【论文阅读】MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA
Make-a-video:没有文本-视频数据的文本-视频生成。
paper:
code:
ABSTRACT
优点:
(1)加速了T2V模型的训练(不需要从头开始学习视觉和多模态表示),
(2)不需要配对的文本-视频数据,
(3)生成的视频继承了当今图像生成模型的庞大性)。
构建具有新颖有效时空模块的T2I模型。首先分解全时间U-Net和注意力张量,并在空间和时间上近似。其次,设计了一个时空pipeline,通过视频解码器、插值模型和两个超分辨率模型生成高分辨率和帧率的视频。
?
1 INTRODUCTION
用T2I模型学习文本和视觉世界之间的对应关系,并用无监督学习在无标记的视频数据上学习真实的运动。文本并不能完整描述视频的运动,Make a video可以对其进行推算,可以在无描述的情况下学习动作。
贡献:
- 利用联合文本-图像先验,绕过对配对文本-视频数据的需求,反过来能扩展到更大量的视频数据。
- 提出了空间和时间上的超分辨率策略,给定文本输入,生成高清高帧率的视频。
- 根据现有的T2V系统评估Make-A-Video,并提出:(a)定量和定性测量的最先进结果,以及(b)比现有T2V文献更彻底的评估。还收集了一套300个提示的测试集,用于zero-shot T2V评估。
2 PREVIOUS WORK
baseline:NUWA ,cogvideo,VDM。
在T2V生成中,NUWA 在多任务预训练阶段结合图像和视频数据集,以提高模型泛化的微调。
CogVideo使用预训练和固定的T2I模型进行T2V生成,只有少量可训练参数,以减少训练过程中的内存使用。但是固定的自编码器和T2I模型可能会限制T2V的生成。
VDM架构可以实现图像和视频的联合生成。然而,他们从随机视频中抽取随机的独立图像作为图像源,并且没有利用大量的文本-图像数据集。
3 METHOD
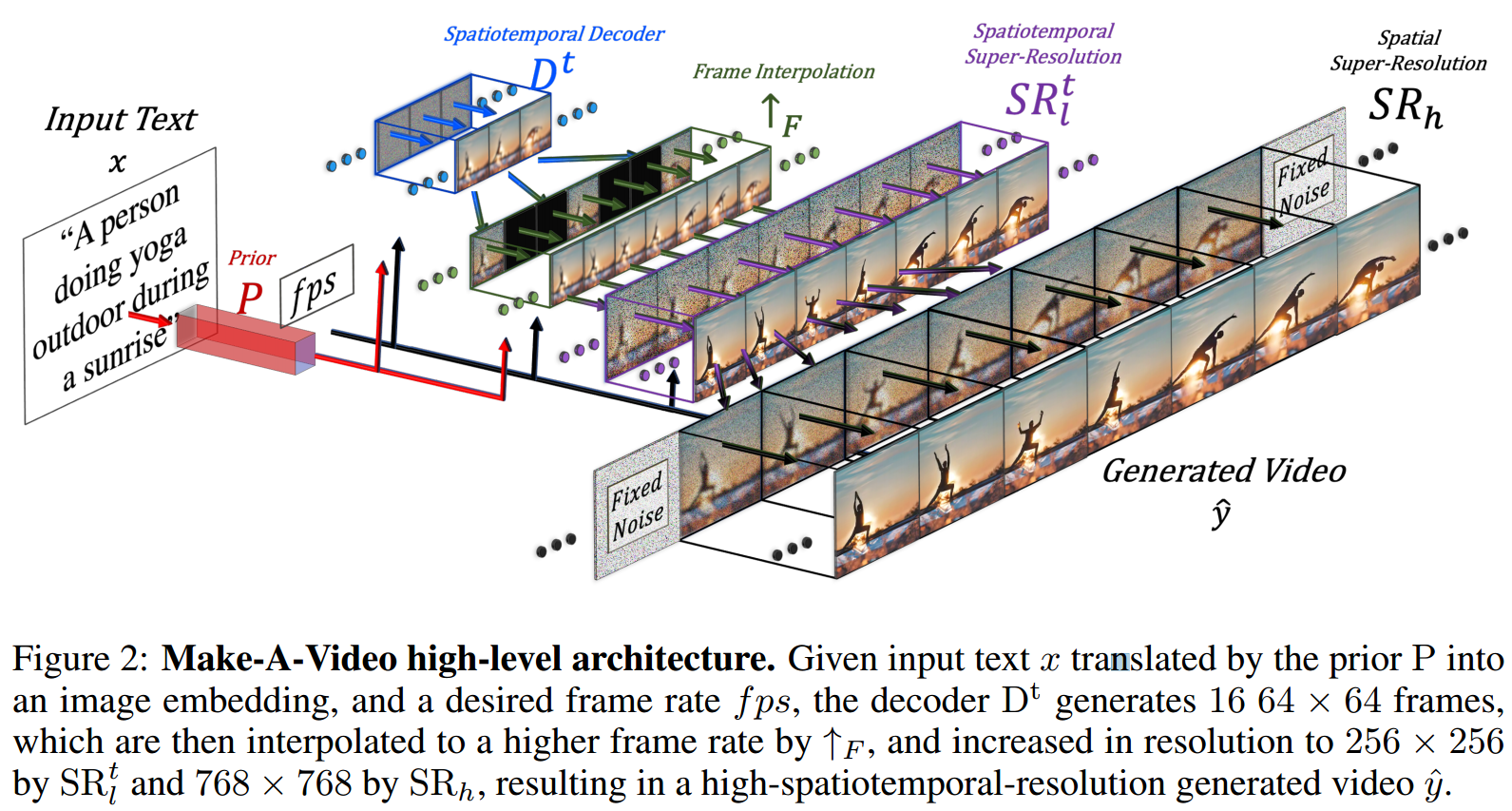
图2:Make-A-Video高级架构:1.给定由先验P翻译成图像嵌入的输入文本x和期望的帧率fps,解码器Dt生成16个 64 × 64大小的帧,2.然后通过F插值到更高的帧率。3.通过SRtl和SRh将分辨率增加到256 × 256和768 × 768,从而生成高时空分辨率的视频y^。
三个主要组成部分:
(i)基于文本-图像对训练的基本T2I模型(第3.1节),
(ii)将网络构建块扩展到时间维度的时空卷积和注意层(第3.2节),
(iii)由时空层组成的时空网络,以及T2V生成所需的另一个关键元素-用于高帧率生成的帧插值网络(第3.3节)。
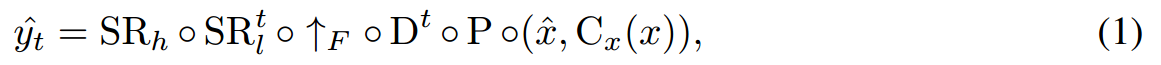
y^t:生成的视频,SRh;SRl:空间和时空的超分辨率网络(第3.2节),F:帧插值网络(第3.3节),dt:时空解码器(第3.2节),P:先验(第3.1节),x^:bpe编码的文本,Cx:CLIP文本编码器, x:输入文本。?
3.1 TEXT-TO-IMAGE MODEL
训练该方法的主干:在文本-图像对上训练的T2I模型。
(i)先验网络P,在推理过程中生成给定的文本嵌入xe和BPE编码的文本token x^,
(ii)生成低分辨率64 × 64 RGB图像y^l的解码器网络D,以图像嵌入ye为条件,
(iii)两个超分辨率网络SRl,SRh,分别将生成的图像y^l分辨率增加到256 × 256和768 × 768像素,从而生成最终的图像y^。
3.2 SPATIOTEMPORAL LAYERS
为了将二维(2D)条件网络扩展到时间维度,本文修改了两个关键模块,(i)卷积层和(ii)注意力层。
其他层如全连接层,在添加额外维度时不需要特定的处理,因为它们与结构化的空间和时间信息无关。
在基于u - net的扩散网络中进行了时间上的修改:时空解码器Dt生成16个RGB帧,每个大小为64 × 64,新添加的帧插值网络F,通过在生成的16帧之间进行插值来增加有效帧率(如图2所示),以及超分辨率网络SRtl。
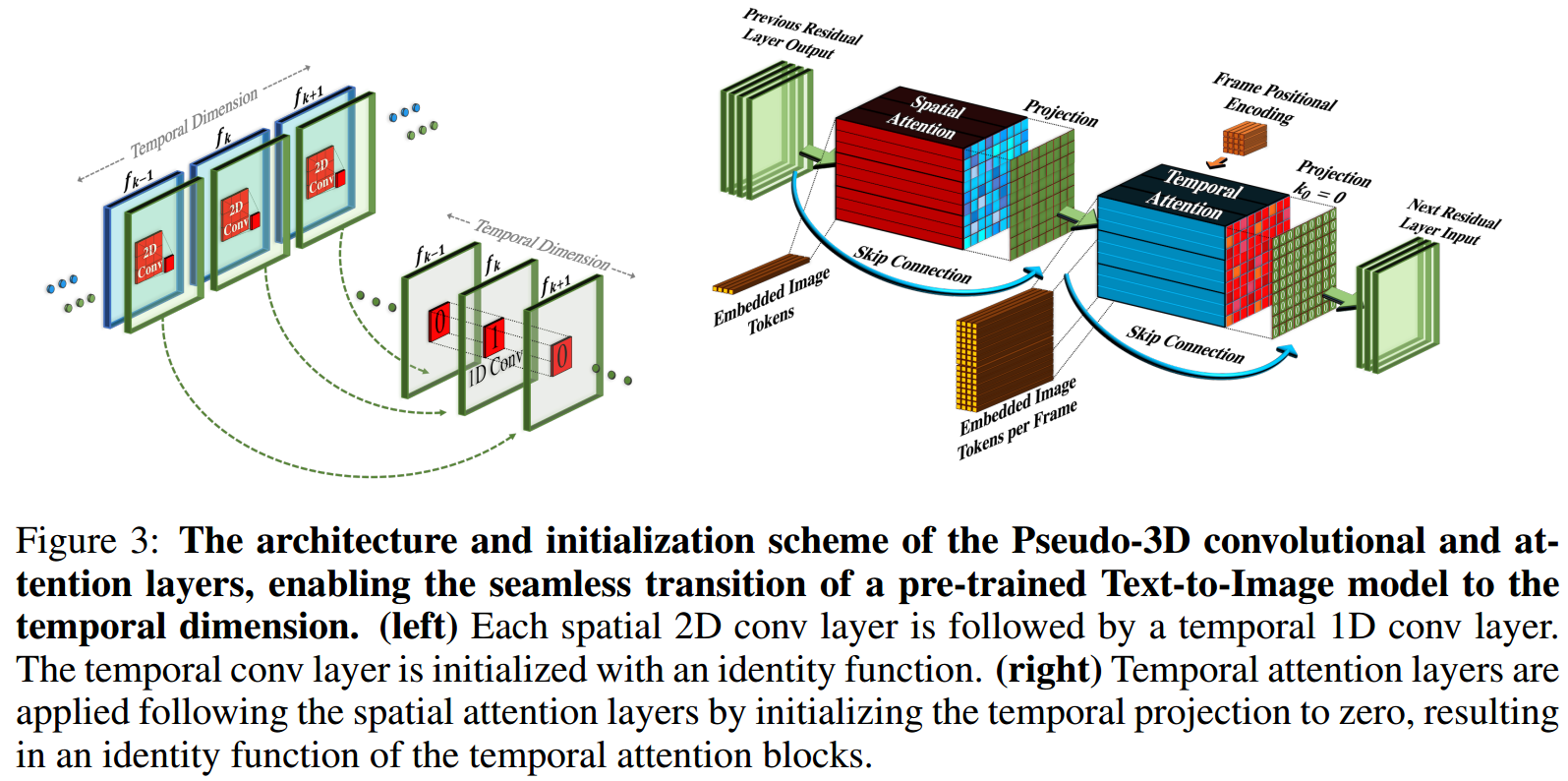
图3:伪3d卷积层和注意力层的架构和初始化方案,使预训练的文本-图像模型无缝过渡到时间维度。(左)每个空间2D conv层之后都是一个时间1D conv层。(右)将时间投影初始化为零,在空间注意力层之后应用时间注意力层,产生时间注意力块的恒等函数。
3.2.1?PSEUDO-3D CONVOLUTIONAL LAYERS
伪3d卷积层。在每个2D卷积(conv)层之后堆叠一个1D卷积,如图3所示。这有助于空间轴和时间轴之间的信息共享,而没有3D转换层的沉重计算负荷。
此外,它在预训练的2D转换层和新初始化的1D转换层之间创建了一个具体的分区,允许从头开始训练时间卷积,同时在空间卷积的权重中保留以前学习的空间知识。
给定一个输入张量h∈B×C×F ×H×W,其中B, C, F, h, W分别是批次,通道,帧,高度和宽度尺寸,伪3D卷积层定义为

转置算子?T在空间和时间维度之间进行互换。对于平滑初始化,虽然Conv1D层是从预训练的T2I模型初始化,但Conv1D层被初始化为恒等函数,从而实现从训练仅空间层到时空层的无缝过渡。
初始化时,网络生成K个不同的图像(随机噪声),每个图像仅对应输入文本,缺乏时间一致性。
代码解析:
定义一个2D的卷积
定义一个1D的卷积
用dirac初识它
temporal的卷积层变成identity function空间卷积,每帧都是独立的,所以【BF,C,H,W】
时间卷积是ID的卷积在不同的帧上,所以把帧f放在最后一堆,CHW放到Batch上参考:【论文精读】MAKE-A-VIDEO:TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA-CSDN博客
3.2.2 PSEUDO-3D ATTENTION LAYERS
T2I网络的一个关键组成部分是注意力层,除了自关注提取的特征外,文本信息与其他相关信息(如扩散时间步长)一起被注入到几个网络层次中。我们也将维度分解策略扩展到注意层。在每个空间注意层后,叠加一个时间注意层。输入张量h,将flatten定义为一个矩阵算子,它将空间维度平坦化为h ∈ B × C×F × H × W。
将空间上的attention扩展到了时间维度。伪3D注意层定义为:
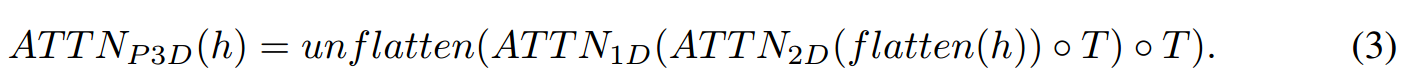
与卷积层3D类似,为了允许平滑的时空初始化,注意力2D层从预训练的T2I模型初始化,注意力1D层初始化为恒等函数。
帧率调节。添加了一个额外的条件参数fps,表示生成视频中的每秒帧数。对每秒帧数的变化进行调节,使额外的增强方法能够在训练时处理有限数量的可用视频,并在推理时对生成的视频提供额外的控制。
代码解析:
以前是HW上做attenrion,现在在f上加了一层attention
实现在时间上做信息交互。
attention函数:
初始化空间上的attetion
初始化时间上的attention
进入维度的tensor
将空间维度展开。为什么用伪?这样参数量小。3D参数量太大了。
在VDM和CogVideo上都有。
Frame rate conditioning(帧速率调节)
损失函数:混合模型 hybrid loss
MSE+KLD
原文链接:https://blog.csdn.net/m0_60634555/article/details/129714795
3.3 FRAME INTERPOLATION NETWORK
帧插值网络。输入到unit里,不再是三个channel,而是四个channel。然后多了一个binary channel去判断该帧是否是被mask的。中间插帧的帧数是可变的。
3.4 TRAINING
Make-A-Video每一个部分都是单独训练的。
prior网络只接受输入,只在文本-图像对上训练,类似于DALLE-2的训练方式
decoder网络和超分网络,首先在图像上做训练,不需要文本。需要注意的是,这个解码器接收CLIP decoder解码器作为输入。用CLIP magen enbedding做输入。
在原模型训练好后,我们需要扩充temporal的维度。扩展完后,我们需要在未标记的video上做fine-turn。我们需要做16张从原始数据上的采样。训完后再训插帧网络。
?
4 EXPERIMENTS

表1:MSR-VTT对T2V生成的评价。zero-shot即没在MSR-VTT上训练。样本/输入:为每个输入生成多少样本。


 ?
?
5 DISCUSSION
用无监督学习更多的视频有助于摆脱对标记数据的依赖。本文工作表明,标记图像与未标记视频片段有效结合可以实现这一目标。
限制。该方法无法学习只能在视频中推断的文本和现象之间的关联。如何将这些结合起来(例如,生成一个人从左到右或从右到左挥手的视频),以及生成具有多个场景和事件的较长视频,描述更详细的故事,留给未来的工作。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Selenium Grid - 多台计算机上并行运行
- 画中画视频剪辑:创意与技术的完美结合,批量制作视频不再难
- 辞旧迎新喜开颜
- Java中Long转Int转字符串Int转Long以及Int超出长度判断
- 开源免费虚拟化KVM的部署及其虚拟机资源变更、快照、克隆等常见运维操作
- KVM Vcpu概述
- Windows 11打印屏幕(截屏)不要自动保存截图位图文件!
- 找不到vcruntime140_1.dll 无法执行的处理方法分享,教你修复vcruntime140_1.dll文件
- 如何使用ActiveMQ
- 伪装目标检测的算术不确定性建模