
new CacheLoader<Key, Graph>() {
public Graph load(Key key) {
return createExpensiveGraph(key);
}
});
这段代码创建了一个最多存储1000个元素,且每个元素在写入10分钟后过期的缓存。当缓存中没有对应的元素时,Guava会自动调用load方法来获取数据。这样,咱们的应用就能飞速运行了!
3. 并发工具,高效处理请求
在网络编程中,处理高并发请求是个大挑战。Guava的并发工具可以帮咱们优雅地解决这个问题。比如ListenableFuture,它允许咱们注册回调,异步处理任务结果。
来看看如何使用它:
ListeningExecutorService service = MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
ListenableFuture<ExpensiveObject> future = service.submit(new Callable<ExpensiveObject>() {
public ExpensiveObject call() {
return new ExpensiveObject();
}
});
Futures.addCallback(future, new FutureCallback<ExpensiveObject>() {
public void onSuccess(ExpensiveObject result) {
// 处理成功的情况
}
public void onFailure(Throwable thrown) {
// 处理失败的情况
}
}, service);
这样,无论是获取数据还是处理请求,都变得非常高效。
4. I/O扩展和简化
最后来聊聊I/O操作。网络编程中,咱们经常需要读写数据。Guava提供了一些简化I/O操作的工具,比如Files和ByteStreams。
比如,咱们想要快速读取文件内容,Guava就能这样帮忙:
String content = Files.asCharSource(new File("data.txt"), Charsets.UTF_8).read();
简单吧?不仅减少了代码量,还提高了可读性和效率。
Guava在网络编程中的应用非常广泛,从集合处理到缓存、并发处理再到I/O操作,它都能让咱们的工作变得轻松愉快。这些特性不仅提高了代码的质量,还大幅提升了应用的性能。
第4章:实际案例分析
通过几个具体的例子,咱们可以更好地理解Guava如何在实际项目中发挥作用,提高开发效率和程序性能。
1. 使用Guava优化网络数据处理
首先,让咱们看一个网络数据处理的例子。想象一下,小黑在开发一个网络应用,需要从多个服务获取数据,然后进行合并处理。这里的关键在于如何高效地处理这些数据。Guava的FluentIterable就能派上用场。
来看看代码:
List<Service> services = // 获取服务列表...
List<Result> results = FluentIterable.from(services)
.transformAndConcat(new Function<Service, Iterable<Result>>() {
@Override
public Iterable<Result> apply(Service service) {
return service.getResults(); // 假设这个方法从服务中获取结果
}
})
.toList();
这段代码使用了Guava的FluentIterable,它提供了链式调用的方式来处理集合。这样一来,代码不仅简洁,而且易于理解。
2. 利用Guava缓存提高网络应用性能
接下来,咱们来看看Guava的缓存是如何提高网络应用性能的。假设小黑的应用需要频繁查询用户信息,如果每次都直接访问数据库,那效率会很低。这时,Guava的LoadingCache就能大显身手了。
来看看实际的代码:
LoadingCache<String, User> userCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterAccess(10, TimeUnit.MINUTES)
.build(new CacheLoader<String, User>() {
@Override
public User load(String userId) {
return getUserFromDatabase(userId); // 从数据库获取用户信息
}
});
// 假设这是从数据库获取用户信息的方法
private User getUserFromDatabase(String userId) {
// 数据库查询操作...
return new User(userId, "用户名");
}
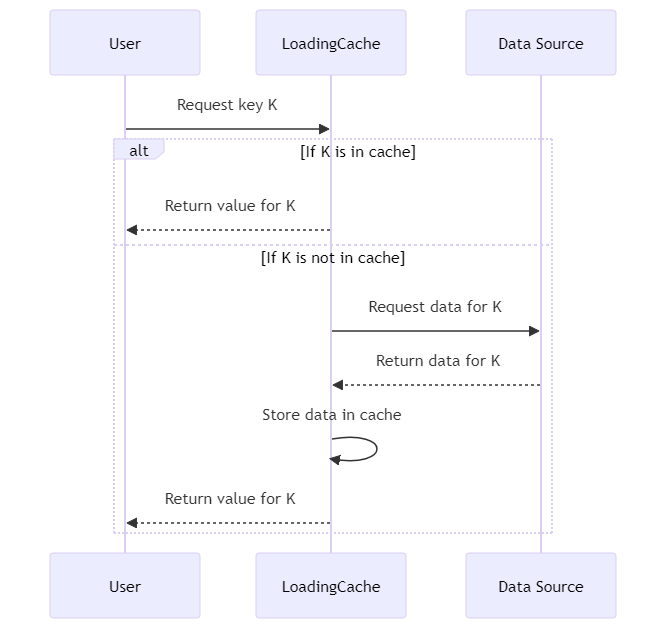
这段代码创建了一个用户信息的缓存。当查询用户信息时,先在缓存中查找,如果没有找到,Guava会自动调用load方法从数据库中加载数据,并将其存入缓存。这样一来,对于频繁访问的数据,咱们就可以大幅度提高效率了。
3. 通过Guava简化异步网络通信
在现代网络应用中,异步处理是不可或缺的一部分。Guava的ListenableFuture可以让咱们更方便地处理异步任务。
比如说,小黑需要在后台执行一个耗时的网络请求,然后在请求完成后更新UI。传统的方式可能需要复杂的线程管理,但用Guava就简单多了。
看看这段代码:
ListeningExecutorService service = MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
ListenableFuture<Response> future = service.submit(new Callable<Response>() {
public Response call() throws Exception {
return doNetworkCall(); // 执行网络请求
}
});
Futures.addCallback(future, new FutureCallback<Response>() {
public void onSuccess(Response result) {
updateUI(result); // 更新UI
}
public void onFailure(Throwable t) {
handleError(t); // 处理错误
}
}, service);
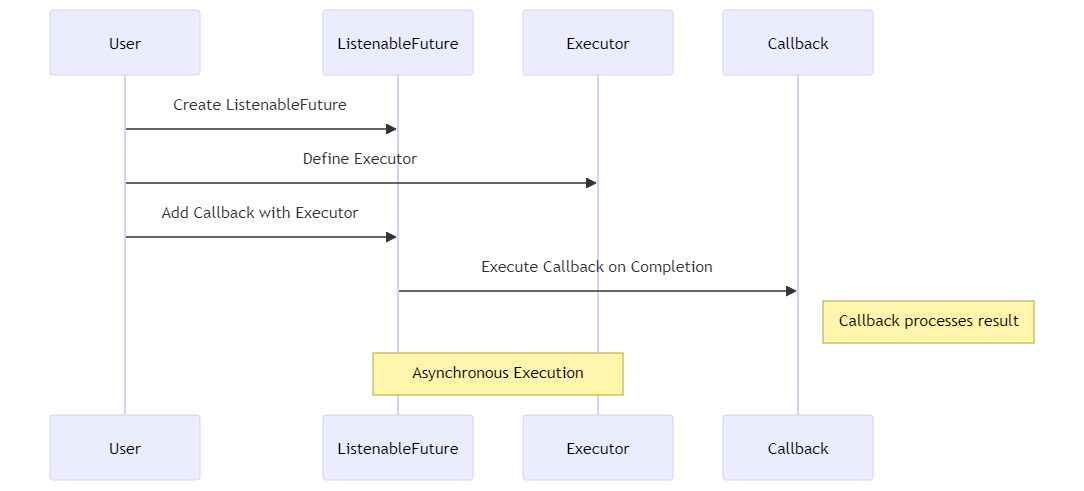
这段代码演示了如何使用Guava的ListenableFuture来处理异步网络请求。咱们在后台线程中执行网络请求,然后在请求完成后通过回调更新UI或处理错误。这样做的好处是代码清晰,逻辑分明,易于维护。
第5章:Guava与Java网络编程的集成
在网络编程的世界里,整合新工具通常是个挑战,但别担心,Guava的设计让这变得简单许多。咱们一起来看看怎么做吧!
1. Guava集成的步骤
集成Guava到现有项目,基本上就是添加依赖、替换一些实现,然后享受它带来的便利。首先,确保你的项目中加入了Guava库。如果是使用Maven,就在pom.xml文件中添加依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>最新版本号</version>
</dependency>
然后,咱们就可以开始使用Guava的各种功能了。
2. 用Guava优化数据处理
比如说,咱们的项目中可能有很多地方在处理集合数据。用Guava的集合工具,就能使代码更简洁、更高效。举个例子,如果咱们原来这样处理集合:
Map<String, List<String>> data = new HashMap<>();
for (String key : keys) {
if (!data.containsKey(key)) {
data.put(key, new ArrayList<>());
}
data.get(key).add(someValue);
}
用Guava的Multimap,可以简化成:
Multimap<String, String> data = ArrayListMultimap.create();
for (String key : keys) {
data.put(key, someValue);
}
看到没?代码变得简洁多了!
3. 使用Guava进行缓存优化
另一个例子是缓存优化。原来的项目可能没有良好的缓存机制,或者实现复杂。用Guava的缓存工具,就能轻松搞定。
比如,小黑要缓存一些用户数据,原来可能是这样的:
Map<String, User> cache = new HashMap<>();
// ... 数据加载和缓存逻辑 ...
现在用Guava:
LoadingCache<String, User> userCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterAccess(10, TimeUnit.MINUTES)
.build(new CacheLoader<String, User>() {
public User load(String userId) {
return getUserFromDatabase(userId);
}
});
这样,咱们就有了一个高效的缓存机制,既简化了代码,又提高了性能。
4. 并发处理的改进
在网络编程中,处理并发请求是常态。Guava提供了ListenableFuture等并发工具,可以帮助我们更好地管理异步任务。
假设原来的代码是这样的:
ExecutorService executor = Executors.newFixedThreadPool(10);
Future<Result> future = executor.submit(new Callable<Result>() {
public Result call() throws Exception {
// 执行一些长时间运行的任务
return new Result();
}
});
用Guava优化后:
ListeningExecutorService service = MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
ListenableFuture<Result> future = service.submit(new Callable<Result>() {
public Result call() throws Exception {
// 同样的长时间运行的任务
return new Result();
}
});
Futures.addCallback(future, new FutureCallback<Result>() {
public void onSuccess(Result result) {
// 任务成功完成时的处理
}
public void onFailure(Throwable thrown) {
// 任务失败时的处理
}
});
这样的改动不仅使代码更加清晰,而且提高了异步任务的处理能力。
第6章:性能对比和分析
有时候,一点小改动就能带来巨大的性能提升,Guava就是这样一把锋利的工具。咱们来看看实际的案例分析吧!
1. 集合处理性能对比
首先来看看集合处理。在网络编程中,处理大量数据是家常便饭。Guava的集合工具不仅提高了代码的可读性,还大大提升了性能。
比如,小黑之前用普通的Java集合来处理一项数据合并任务。代码大致是这样的:
Map<String, List<String>> dataMap = new HashMap<>();
for (Data data : dataList) {
if (!dataMap.containsKey(data.getKey())) {
dataMap.put(data.getKey(), new ArrayList<>());
}
dataMap.get(data.getKey()).add(data.getValue());
}
但自从用了Guava的Multimap之后,性能提升了不少。看看改进后的代码:
Multimap<String, String> dataMap = ArrayListMultimap.create();
for (Data data : dataList) {
dataMap.put(data.getKey(), data.getValue());
}
这个改变减少了代码量,而且由于Guava的内部优化,处理速度也更快了。
2. 缓存优化的性能提升
接下来说说缓存。Guava的缓存工具对性能的提升尤为明显。之前,小黑的项目在处理重复数据请求时,每次都要访问数据库,效率低下。但引入Guava缓存后,情况大为改观。
看看使用Guava缓存前后的对比:
未使用Guava:
Map<String, User> userCache = new HashMap<>();
// 每次请求都要检查Map,然后可能访问数据库
使用Guava后:
LoadingCache<String, User> userCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterAccess(10, TimeUnit.MINUTES)
.build(new CacheLoader<String, User>() {
public User load(String userId) {
return getUserFromDatabase(userId);
}
});
使用Guava后,对于频繁访问的数据,现在多数情况下直接从内存中获取,大大减少了数据库访问,提高了响应速度。
3. 异步处理的效率对比
在处理大量并发请求时,效率至关重要。Guava的ListenableFuture在这方面就显示出了它的强大。
传统的异步处理方式可能是这样的:
ExecutorService executor = Executors.newFixedThreadPool(10);
Future<Result> future = executor.submit(new Callable<Result>() {
public Result call() throws Exception {
// 执行一些长时间运行的任务
return new Result();
}
});
而用Guava的ListenableFuture改进后:
ListeningExecutorService service = MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
ListenableFuture<Result> future = service.submit(new Callable<Result>() {
public Result call() throws Exception {
// 执行相同的长时间运行的任务
return new Result();
}
});
使用ListenableFuture,咱们可以更方便地处理异步结果,提高了代码的执行效率和响应速度。
第7章:最佳实践和注意事项
和大家分享一些使用Guava时的最佳实践和注意事项。虽然Guava是个强大的工具,但是如果不恰当地使用,也可能导致问题。所以,了解如何正确地使用它是非常重要的。让咱们一起来看看吧!
1. 合理使用Guava集合
Guava提供了一系列强化了的集合类,比如Multimap、BiMap等。这些集合类在使用时要比标准Java集合更加灵活,但也需要注意以下几点:
-
选择合适的集合类型:根据实际需要选择合适的Guava集合类型。例如,当需要存储键映射到多个值时,应使用
Multimap而不是普通的Map。 -
避免不必要的集合转换:Guava集合提供了丰富的工具方法,避免频繁的集合类型转换,这样可以提高性能。
-
理解集合的不可变性:Guava的不可变集合(Immutable Collections)一旦创建就不能被修改。在需要不变性保证的场景下,这非常有用。
2. 缓存使用原则
Guava的缓存工具非常强大,但也需要合理使用:
-
合理设置缓存大小和过期时间:根据应用的实际需要设置缓存大小和过期策略,避免内存泄漏。
-
明智地选择缓存加载策略:
CacheLoader可以在缓存中没有找到所需值时自动加载它们,但这也可能成为性能瓶颈。确保加载操作的效率。 -
处理缓存异常:缓存操作可能会抛出异常,正确处理这些异常能确保程序的健壯性。
3. 并发工具的正确使用
在使用Guava的并发工具,如ListenableFuture时,要特别注意以下几点:
-
避免阻塞调用:在可能的情况下,使用异步方法替代阻塞调用,这样可以提高程序的响应性和吞吐量。
-
正确处理回调:当使用
ListenableFuture的回调时,确保逻辑正确,异常得到处理。 -
线程池的管理:合理配置和管理线程池,防止资源浪费或耗尽。
4. I/O操作的优化
使用Guava的I/O库时,也有一些需要注意的地方:
-
使用高效的I/O方法:Guava提供了很多简化和高效的I/O操作方法,如
Files.asCharSource等,使用这些方法可以简化代码并提高性能。 -
处理I/O异常:I/O操作可能会抛出异常,正确处理这些异常是非常重要的。
5. 避免滥用功能
虽然Guava提供了很多强大的功能,但也不意味着应该在每个地方都使用它。在一些简单的场景下,标准的Java库可能就足够了。合理选择使用Guava的地方,可以避免过度复杂化代码。
合理地使用Guava可以极大地提高Java编程的效率和质量。但也要注意,任何工具的使用都需要根据实际情况来决定,避免不恰当的使用。希望这些最佳实践和注意事项对大家有所帮助,能让大家在使用Guava时更加得心应手!
第8章:结语
回顾Guava的精彩旅程
- Guava简介:咱们了解了Guava是什么,以及它为Java编程带来的种种好处。
- 集合处理:Guava在集合处理方面的强大功能,无疑是Java编程的一大提升。
- 缓存优化:Guava的缓存工具不仅强大而且灵活,极大地提升了应用的性能。
- 异步编程:Guava在处理并发和异步任务方面的能力,为复杂网络编程提供了强有力的支持。
- 性能对比:通过实际案例,咱们看到了使用Guava前后的明显性能提升。
- 最佳实践和注意事项:正确使用Guava是非常重要的,咱们学习了如何避免常见的陷阱。
Guava的不断演进
值得一提的是,Guava作为一个活跃的开源项目,一直在不断演进和改进。这意味着,它将继续为Java社区带来新的工具和功能,帮助解决更多的编程难题。所以,保持对Guava更新的关注,总是个不错的主意。
结束语
无论是使用Guava还是其他任何工具,最重要的始终是解决问题的思路和方法。工具只是帮助咱们更高效地实现这些思路的手段。希望这些内容能激发你们对编程的热情,帮助你们在编程路上走得更远。
祝大家编程愉快,我们下次再见!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c# 设置文件夹隐藏
- 华为OD机试真题-运输时间-2023年OD统一考试(C卷)
- 【工具】使用ssh进行socket5代理
- patchless amsi学习(下)
- 驾驭数字孪生:智慧水利的未来之路
- django高校毕业班校务管理系统(程序+开题报告)
- 51pm2.5+组会仿真
- 【Spring Boot】SpringMVC入门
- Vue解决跨域问错误:has been blocked by CORS policy 后端跨域配置
- 手柄上(switch、ps4、PSVita)竟然也能看B站客户端,简直太香了