CMU15-445-Spring-2023-Project #1 - 前置知识(lec01-04)
Lecture #01_ Relational Model & Relational Algebra
Databases
数据库是相互关联的数据的有组织集合,对现实世界的某些方面进行建模。区别于DBMS(MySQL、Oracle)。
Flat File Strawman
数据库以CSV文件的形式存储,并由DBMS管理。

Database Management System
DBMS是允许应用程序在数据库中存储和分析信息的软件。
数据模型(data model)是描述数据库中数据的概念集合。e.g. relational、NoSQL、vectors。
模式(schema)是对基于数据模型的特定数据集合的描述。
Relational Model
关系模型定义了一种基于关系的数据库抽象,以避免维护开销。

relation是一组无序集合,允许重复元素出现,等价于table。
tuple(domain)代表relation中的一组属性,带有n条属性的relation叫做n-ary relation。
relation中primary key唯一标识一个元组。
foreign key指定一个关系中的属性必须映射到另一个关系中的元组。
Data Manipulation Languages (DMLs)

Relational Algebra
关系代数是一组基本操作,用于检索和操作关系中的元组。
- Select

- Projection

- Union

- Intersection

- Difference

- Product

- Join:根据共有的属性中的相同值进行连接,并去除重复列。

Lecture #02_ Modern SQL
Relational Languages
关系代数基于集合set(无序、无重复)。SQL基于包bag(无序,允许重复)。
SQL History

Joins
合并一个或多个表中的列,生成一个新表。用于表达涉及跨多个表的数据的查询。

Aggregates
- aggregation function

- DISTINCT keyword
- GROUP BY

- HAVING

String Operations
SQL标准规定字符串区分大小写,且只允许单引号。
LIKE keyword:“%”匹配任意字串,包含空;“_”匹配任意单个字符。
“||”:将两个或多个字符串连接成一个字符串。
Date and Time
操作DATE和TIME属性。
Output Redirection

列数和type需要一致,列名不需要。
Output Control
- ORDER BY

- LIMIT

Nested Queries


Window Functions
ROW_NUMBER():当前行的编号。在窗口函数排序前计算。
RANK():当前行的顺序位置。在窗口函数排序后计算。
OVER clause:指定计算窗口函数时如何将tuple分组。 使用 PARTITION BY 指定分组。使用 GROUP BY 排序。

Common Table Expressions
临时表,其作用域仅限于单个查询。

在 WITH 后添加 RECURSIVE 关键字,可以让 CTE 引用自身。

Lecture #03_ Database Storage (Part I)
Storage
关注面向磁盘的DMS,即数据库存储在非易失磁盘上。
DBMS需要关注如何将在非易失磁盘与易失memory之间移动数据。由于从磁盘获取数据的速度非常慢,DBMS将重点关注隐藏磁盘的延迟,而不是对寄存器和高速缓存进行优化。
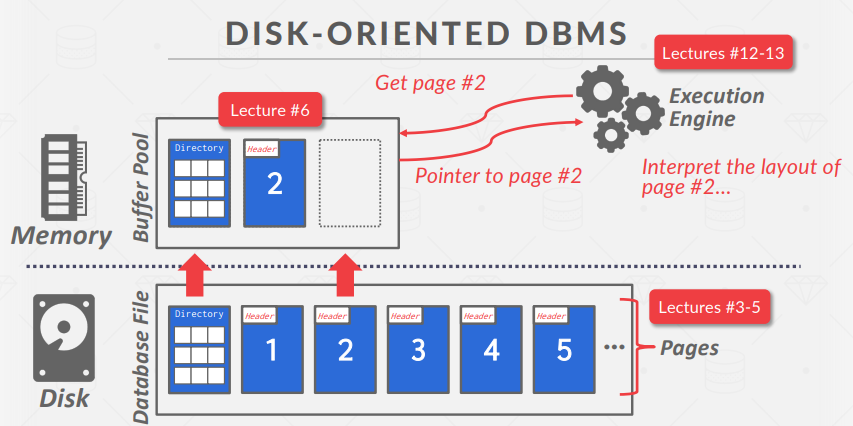
Disk-Oriented DBMS Overview
数据库全部在磁盘上,数据库文件中的数据按页组织,第一页是目录页。
要对数据进行操作,DBMS需要将数据带入内存。为此,数据库管理系统需要一个**缓冲池(buffer pool)**来管理数据在磁盘和内存之间的移动。DBMS还有一个执行引擎来执行查询。执行引擎会向缓冲池请求一个特定页面,缓冲池会负责将该页面带入内存,并向执行引擎提供一个指向内存中该页面的指针。缓冲池管理器将确保在执行引擎对内存中的该部分进行操作时,页面仍然存在。
DBMS vs. OS
实现虚拟内存的一种方法是使用 mmap (memory mapping)将文件内容映射到进程的地址空间,这样操作系统就可以负责在磁盘和内存之间来回移动页面。但是如果 mmap 遇到页面错误,进程就会被阻塞。

File Storage
DBMS 的最基本形式是将数据库存储为磁盘上的文件。操作系统对这些文件的内容一无所知。只有 DBMS 知道如何破译它们的内容,因为这些内容是以 DBMS 特有的方式编码的。 DBMS 的存储管理器负责管理数据库的文件。它将文件表示为页面集合。它还会跟踪哪些数据已被读取和写入页面,以及这些页面中还有多少可用空间。
Database Pages
DBMS 在一个或多个文件中以固定大小的数据块(称为页)组织数据库。页面可以包含不同类型的数据(tuple、index等)。大多数系统不会在页面中混合这些类型的数据。
每个页面都有一个唯一的标识符。如果数据库是一个单独的文件,那么页面 ID 可以只是文件偏移量。大多数数据库管理系统都有一个间接层,将页面 ID 映射到文件路径和偏移量。
大多数 DBMS 使用固定大小的页面,以避免支持可变大小页面所需的工程开销。
存储设备保证以原子方式写入硬件页的大小。如果硬件页面为 4 KB,而系统尝试向磁盘写入 4 KB,那么要么 4 KB 全部写入,要么全部不写入。
Database Heap
堆文件是一个无序的页面集合,其中的tuples以随机顺序存储。可以在磁盘上找到 DBMS 需要的页面位置。
DBMS 在给定页面 ID 的情况下找到磁盘上的页面的方法:
- Linked List:页眉页持有指向空闲页列表和数据页列表的指针。但是,如果 DBMS 要查找特定页面,则必须对数据页列表进行顺序扫描,直到找到要查找的页面。
- Page Directionary:DBMS 维护特殊页面,跟踪数据页面的位置以及每个页面上的可用空间。
Page Layout


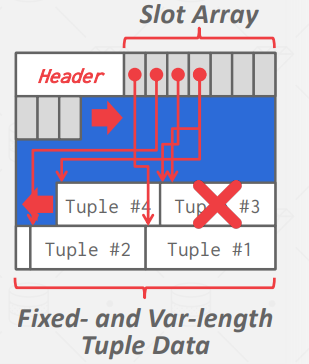
Tuple Layout

非规范化元组数据(Denormalized Tuple Data):如果两个表有关联,DBMS就可以 "预连接 "它们,这样这两个表就会出现在同一个页面上。这使得读取更快,因为数据库管理系统只需加载一个页面,而不是两个独立的页面。不过,由于数据库管理系统需要为每个元组提供更多空间,因此更新成本会更高。
Lecture #04_ Database Storage (Part II)
Log-Structured Storage
page layout如果是slotted page的话,会有一些问题:tuple的删除;读取一个tuple需要读取整个block;tuple的更新可能需要花费大量时间切换block。
log structure DBMS不存储tuple,只存储log。
- log包含元组的唯一标识符、操作类型(PUT/DELETE)以及元组的内容;
- 倒序扫描读取记录,同时可以使用索引跳转到日志中的特定位置;
- 由于写入是顺序的,所以速度很快;
- 可以定期压缩日志,方法是在多个页面中只记录每个元组的最新变化;
- 压缩后,由于每个元组只有一个,不再需要排序,因此DBMS可以按 id 排序,以加快查找速度。这些表称为排序字符串表(Sorted String Tables,SSTables);
- 缺点是压缩成本较高,还会导致写入放大(重复写入相同的数据);

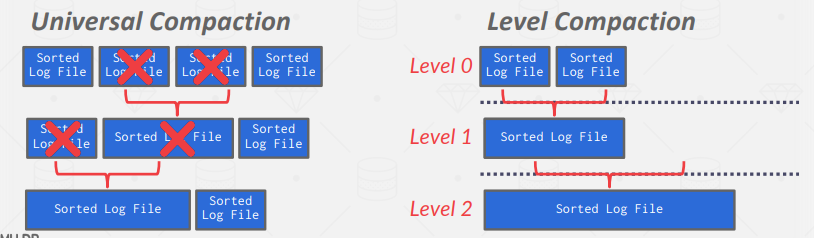
Data Representation
有五种高级数据类型可以存储在元组中:
- Integers
- Examples: INTEGER, BIGINT, SMALLINT, TINYINT.
- Variable Precision Numbers
- Examples: FLOAT, REAL.
- Fixed-Point Precision Numbers
- Examples: NUMERIC, DECIMAL.
- Variable-Length Data
- Examples: VARCHAR, VARBINARY, TEXT, BLOB.
- Dates and Times
- Examples: TIME, DATE, TIMESTAMP.
System Catalogs
为了让 DBMS 能够破译元组的内容,它需要维护一个内部目录,告诉它有关数据库的元数据:
- 表和列,以及这些表上的任何索引;
- 数据库用户及其权限;
- 有关表格及其包含内容的统计信息(如属性的最大值);
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Unity中URP下的添加雾效支持
- 自动化运维神器—ansible详解
- EVE-NG初次启动及WEB客户端访问来了
- OSPF基本概念与配置(完整版)
- 硬盘结构损坏且无法读取恢复方法
- 解决FTP传输慢的问题(ftp传输慢为什么)
- MyBatis XML 映射文件中的 SQL 语句可以分为动态语句和静态语句
- 【Android】使用android studio查看内置数据库信息
- [足式机器人]Part2 Dr. CAN学习笔记-Advanced控制理论 Ch04-16 Robust Controller非线性鲁棒控制器
- 特征融合篇 | YOLOv8 引入长颈特征融合网络 Giraffe FPN