医院信息化-6 大模型与医疗
之前写了一系列跟医疗信息化相关的内容,其中有提到人工智能,但是写的都是原先的一些AI算法基础上的医疗应用。现在大模型出现的涌现推理能力确实让人惊讶,并且出现可商用化的可能性,因此最近一年关于大模型在医疗的应用也开始出现,本章就大模型的一些基本原理、如何微调一个大模型以及大模型与医疗说一下自己的看法,可能存在不准确的地方,望能指出,谢谢。
1 大模型介绍
大多数人对大模型的了解只是知道ChatGPT-3、ChatGPT-3.5、ChatGPT-4、文心一言3.5等大模型,并且其功能就是能够聊天对话。其实大模型不是一个,哪怕是ChatGPT-3也存在多个大模型,如果你有用过ChatGPT的API,你就会了解到ChatGPT的API就有很多个。这时候会存在疑惑就是这些大模型都是干什么的?下面通过大模型分类和国内外一些常见大模型让你认识一下大模型一些基本内容。
1.1 大模型分类
其实当时OpenAI在训练ChatGPT-3时,训练了4个大模型,分别是ada、babbage、curie、davinci,其最大区别就是参数量不同。然后你还发现OpenAI还有DALL·E、Whisper等其它大模型,这时候开始你就要了解不同大模型的作用。很多人喜欢分为以下2类:
- 通用语言大模型:主要处理文本的大模型,像ChatGPT-3、3.5、4、Whisper等属于这类类别,这种类别的大模型一般用于处理对话、文本、翻译、语音等。
- 多模态大模型:多模态大模型简单理解就是能够处理更为复杂的图片、视频的大模型,而OpenAI的DALL·E就是属于多模态大模型,它是基于ChatGPT-3基础上训练出来的。(这里要解释一下,多模态相对于文本来说要复杂的多,现在很多多模态大模型的做法就是让图片也能够变成类似文本的向量化,然后采用文本大模型来做图片特征训练,如DALL·E和visualGLM都采用类似做法)
如果按照更为细致的功能划分,可以分为:
- 文本大模型:处理文本的,如ChatGPT-3、3.5、4。
- 语音大模型:处理语音的,如Whisper大模型
- 文本向量大模型:处理文本向量化,如Embedding大模型
- 审查大模型:处理违规的输入,如Moderation大模型
- 图像大模型:处理图片的,如DALL·E大模型
当然还有很多不同的大模型,这里之所以先了解不同大模型,就是为了让你知道大模型并不是单单只有一种。这里还需要注意一个词“通用”,后续在微调的时候你会知道为什么叫通用大模型。
1.2 国外大模型
我们知道最近一年发布的很多大模型,但是其实很多大同小异,你无需知道太多,只需要通过Hugging face和LMSYS等排行榜,就能够知道哪些大模型。这里简单列举一些国外大模型
| 大模型 | 是否开源 | 文本/多模态 | 公司/组织 |
|---|---|---|---|
| ChatGPT | 否 | 文本 | OpenAI(微软投资) |
| Claude | 否 | 文本 | Anthropic(谷歌投资) |
| LlaMA | 是 | 文本 | Meta |
| DALL·E | 否 | 多模态 | OpenAI(微软投资) |
| MiniGPT | 是 | 多模态 | 沙特的大学研究院 |
1.3 国内大模型
国内在国外某些大模型开源之后,迅速涌现出估计超过100个的大模型,但同样的,有的要么其实只是利用开源微调,有的要么效果其实不佳,国内大模型总结一下就是大厂的基本都差不多,相对于ChatGPT还是有些差距,但是由于涉及中文问题,有时候你可能还是需要利用国内模型可能会取得更好效果(只是因为国内大模型可能有更好更多的中文训练数据,但其大模型推理能力还是没有ChatGPT强)。
| 大模型 | 是否开源 | 文本/多模态 | 公司/组织 |
|---|---|---|---|
| 文心一言 | 否 | 文本 | 百度 |
| 通义千问 | 否 | 文本 | 阿里 |
| 混元 | 否 | 文本 | 腾讯 |
| 百川 | 否 | 文本 | 百川 |
| ChatGLM | 是 | 文本 | 清华大学 |
| visualGLM | 是 | 多模态 | 清华大学 |
国内目前闭源的多模态大模型可能还处于科研阶段,不适合真正商用。
1.4 医疗相关的开源大模型
我们知道,上面列举的大模型其实都是通用大模型,如果我们要在实际某些行业中使用,需要经过微调。那么有哪些开源的医疗大模型,
- ChatMed:一个基于LlaMA-7b大模型,并且使用“中文医疗在线问诊数据集”进行微调训练的医疗知识与回答医学咨询
- XrayGLM:一个基于VisualGLM-6B大模型,并且使用“MIMIC-CXR数据集和OpenI数据集”进行微调训练的X光影像智能诊断报告
2 大模型原理
关于大模型的训练和原理,网上有很多教程和原理说明,这里不会讲数学公式,这里只是让你了解大模型的底层概念,让你能更好的了解大模型。
2.1 输入层+隐藏层+输出层
我们知道AI的算法有很多,但是大模型普遍使用的就是深度学习中的神经网络。如下图:
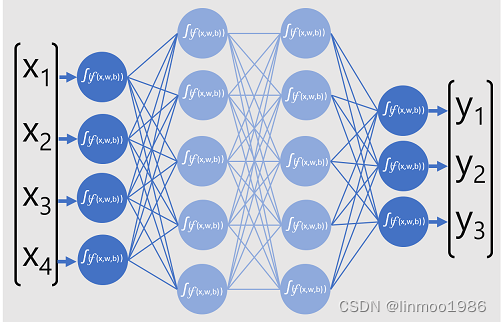
神经网络有3个层级,输入层+隐藏层+输出层,数据通过输入层一直到输出层,就会输出结果
输入层:会有输入的特征+权重参数+偏移量参数,一开始的权重参数和偏移量参数都是随机的。
隐藏层:可以多层,每层使用不一样的激活函数对输入层的数据进行计算。
输出层:有一个输出函数,根据你想要的结果可能是个回归、二分类、多分类的结果选择不同输出函数。
2.2 正向传播
正向传播就是从输入层开始,一直通过隐藏层的激活函数计算,最后使用输出层的输出函数计算,得到输出结果。
损失函数:评判预测的准确性。将输出结果与真实结果通过损失函数评断其准确性,通过计算样本的准确率。
2.3 反向传播
反向传播的作用就是调整权重参数和偏移参数,提高其准确率,那么应该如何提高呢。通过反向传播。这里举一个简单例子,比如通过计算输出结果与真实结果之间的方差,方差越小说明输出结果越准确。那么怎么通过反向传播调整参数呢?
首先我们可以采用一个损失函数如下图:
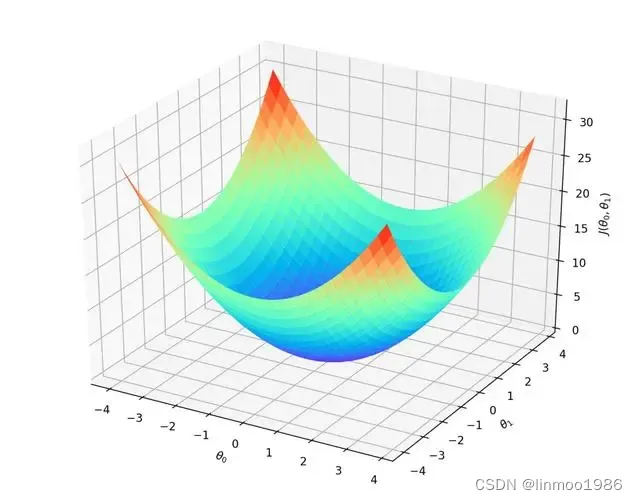
因为我们开始的权重参数和偏移量参数都是随机的,那么这时候通过损失函数计算会得到一个点,这点应该在上图中的某个点。我们要调整的就是不断的往下走,找到损失函数的最底部的那个点,那个点代表输出结果和真实结果最接近的。
当我们第一次正向传播后,得到一个点,这时候就需要做梯度下降算法。
梯度下降算法:就是不断地让你计算得到的点慢慢往下移动,这样输出结果和真实结果就越来越接近,那么得到的模型就越来越准确。
求导:求导的作用就是通过计算某个点的斜率,通过这个斜率,你就可以让你的开始计算的那个点往下移动某个变量(一般通过学习率+某个函数)。采用移动后的点,再次正向传播,再次计算一个新的输出结果,再次通过损失函数计算准确度,然后再次梯度下降算法反向传播,这样不断的循环(这时候设置循环次数或者训练次数)计算,得到越来越准确的模型。
2.3 向量计算
上面只是简单说了一下正向传播和反向传播过程,但是其实真实情况是输入特征、权重参数都是一个很大的向量(如ChatGPT说有1750亿个参数,说的就是这些入参的个数)。通过向量并行计算,这样就更快的计算出结果。
2.4 其它内容
- 函数选择:里面的损失函数、激活函数、输出函数可能会根据不同场景或者不同大模型,他们会选择不同的函数,只有通过实践可以得出那个函数更加适合。
- 训练次数:训练次数这个具体看情况,训练次数越多会越消耗资源,但是训练次数不够,可能模型准确性不高。因此这个也是通过实践做调整。
- 模型推理:我们利用的就是大模型的推理能力,但是大模型的推理能力是一个黑盒或者是一个对于人来说比较难理解的推理。虽然中间隐藏层可以输出中间结果,但是其结果对于人来说可能比较难以理解,这就是为什么大家很担心AI会不受控制的原因,因为其推理能力是一个新的人的推理能力。
3 大模型微调原理
大模型有一个修饰词“通用”,所谓的通用,其实就是推理能力。通过一个简单例子来举例:比如你在建筑行业学习到项目管理的通用能力,但是如果让你去做另外一个行业的管理,虽然有通用项目管理能力,但是由于对那个具体行业的业务不了解,中途会做出一些不在正确的管理,这时候需要你不断学习某个行业的业务再结合你原先的项目管理通用能力,这样你就能很好的管理新的行业。那么大模型微调就是通过你要做的具体场景的数据集输入,加上微调方法,再次训练大模型,让其推理能力来掌握你具体场景。所以微调就是:数据集+微调方法+工具,对大模型进行新的训练,以适合你所需的场景。因此对于大模型的再次训练,其重要的就是数据集和微调方法,可能需要不同调整或增加数据集,然后采用不同微调方法做实践,得出一个更加准确的模型。
3.1 微调方法
目前微调的方法有很多种,不同的微调方法有不同的场景,你需要了解这些微调方法的基本原理和其使用场景,这样你在做选择时,可以知道你应该选择哪些方法。
- 全量微调(Fine-Tuning):全量微调就是对大模型的全量参数进行微调,该方法等同于你需要很大的训练计算。这个方法目前已经基本上不怎么使用。
- 高效微调(PEFT):高效微调就是通过各种方法(包括旁路、Embedding层)的方式,对大模型进行微调,这样做的好处是不需要全量参数,计算量会减少很多。其中包括:LoRA、Prefix Tuning、Prompt Tuning、P-Tuning v2等。这是目前采用较多的微调方式。
- RLHF(强化学习):基于强化学习的方式微调大模型,这个是OpenAI提出来的新的微调模式。也是较为流行的微调方式,目前微软研究院的DeepSpeed Chat的RLHF训练系统最稳定。
3.2 LangChain
随着大模型在不同行业的应用,慢慢地摸索出一套比较通用的应用流程和工具,LangChain就是规范化这个流程,并且里面集成各个流程所需的工具。以下是LangChain的6个模块
Models:大语言模型
Prompts:内置Prompts模板,也就是优化提示语
Chains:思维链,拆分复杂任务
Agents:利用本地工具
Memory:存储交互的内容,用于更好的交互
Index:本地文件交互索引
4 大模型在医疗的应用
医疗中喜欢分为诊前、诊中、诊后、科研等不同过程,这里就不具体区分,而是列举一些详细的应用场景:
- 医疗对话:比如互联医院的导诊功能;AI医疗咨询等功能场景。ChatMed就是这类产品。
- 医疗诊断:比如CDSS,无论是区域医疗的CDSS或者医院的CDSS,一般包括知识库、智能诊断、单病种质控等功能,其中智能诊断和单病种质控是大模型应用重点。
- 医疗影像:通过大模型对医疗影像出智能诊断报告,比如XrayGLM就是这类产品;但是目前看通过大模型还没有超越原先已经有的AI模型,因为这一块目前已经很成熟。
- 个性化医疗:比如临床路径,通过大模型对患者制定特别的治疗方案,做到千人千面。
- 疾病预测:医疗大模型可以通过学习临床数据和生化指标,识别出患病风险高的个体,并进行早期干预和预防。
- 药物研究:使用大模型预测新药物的疗效和副作用,提升药物研发过程;模拟药物代谢途径,优化药物的剂量和给药方式,提高药物的疗效和安全性
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!