[一文详解]Base64编码,Url Base64编码,UrlEncode编码,你还傻傻分不清吗?
base64编码
由来
Base64算法最早应用于解决电子邮件传输问题,在早期,电子邮件只支持ASCII码字符。
而ASCII码其长度为1个字节,是7位编码,最高位是0,是有符号字符型数。
如果要传输一封带有非ASCII码字符的电子邮件,当它经过部分网关时就可能出现问题,这个网关可能会对非ASCII码字符的二进制位进行调整,即将这个非ASCII码的8位二进制码最高位置设置为0,此时用户收到的邮件就会是一封乱码的了。由此原因产生了Base64算法。
介绍
Base64 是一种用于将二进制数据编码成 ASCII 字符的编码方式。它主要用于在文字环境中传输或存储二进制数据,如在电子邮件、XML 文件、URL 参数等。Base64 编码不是一种加密算法,而是一种编码方式,其主要作用是将二进制数据转换为文本数据,以便更容易在文本协议中处理。
Base64 编码使用 64 个不同的字符来表示二进制数据。这些字符包括大小写字母 A-Z 和 a-z、数字 0-9,以及两个额外的字符通常是 “+” 和 “/”。有时候,为了适应不同的环境,可能还会使用额外的字符,如 “=” 用于填充。
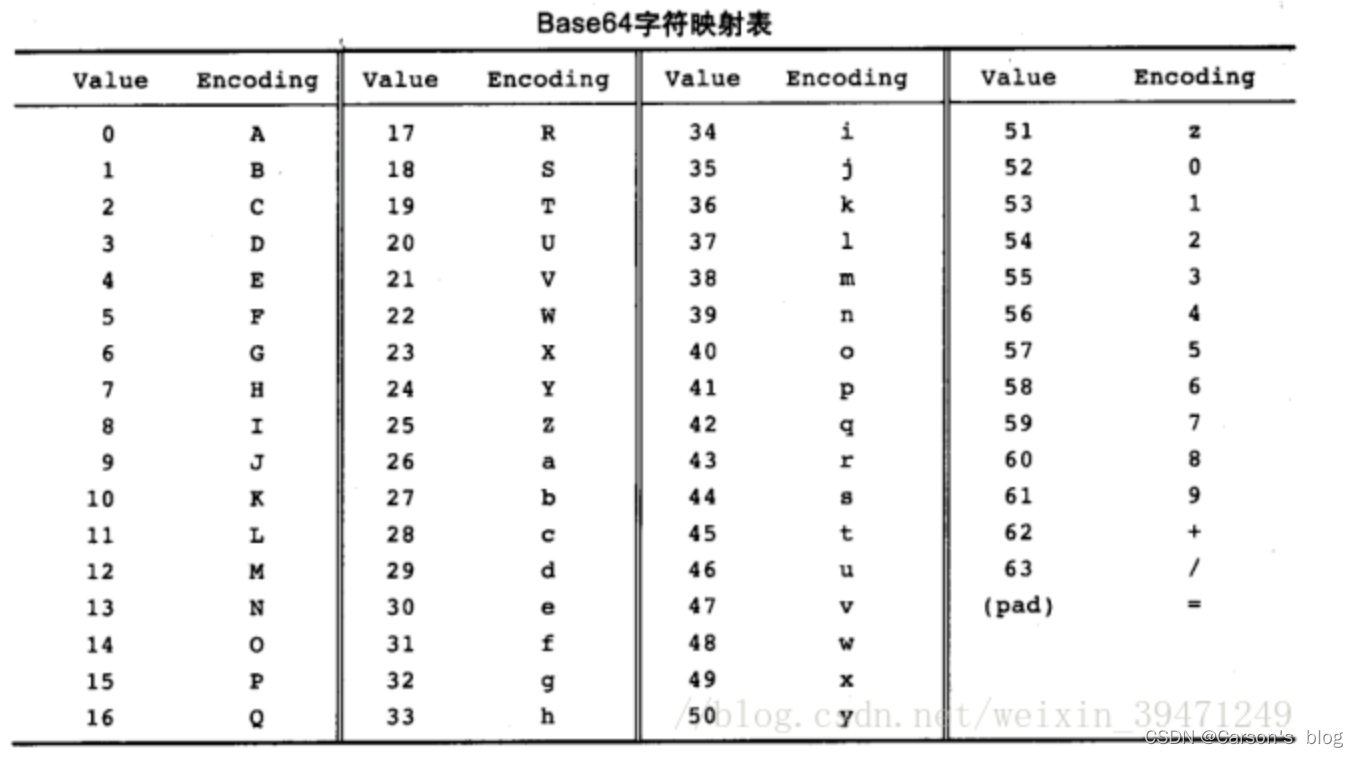
这张字符映射表中,Value指的是十进制编码,Encoding指的是字符,共映射了64个字符,这也是Base64算法命名的来源。映射表的最后一个字符是等号,它是用来补位的。
编解码过程
编码的过程如下:
-
将给定的字符串以字符为单位,分别转换成对应的字符编码(如ASCII码)
-
将每个字符对应的字符编码转换成二进制
-
将二进制码进行分组转换操作:(得到4-6二进制码组)
将原先每3个8位二进制码为一组,将其转换为每4个6位二进制码为一组(其中哪个不足6位时低位补0)。
这是一个分组变化的过程,3个8位二进制码和4个6为二进制码的长度都是24位
-
将获得的4-6二进制码组进行补位,向一组中每个6位二进制码高位补2个0,组成4个8位的二进制码
-
将获得的4-8二进制码组转换为十进制码
-
将获得的十进制码转换成Base64字符表中对应的字符
例子:假设场景,我们需要对"A"进行Base64编码,操作如下:
字符============================A
ASCII编码======================65
二进制码=======================01000001
4-6二进制码====================010000 010000(不足6位,低位补0)
4-8二进制码====================00010000(高位补2个0) 00010000(高位补2个0)
十进制码=======================16 16
字符映射表=====================Q Q = =
注意:
- 如果原始数据的长度不是3的倍数或者说Base64编码出来的串不是4的整数倍,可能会有一些填充字符(通常是 “=”)
- 解码的过程是编码的逆过程,将 Base64 字符转换回原始的二进制数据。
Base64 的主要优点是它能够将二进制数据以文本形式呈现,且编码后的数据长度通常比原始数据小,这对于在文本协议中传输二进制数据是很有用的。然而,它并不是为了安全而设计的,因此不应用于对数据进行加密。
算法演变
计算字符串在转成 Base64 编码后的长度可以通过以下简单的公式来估算:
-
计算原始字符串的字节数(每个字符通常占用一个字节,但是对于 Unicode 字符,可能会占用多个字节)。
-
计算 Base64 编码后的长度:
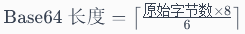
这个公式的解释如下:
- 每个 Base64 字符表示 6 个比特(2^6 = 64)。
- 每组 3 个字节的数据被编码成 4 个 Base64 字符。
- 如果原始字节数不能被 3 整除或者说Base64编码出来的串不是4的整数倍,可能会有填充字符 “=”。
以下是一个简单的 Python 示例,演示如何计算字符串经过 Base64 编码后的长度:
- 使用上面公式计算长度
base64最小长度是4位,每个base64的长度都是4的倍数,不够长度结尾补
=符号
| 原字符 | 每6bit一组 | base64编码 |
|---|---|---|
| a | 1*8/6=2 | YQ== |
| ab | 2*8/6=3 | YWI= |
| abc | 3*8/6=4 | YWJj |
| abcd | 4*8/6=6 | YWJjZA== |
| abcde | 5*8/6=7[] | YWJjZGU= |
请注意,这只是一个估算。实际的编码长度可能会受到编码实现细节的影响,例如是否包含换行符等。
url base64编码
介绍
为了能在HTTP请求中以GET方式传递二进制数,由Base64算法衍生出了Url Base64算法。
UrlBase64 是 Base64 编码的一种变体,主要用于在 URL 中安全地传输二进制数据。
它与标准的 Base64 编码相比,有一些微小的差异,以确保编码后的字符在 URL 中不会引起问题。
与base64的差异
Url Base64主要是替换了Base64字符映射表中的第62、63个字符,也就是将”+”和”/”符号用”-“和”_”代替。至于”=”在Bouncy Castle提供者使用的是”.”代替,而在Commons Codec里则是完全杜绝使用补位符。
UrlBase64 主要有以下两个特点:
- 字符集不同: 在标准的 Base64 编码中,使用字符 “+”, “/”,而这两个字符在 URL 中有特殊的含义,可能会引起歧义或导致 URL 解析错误。为了解决这个问题,UrlBase64 将字符 “+” 替换为 “-”, 将 “/” 替换为 “_”。
- 去掉填充字符: 标准的 Base64 编码在最后可能会使用一个或两个 “=” 字符进行填充,以使编码后的字符串长度是
4的倍数。但是在 URL 中,这些填充字符可能引起问题,因此 UrlBase64 通常去掉填充字符,直接使用编码后的字符串。
总体而言,UrlBase64 是为了适应 URL 中的特殊需求而修改的 Base64 编码。在处理需要在 URL 中传递的二进制数据时,使用 UrlBase64 可以确保编码后的字符串在 URL 中是安全且可靠的。在使用 UrlBase64 解码时,需要在解码之前将 “_” 替换为 “/”,将 “-” 替换为 “+”,并根据需要添加填充字符。
UrlEncode编码
介绍
urlencode 是一种对 URL 进行编码的方法,用于将特殊字符转换为符合 URL 规范的安全字符,以便在网络传输或嵌入到 URL 中时不引起歧义或错误。在Web开发中,这是一个常见的操作,通常在将数据附加到URL参数中时使用。
使用URLEncode原因:
1、字符串数据以url的形式传递给web服务器时,字符串中是不允许出现空格和特殊字符的
2、因为 url 对字符有限制,比如把一个邮箱放入 url,就需要使用 urlencode 函数,因为 url 中不能包含 @ 字符
3、url转义其实也只是为了符合url的规范而已。因为在标准的url规范中中文和很多的字符是不允许出现在url中的。(主要就是消除服务器解析url时的歧义)
原理
URLEncode 编码的基本原理:
-
保留字符: 字母、数字和以下字符被视为“保留字符”:
- _ . ! ~ * ' ( ) ; : @ & = + $ , / ? # [ ]这些字符在 URL 中有特殊含义,但如果需要在 URL 中表示它们的字面值,就需要进行编码。
-
编码原则: 使用百分号(%)后跟两个十六进制数字表示每个字符/每个字节的编码。
所以URL编码(
URL Encoding)也称作百分号编码(Percent Encoding).
例如,浏览器中进行百度搜索“你好”时,链接地址会被自动编码:
(编码前)https://www.baidu.com/s?wd=你好
(编码后)https://www.baidu.com/s?wd=%E4%BD%A0%E5%A5%BD
出现以上情况是因为网络请求前,浏览器对请求URL进行了URL编码(URL Encoding)。
编码规则
URLEncode 规则:
- 将空格转换为加号(+)
- 对0-9、a-z、A-Z之间的字符保持不变
- 对于所有其他的字符,用这个字符的当前当前字符集编码在内存中的十六进制格式表示,并在每一个字节前加上一个百分号(%),如字符“+”是用%2B表示,字符“=”用%3D表示,字符“&”用%26表示,每个中文字符在内存中占两个字节,字符“中”用%D6%D0表示,字符“国”用%B9%FA表示。
- 空格也可以直接用其十六进制编码方式,即用%20表示,而不是将它转换为加号(+)。
特殊字符:
| 特殊字符 | 编码结果 |
|---|---|
| + | %2B |
| = | %3D |
| # | %23 |
| … | … |
总体而言,urlencode 是一个在Web开发中非常实用的,确保在URL传递和构建时不会因为特殊字符而引起问题。
The End!!创作不易,欢迎点赞/评论!!欢迎关注我的GZ号!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【源码】-MyBatis-如何系统地看源码
- 点云从入门到精通技术详解100篇-基于点云配准的无纹理堆叠物体 6D 位姿估计(下)
- instanceof 能够正确判断对象的原理是什么?
- fiddler mock数据返回
- Arduino串口测试
- 3D模型轻量化
- 哪些算法可以用于文字识别?
- 【二叉树】【DFS】104.二叉树的最大深度
- Python办公自动化 – 进行网络监控和处理压缩文件
- Git 忽略提交 .gitignore