Redis中BigKey的分析与优化
Redis中BigKey的分析与优化
Redis以其出色的性能和易用性,在互联网技术栈中占据了重要的地位。
但是,高效的工具使用不当也会成为性能瓶颈。在Redis中,BigKey是常见的性能杀手之一,它们会消耗过多的内存,导致网络拥塞,
甚至引起Redis服务的延迟。因此,合理地处理和预防BigKey的生成,是每个使用Redis的开发者都应该掌握的技能。

BigKey的定义与识别
1、 BigKey的定义
Redis中的BigKey通常指的是那些包含大量元素的复合数据类型,如一个列表包含数百万个元素,或一个字符串的大小超过512MB。
这些BigKey会在执行操作时消耗大量的CPU和内存资源,影响Redis的响应时间。
2、 BigKey的识别方法
手动识别BigKey可以使用如下Redis命令:
redis-cli --bigkeys
自动化识别可以使用脚本来周期性地检测,如下Python脚本示例:
import redis
# 连接到Redis服务器
r = redis.StrictRedis(host='localhost', port=6379, decode_responses=True)
def find_big_keys(redis_conn, threshold):
cursor = '0'
big_keys = []
while cursor != 0:
cursor, keys = redis_conn.scan(cursor=cursor, count=1000) # 分批迭代keys
for key in keys:
size = redis_conn.memory_usage(key)
if size > threshold:
big_keys.append((key, size))
return big_keys
# 打印出所有大于1MB的key
for key, size in find_big_keys(r, 1024 * 1024):
print(f"BigKey: {key}, Size: {size}")
# 还可以使用异步任务,将得到的key放到指定的地方进行存储,方便后面分析处理
这里使用SCAN命令而非KEYS命令,因为SCAN命令是基于游标的迭代器,可以分批次迭代keys,减少对内存的冲击。
这个脚本分批迭代所有的keys,并且仅在发现超过指定大小的key时才会将其信息打印出来或者进行其他操作。
通过设置count参数,你可以根据你的Redis服务器的具体情况来调整每批次处理的keys数量,以达到在不影响Redis性能的前提下完成BigKeys的检测。此外,这个脚本应该在Redis的负载较低时运行,以最小化其对生产环境的影响。
BigKey的产生原因
1、 不合理的数据设计
一个典型的例子是将用户的所有行为数据存放在一个大的List中,而不是分拆成多个小List按时间或者事件类型存储。
2、 业务逻辑变化
随着业务发展,原本预计不会存储大量数据的Key,可能因为用户量的增长或业务逻辑的变化变成了BigKey。
3、 缺失的监控预警
没有及时地监控和预警系统的话,一旦数据量异常增长,就可能产生BigKey,而未能及时发现。
BigKey带来了什么样的问题
1、 性能问题
由于Redis的单线程模型,BigKey的操作可能会阻塞其他命令的执行,造成明显的延迟。
2、 资源消耗
BigKey占用大量内存,可能会导致内存溢出或者其他数据的驱逐。
3、 数据管理问题
BigKey会给数据迁移工作带来挑战,特别是在使用Redis集群时。
BigKey的处理方案
1、 切割大key
可以将一个大的Hash表切割成多个小Hash表,每个Hash表存储一部分数据。
2、 删除或过期
可以对BigKey进行渐进式删除,避免一次性删除造成服务的长时间阻塞。
redis-cli --eval del_big_key.lua , bigkey_name
3、 使用合适的命令
使用Scan系列命令进行数据处理,避免一次性操作大量数据。
redis-cli scan 0 match * count 1000
如何有效避免BigKey产生的策略
1、 合理的数据模型设计
根据业务需求选择合理的数据类型,例如使用小Hash代替大String。
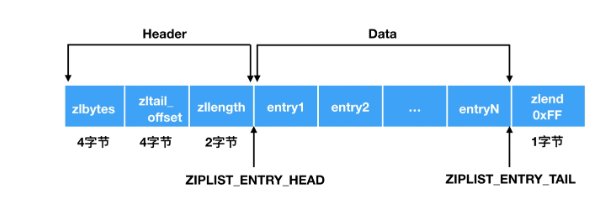
Redis为Hash类型的字段使用了特殊的编码方式,如ziplist或hashtable,这些编码方式可以在保持较小内存占用的同时存储相对较小的值。
当Hash中的元素数量和单个元素的大小达到一定阈值时,Redis会自动从ziplist转换为hashtable,这种优化能够有效利用内存。
2、 强化监控预警机制
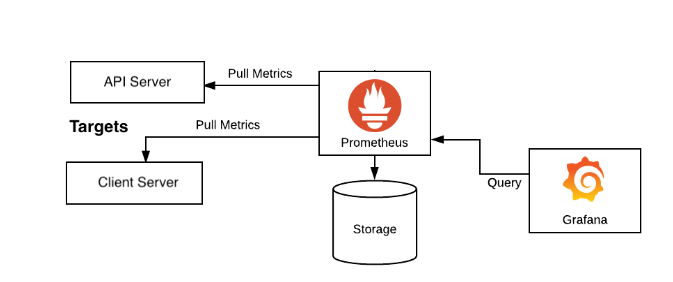
利用Redis自带的监控工具或第三方监控工具,如 Prometheus + Grafana,及时发现异常。
3、 定期的性能评估与优化
定期进行性能评估,及时对数据模型进行调整。
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记和面经,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的阿里大佬写的刷题笔记,让我offer拿到手软
总结
BigKey问题在Redis的使用中是一个不能忽视的问题。通过合理的数据模型设计,强化监控预警机制,以及定期的性能评估,
可以有效地避免BigKey的产生,保持Redis的高性能。我们需要不断地学习和应对新的技术挑战,提升系统的稳定性和可用性。
推荐几个学习 Redis 教程文章
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!@小郑说编程
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 炫酷按钮制作(HTML+CSS+Javascript)
- 关于标准的那些事——第二篇 规矩
- 『C++成长记』模板
- 【Python】 字符串格式
- 【Linux】进程间通信——system V 共享内存、消息队列、信号量
- Java SE入门及基础(8)
- SpringCloud微服务架构,适合接私(附源码)
- RabbitMQ交换机(3)-Topic
- JavaScript中如何使用jq获取checkbox值
- Golang简单实现IO操作