扩散模型基础
扩散模型发展至今日,早已成为各大机器学习顶会的香饽饽。本文简记扩散模型入门相关代码,主要参阅李忻玮、苏步升等人所编著的《扩散模型从原理到实战》
文章目录
1. 简单去噪模型
这一小节中,我们将尝试设计一个去噪模型。首先,我们将展示如何给图片加噪。然后,我们将训练一个模型,对加噪图片进行去噪。
1.1 简单噪声可视化
第一步,导入环境
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
第二步,获取训练集样本。此处使用 MNIST 数据集
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root='./mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True) # download=True for the first time
x, y = next(iter(train_dataloader))
print(f'Input shape: {x.shape}')
print(f'Label: {y}')
第三步,设计简单噪声函数
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
return x*(1-amount) + noise*amount
该函数以原始图像为输入,生成与该输入同样维度的随机噪声,并根据参数 amount 将噪声和原始图像混合。
最后,我们在 (0, 1) 之间采样 8 个 amount,看看不同加噪程度下的图片。
集合上面所有代码,如下:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
return x*(1-amount) + noise*amount
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root='./mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
train_dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
x, y = next(iter(train_dataloader))
print(f'Input shape: {x.shape}')
print(f'Label: {y}')
fig, axs = plt.subplots(2, 1, figsize=(9, 4))
axs[0].imshow(torchvision.utils.make_grid(x)[0], cmap='Greys')
amount = torch.linspace(0, 1, x.shape[0])
noised_x = corrupt(x, amount)
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0], cmap='Greys')
plt.savefig('visualize_corrupt.png', dpi=400)
结果如下:

1.2 去噪模型
所谓去噪模型,就是给模型加噪的图片,让模型直接预测真实图片。
我们搭建一个最简单的CV模型。
class BasicUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
self.act = nn.ReLU(inplace=True)
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
h = []
for i, l in enumerate(self.down_layers):
x = self.act(l(x))
if i < 2:
h.append(x)
x = self.downscale(x)
for i, l in enumerate(self.up_layers):
if i > 0:
x = self.upscale(x)
x += h.pop()
x = self.act(l(x))
return x
初始化该模型,并查看参数:
net = BasicUNet()
print(sum([p.numel() for p in net.parameters()]))
输出为30w,可见该模型很小。
下面我们训练该模型:
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
n_epochs = 3
net = BasicUNet()
net.to(device)
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
losses = []
for epoch in range(n_epochs):
for x, y in train_dataloader:
x = x.to(device)
noise_amount = torch.rand(x.shape[0]).to(device)
noisy_x = corrupt(x, noise_amount)
pred = net(noisy_x)
loss = loss_fn(pred, x)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss: 05f}')
plt.plot(losses)
plt.show()
plt.close()
模型训练完以后,我们跟上面加噪过程保持一致,分别设计 8 个不同程度损坏的照片,并让模型预测真实照片
x, y = next(iter(train_dataloader))
x = x[:8]
fig, axs = plt.subplots(3, 1, figsize=(12, 7))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0].clip(0, 1), cmap='Greys')
amount = torch.linspace(0, 1, x.shape[0])
noised_x = corrupt(x, amount)
with torch.no_grad():
preds = net(noised_x.to(device)).detach().cpu()
axs[2].set_title('Network prediction')
axs[2].imshow(torchvision.utils.make_grid(preds)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Corrupted data (-- amount increases -->)')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0].clip(0, 1), cmap='Greys')
本节完整代码如下:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
return x*(1-amount) + noise*amount
class BasicUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
self.act = nn.ReLU(inplace=True)
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
h = []
for i, l in enumerate(self.down_layers):
x = self.act(l(x))
if i < 2:
h.append(x)
x = self.downscale(x)
for i, l in enumerate(self.up_layers):
if i > 0:
x = self.upscale(x)
x += h.pop()
x = self.act(l(x))
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root='./mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
n_epochs = 3
net = BasicUNet()
net.to(device)
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
losses = []
for epoch in range(n_epochs):
for x, y in train_dataloader:
x = x.to(device)
noise_amount = torch.rand(x.shape[0]).to(device)
noisy_x = corrupt(x, noise_amount)
pred = net(noisy_x)
loss = loss_fn(pred, x)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss: 05f}')
plt.plot(losses)
plt.show()
plt.close()
# simple check noise
x, y = next(iter(train_dataloader))
x = x[:8]
fig, axs = plt.subplots(3, 1, figsize=(12, 7))
axs[0].set_title('Input data')
axs[0].imshow(torchvision.utils.make_grid(x)[0].clip(0, 1), cmap='Greys')
amount = torch.linspace(0, 1, x.shape[0])
noised_x = corrupt(x, amount)
with torch.no_grad():
preds = net(noised_x.to(device)).detach().cpu()
axs[2].set_title('Network prediction')
axs[2].imshow(torchvision.utils.make_grid(preds)[0].clip(0, 1), cmap='Greys')
axs[1].set_title('Corrupted data (-- amount increases -->)')
axs[1].imshow(torchvision.utils.make_grid(noised_x)[0].clip(0, 1), cmap='Greys')
plt.savefig('test_v0.png', dpi=400)
结果如下:

1.3 小结
本节中,我们可视化了简单加噪过程,并搭建了简单去噪模型。在经过简单训练后,我们的模型可以成功识别加噪程度较低的图片,令人欣慰。但如何从虚无(完全随机照片)中,生成一张可辨别的图片呢?或许我们可以将预测真实图片的过程设计为迭代过程,一步步去噪(上图从右往左),这就是扩散模型的核心。
2 扩散模型
2.1 采样过程
在得到 1.2 节去噪结果后,一个很自然的想法是,我们可以将去噪过程分成多步,每次预测结果和输入结果进行叠合,如此多步迭代后,期望能变成最左边清晰的图像。该多步去噪的过程叫做采样过程。
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
return x*(1-amount) + noise*amount
class BasicUNet(nn.Module):
def __init__(self, in_channels=1, out_channels=1):
super().__init__()
self.down_layers = torch.nn.ModuleList([
nn.Conv2d(in_channels, 32, kernel_size=5, padding=2),
nn.Conv2d(32, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 64, kernel_size=5, padding=2),
])
self.up_layers = torch.nn.ModuleList([
nn.Conv2d(64, 64, kernel_size=5, padding=2),
nn.Conv2d(64, 32, kernel_size=5, padding=2),
nn.Conv2d(32, out_channels, kernel_size=5, padding=2),
])
self.act = nn.ReLU(inplace=True)
self.downscale = nn.MaxPool2d(2)
self.upscale = nn.Upsample(scale_factor=2)
def forward(self, x):
h = []
for i, l in enumerate(self.down_layers):
x = self.act(l(x))
if i < 2:
h.append(x)
x = self.downscale(x)
for i, l in enumerate(self.up_layers):
if i > 0:
x = self.upscale(x)
x += h.pop()
x = self.act(l(x))
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root='./mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
n_epochs = 3
net = BasicUNet()
net.to(device)
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
losses = []
for epoch in range(n_epochs):
for x, y in train_dataloader:
x = x.to(device)
noise_amount = torch.rand(x.shape[0]).to(device)
noisy_x = corrupt(x, noise_amount)
pred = net(noisy_x)
loss = loss_fn(pred, x)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss: 05f}')
plt.plot(losses)
plt.show()
plt.close()
n_steps = 5
x = torch.rand(8, 1, 28, 28).to(device)
step_history = [x.detach().cpu()]
pred_output_history = []
for i in range(n_steps):
with torch.no_grad():
pred = net(x)
pred_output_history.append(pred.detach().cpu())
min_factor = 1/(n_steps - i)
x = x*(1-min_factor)+pred*min_factor
step_history.append(x.detach().cpu())
print(len(step_history))
fig, axs = plt.subplots(n_steps, 2, figsize=(9, 4), sharex=True)
axs[0, 0].set_title('x (model input)')
axs[0, 1].set_title('model prediction')
for i in range(n_steps):
axs[i, 0].imshow(torchvision.utils.make_grid(step_history[i])[0].clip(0, 1), cmap='Greys')
axs[i, 1].imshow(torchvision.utils.make_grid(pred_output_history[i], cmap='Greys')[0].clip(0, 1), cmap='Greys')
plt.savefig('test_real_v1.png', dpi=400)
结果如下:

左侧为每次迭代时,模型的输入。右侧为基于加噪数据预测真实数据的结果。
可以看到,虽然从虚无中,模型一步步迭代,形成了相对清晰的结果,但这些结果不像是数字。这说明我们的模型还有改进的空间。一个最简单的方法就是增加迭代的步数,期望能有所改善。
我们将采样步数增加到40(并微调噪声代码),采样过程更改为:
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
noise_amount = torch.ones((x.shape[0],)).to(device) * (1-(i/n_steps))
with torch.no_grad():
pred = net(x)
min_factor = 1/(n_steps - i)
x = x*(1-min_factor) + pred*min_factor
fig, ax = plt.subplots(1, 1, figsize=(12,12))
ax.imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')
下图为迭代40次结果,在 64 个样例中,已经可以依稀看到相对清晰的结果。

2.2 上科技
在健美运动中,只靠纯饮食是很难长出超乎常人的大块肌肉的。对此,健美圈大佬会摄入大量睾酮等激素,刺激身体发育。这种走捷径的方法常被叫做“上科技”。此处不是想教各位健身知识,而是借喻 AI 模型设计中走捷径的调包大法。
例如,上述结果很不理想,怎么快速提高模型表现呢?
我们可以 import 进来现成的模型嘛,大家是怎么训练的,咱也照做,保证短期内快速提高。照这个思路,我们需要升级以下几处:
2.2.1 升级模型表征模块
前面说了,我们的 BasicUNet 只有 30w 参数,只是一个玩具模型。我们可以直接 import 一个成熟的业内常用的模型,例如,UNet2DModel
from diffusers import UNet2DModel
net = UNet2DModel(
sample_size=28,
in_channels=1,
out_channels=1,
layers_per_block=2,
block_out_channels=(32, 64, 64),
down_block_types=(
'DownBlock2D',
"AttnDownBlock2D",
"AttnDownBlock2D"
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D",
"UpBlock2D"
)
)
总代码:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
return x*(1-amount) + noise*amount
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root='./mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
a=1
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
n_epochs = 3
net = UNet2DModel(
sample_size=28,
in_channels=1,
out_channels=1,
layers_per_block=2,
block_out_channels=(32, 64, 64),
down_block_types=(
'DownBlock2D',
"AttnDownBlock2D",
"AttnDownBlock2D"
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D",
"UpBlock2D"
)
)
print(sum([p.numel() for p in net.parameters()]))
print(net)
net.to(device)
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
losses = []
for epoch in range(n_epochs):
for x, y in train_dataloader:
x = x.to(device)
noise_amount = torch.rand(x.shape[0]).to(device)
noisy_x = corrupt(x, noise_amount)
pred = net(sample=noisy_x, timestep=0).sample
loss = loss_fn(pred, x)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss: 05f}')
plt.plot(losses)
plt.show()
plt.close()
n_steps = 40
x = torch.rand(64, 1, 28, 28).to(device)
for i in range(n_steps):
noise_amount = torch.ones((x.shape[0],)).to(device) * (1-(i/n_steps))
with torch.no_grad():
pred = net(x)
min_factor = 1/(n_steps - i)
x = x*(1-min_factor) + pred*min_factor
fig, ax = plt.subplots(1, 1, figsize=(12,12))
ax.imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0].clip(0, 1), cmap='Greys')
plt.savefig('test_v2.png', dpi=400)
效果如下:

2.2.2 升级加噪过程
其实有很多现成的加噪函数可以直接调。可以实现,前期加快点,后期加慢点的操作。
我们可以将加噪系数进行可视化:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
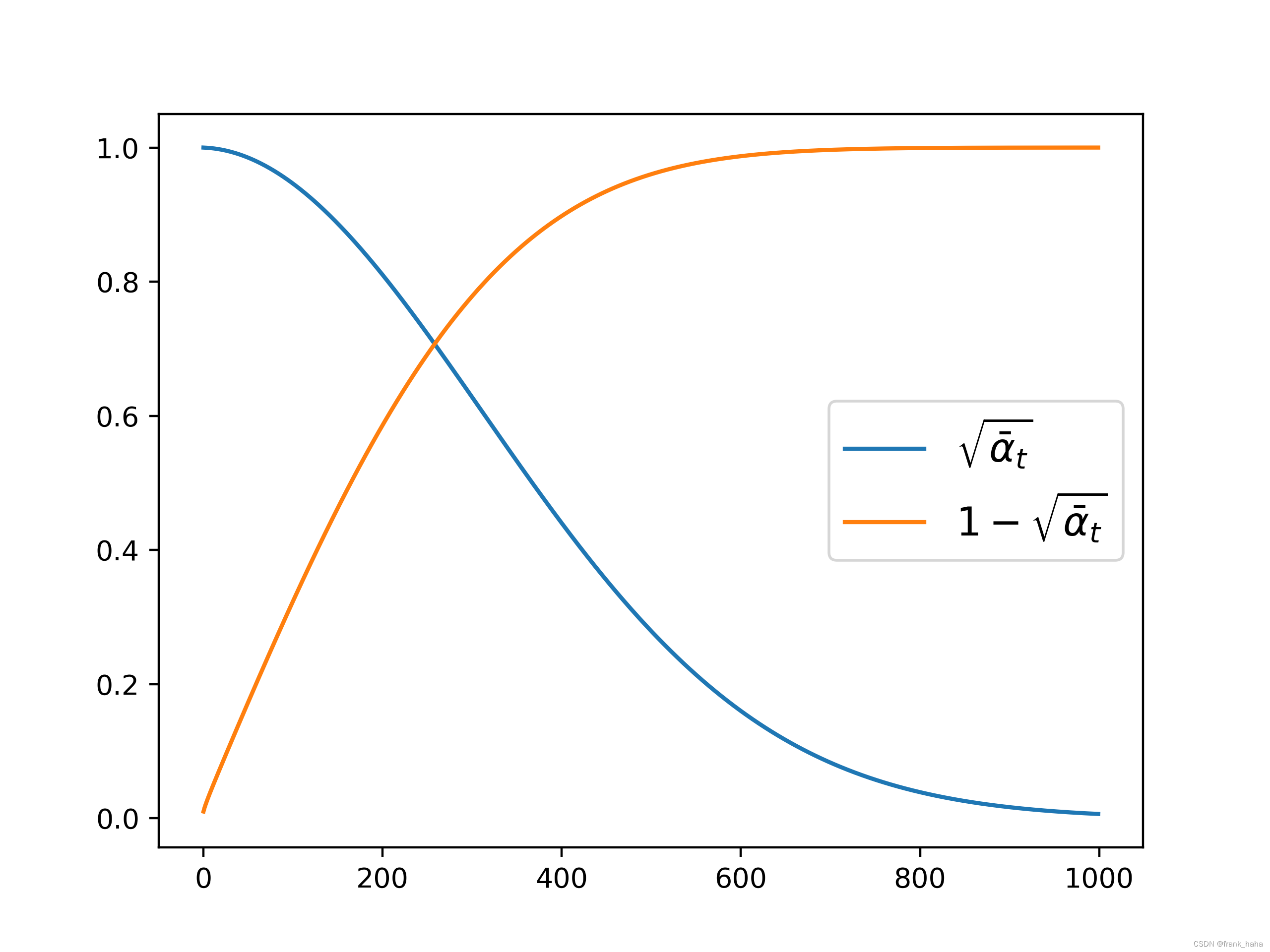
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
plt.plot(noise_scheduler.alphas_cumprod.cpu() ** 0.5, label=r'${\sqrt{\bar{\alpha}_t}}$')
plt.plot((1 - noise_scheduler.alphas_cumprod.cpu())**0.5, label=r'${1-\sqrt{\bar{\alpha}_t}}$')
plt.legend(fontsize="x-large")
plt.savefig('scheduler.png', dpi=400)
可视化加噪后的图片:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root='./mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
batch_size = 128
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
x, y = next(iter(train_dataloader))
x = x.to(device)[:8]
x = x*2. - 1.
print(f'X shape {x.shape}')
fig, axs = plt.subplots(3, 1, figsize=(16, 10))
axs[0].imshow(torchvision.utils.make_grid(x.detach().cpu(), nrow=8)[0], cmap='Greys')
axs[0].set_title('clean X')
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.randn_like(x)
noisy_x = noise_scheduler.add_noise(x, noise, timesteps)
print(f'Noisy X shape {noisy_x.shape}')
axs[1].imshow(torchvision.utils.make_grid(noisy_x.detach().cpu().clip(-1, 1), nrow=8)[0], cmap='Greys')
axs[1].set_title('Noisy X (clipped to (-1, 1))')
axs[2].imshow(torchvision.utils.make_grid(noisy_x.detach().cpu(), nrow=8)[0], cmap='Greys')
axs[2].set_title('Noisy X')
plt.savefig('visualize_noise.png', dpi=400)

需要注意的是,很多时候的随机噪声是以 0 为期望,1 为方差的高斯分布。所以需要将原先的灰度范围(0~1之间)缩放到误差所在区间,即我们的 clean x,需要盖上一层灰(上图最下层最左侧)
2.2.3 改变预测目标
之前,所有的模型都是 去噪 模型。这些模型接收一个加噪的图片,输出真实图片。但实践表明,接收一个加噪图片,输出噪声,这样的预测目标有助于提升模型表现。
之前的推理过程:
加噪图片->模型->真实图片
现在是:
加噪图片->模型->噪声,
加噪图片-噪声->真实图片
相当于多了一步。至于为什么要多着一步,问就是这样精度高,大家都这样做。
下面将上述三条改进措施进行集成:
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from diffusers import DDPMScheduler, UNet2DModel
from matplotlib import pyplot as plt
def corrupt(x, amount):
noise = torch.rand_like(x)
amount = amount.view(-1, 1, 1, 1)
return x*(1-amount) + noise*amount
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
dataset = torchvision.datasets.MNIST(root='./mnist', train=True, download=True, transform=torchvision.transforms.ToTensor())
a=1
batch_size = 100
train_dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
n_epochs = 3
net = UNet2DModel(
sample_size=28,
in_channels=1,
out_channels=1,
layers_per_block=2,
block_out_channels=(32, 64, 64),
down_block_types=(
'DownBlock2D',
"AttnDownBlock2D",
"AttnDownBlock2D"
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D",
"UpBlock2D"
)
)
print(sum([p.numel() for p in net.parameters()]))
print(net)
net.to(device)
loss_fn = nn.MSELoss()
opt = torch.optim.Adam(net.parameters(), lr=1e-3)
losses = []
noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
for epoch in range(n_epochs):
for x, y in train_dataloader:
x = x.to(device)
x = x * 2. - 1.
timesteps = torch.linspace(0, 999, batch_size).long().to(device)
noise = torch.randn_like(x).to(device)
noisy_x = noise_scheduler.add_noise(x, noise, timesteps)
# noise_amount = torch.rand(x.shape[0]).to(device)
# noisy_x = corrupt(x, noise_amount)
pred = net(sample=noisy_x, timestep=timesteps).sample
loss = loss_fn(pred, noise)
opt.zero_grad()
loss.backward()
opt.step()
losses.append(loss.item())
avg_loss = sum(losses[-len(train_dataloader):])/len(train_dataloader)
print(f'Finished epoch {epoch}. Average loss for this epoch: {avg_loss: 05f}')
plt.plot(losses)
plt.show()
plt.close()
torch.save(net, f='model.pt')
# net = torch.load('model.pt')
#
# x, y = next(iter(train_dataloader))
# x = x[:100].to(device)
# x = x * 2. - 1.
#
# timesteps = torch.linspace(0, 999, 100).long().to(device)
# noise = torch.randn_like(x).to(device)
# noisy_x = noise_scheduler.add_noise(x, noise, timesteps)
# with torch.no_grad():
# pred_noise = net(noisy_x, timesteps).sample
# real_pred = noisy_x - pred_noise
# real_pred = (real_pred + 1)/2
#
# fig, ax = plt.subplots(1, 1, figsize=(12,12))
# ax.imshow(torchvision.utils.make_grid(real_pred.detach().cpu(), nrow=10)[0].clip(0, 1), cmap='Greys')
#
# plt.savefig('test_final_real.png', dpi=400)
net = torch.load('model.pt')
x = torch.rand(100, 1, 28, 28).to(device)
x = x * 2. - 1.
timesteps = torch.linspace(0, 999, 100).long().to(device)
noise = torch.randn_like(x).to(device)
noisy_x = noise_scheduler.add_noise(x, noise, timesteps)
with torch.no_grad():
pred_noise = net(noisy_x, timesteps).sample
real_pred = noisy_x - pred_noise
real_pred = (real_pred + 1)/2
fig, ax = plt.subplots(1, 1, figsize=(12,12))
ax.imshow(torchvision.utils.make_grid(real_pred.detach().cpu(), nrow=10)[0].clip(0, 1), cmap='Greys')
plt.savefig('test_final_random.png', dpi=400)
此处采样过程设计了两种。
第一种对应真实的情况:
- sample 100 张图片
- 模拟真实的训练环境,先对输入进行伸缩,映射到期望为 0 ,方差为 1 的区域
- 对这些图片加噪,噪声比例随序列号增加
- 使用模型预测噪声,并将加噪后的图片减去该噪声
- 将照片映射回原来的 (0, 1) 区间
结果如下:

可以看到,在前排,加噪比例较低的情况下,模型能一步作出很好的预测。但后面图片加噪比例变高以后,模型预测质量变差,这凸显了迭代的意义。
此外,模型中的 timesteps 决定了模型在不同阶段对噪声的预测置信度。我们在设计模型时希望模型知晓自己处于迭代的什么阶段。刚开始时,模型更多的,可能只是复原一些背景噪声,随后直接预测具有语义信息的数字,最后对数字进行描边,逐渐精细化。
为验证这一点,我们可以模型同样随机的噪声,并告知模型所处的 timesteps,初始随机噪声减去模型预测噪声,即可看到模型真正想还原的语义:

可以看到:
timesteps接近去噪初始阶段的右下角只是一些背景信息- 中间位置含有部分语义信息
timesteps接近去噪最后阶段的左上角,模型预测显然集中于中心,进行精修,而不是右下角的普遍噪声。
2.3 小结
本节中,我们介绍了常用扩散模型相比简单去噪模型的主要改进之处。其中,迭代采样是最核心的思想,通过迭代采样,我们能够从虚无的噪声背景中逐渐还原出具有语义信息的图片。随后,我们通过调包,对去噪模型进行了全方位升级(又叫上科技)。最后,我们对上述改进之处进行了综合,并通过两个案例向大家介绍扩散模型在不同加噪阶段的还原能力及其蕴含的语义信息。
这篇博客写得囫囵吞枣,只是希望大家能快速上手,感受扩散模型的魅力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【c语言】三子棋
- (Bean实例化的基本流程 )学习Spring的第六天
- K8s(五)ReplicaSet控制器
- 基于SpringBoot的餐饮管理系统的设计与实现
- 街道/楼体LED灯光亮化设计方案及驱动芯片SM16512P的应用与优势
- 人工智能-模型训练之多GPU
- 可视化 | 基于CBDB的唐代历史人物分析
- Python pyttsx3实现语音播报,并保存音频文件
- 探索 Node.js 与 C++ 的绑定:使用 node-addon-api
- 【k8s】Kubernetes技术和相关命令简介