抽象工厂模式?就是分门别类
前言
3、4节分别介绍了简单工厂方法与工厂方法,前两节分别学习了简单工厂模式与工厂方法模式,其中,工厂方法模式是为了解决简单工厂模式的扩展问题而出现的,但随之而来的就是其只能够“生产”同一类产品(产品族),如果要增加新的产品族,就比较麻烦,抽象工厂模式就是为解决“如何选择生成多个产品类”的问题而出现的。
什么是抽象工厂模式?
我们首先来看一下抽象工厂模式的定义:**抽象工厂模式(Abstract Factory),提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。**它的UML类图表述如下:
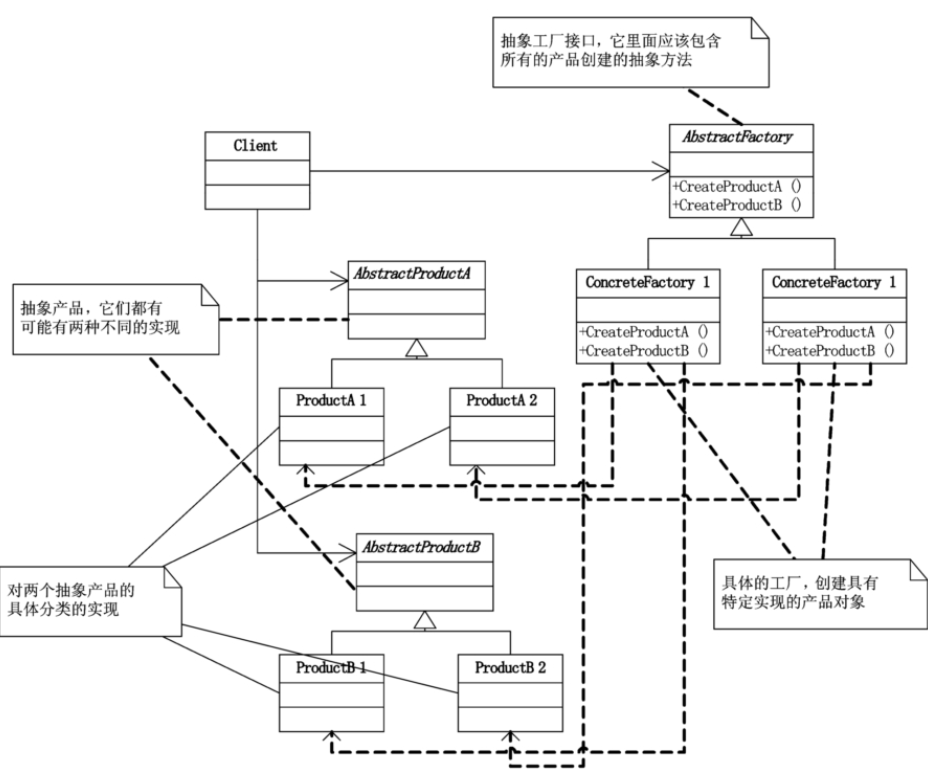
应用
为了能够更好的区分工厂方法模式和抽象工厂模式,我们假定一个应用场景 :“由于不同的客户要求,网站使用的数据库是不一样的,如何设计系统使得可以维护使用Access和使用SQL Server的数据库呢?注意,之后的数据库种类可能会继续增加”。
工厂方法模式
**假设现在系统只有一个User表,**基于工厂方法模式,可以设计系统的UML类图如下:
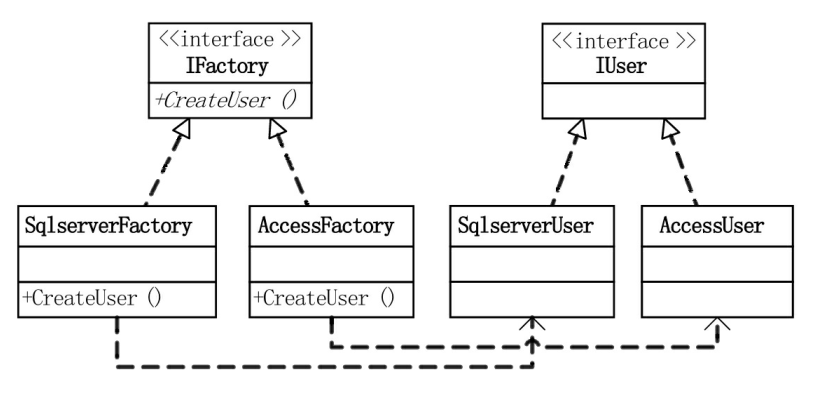
上图中,IFactory是一个接口,所有的数据库类都需要实现该接口;IUser表示操作User表的接口,现在给出了两种方法:新增yoghurt与插入用户。通过这种方式,实现了具体业务对象(User)与底层数据库类型的解耦。如果将具体的业务对象与数据库耦合,系统整体的移植性将大大降低。
User类
User类只有id和name两个字段,实现如下:
public class User {
private int _id;
private String name;
public int getId() {
return _id;
}
public void setId(int id) {
this._id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
IUser接口
因为不同数据库的SQL语句是不一样的,因此该接口是为了解耦客户端与底层数据库。为简易代码,以插入/获取User为例:
public interface IUser {
public void insert(User user);
public User getUser(int id);
}
SqlserverUser类
当底层数据库为Sql时,SQLserver数据库时操作User的代码如下:
public class SqlserverUser implements IUser {
@Override
public void insert(User user) {
System.out.println("在SQL Sever中给User表增加记录");
}
@Override
public User getUser(int id) {
System.out.println("在SQL Sever中根据id获取User表的记录");
return null;
}
}
AccessUser类
当底层数据库为Access,AccessUser操作User的实现代码如下:
public class AccessUser implements IUser {
@Override
public void insert(User user) {
System.out.println("在Access中给User表增加记录");
}
@Override
public User getUser(int id) {
System.out.println("在Access中根据id获取User表的记录");
return null;
}
}
工厂接口
所有数据库都得实现该工厂接口:
//工厂方法
public interface IFactory {
IUser createUser();
}
SqlserverFactory类
SqlserverFactory实现工厂接口,从而创建出一个SQLserverUser:
public class SqlserverFactory implements IFactory {
@Override
public IUser createUser() {
return new SqlserverUser();
}
}
AccessFactory省略。
Client1
当需要更换数据库时,修改一条语句即可:
//工厂方法实现的客户端
public class Client1 {
public static void main(String[] args) {
User user = new User();
//换成AccessFactory()即可更换数据库
IFactory factory = new SqlserverFactory();
IUser iUser = factory.createUser();
iUser.insert(user);
iUser.getUser(1);
}
}
结果如下:

从上面可以看出,此时更换数据库直接替换一条语句即可,从而实现了业务与数据的解耦。
但是如果除了User表,还有Department表?或者更多的表呢?可想而知,随着业务的迭代,代码将会不断膨胀,那么能不能优化一下呢?
抽象工厂模式
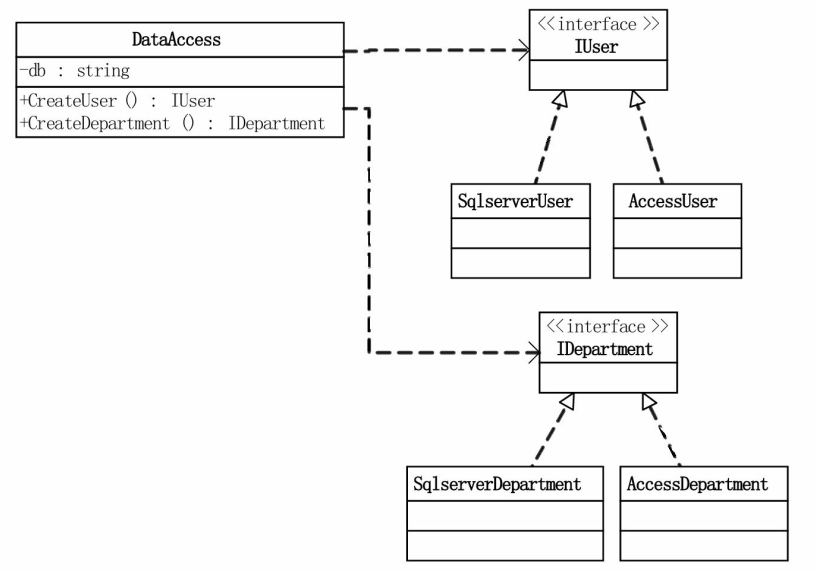
在实际开发过程中,必然会存在多个数据表、多个产品类(即可能存在多个底层数据库),这时,工厂模式就变成了抽象工厂模式基于抽象工厂模式的UML类图如下:
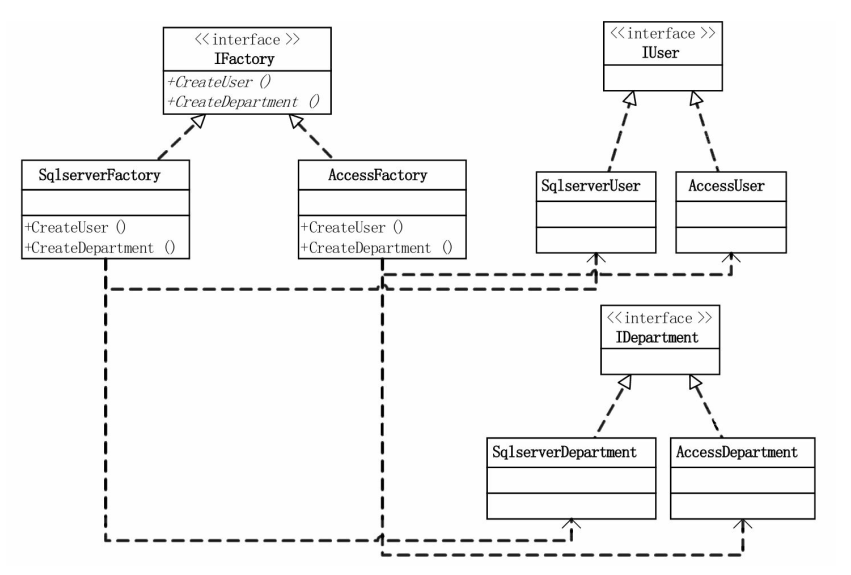
从上面的UML可以看出,IUser与IDepartment都有两种以上的不同实现,这也是将该设计模式称之为抽象工厂模式的原因,并且工厂接口也有两种以上的实现,其主要目的是为了能够获得对应的类实例,例如SqlServerFactory就是获得一个基于Sql数据库的操作实例。
采用抽象工厂有两个好处,其中最大的好处是便于可以创建一组相关的产品对象,而不仅仅是单个对象,从而便于更换产品类时,在我们的例子中,可以很方便地更换具体的数据库实现;另外,抽象工厂模式将客户端代码与具体实现分离,使得代码更易于扩展和维护。接下来让我们来看看代码实现吧。
添加Department类
public class Department {
private int _id;
private String departmentName;
public int getId() {
return _id;
}
public void setId(int id) {
this._id = id;
}
public String getName() {
return departmentName;
}
public void setName(String name) {
this.departmentName = name;
}
}
IDepartment类、AccessDepartment类等省略,详见源码。
修改IFactory
需要修改IFactory类,添加department相关的代码
public interface IFactory {
IUser createUser();
IDepartment createDepartment();
}
Client2
import com.whitedew.abstractfactory.impl.AccessFactory;
//抽象工厂模式
public class Client2 {
public static void main(String[] args) {
User user = new User();
Department department = new Department();
//SqlserverFactory();
IFactory factory = new AccessFactory();
IUser iUser = factory.createUser();
iUser.insert(user);
iUser.getUser(1);
IDepartment iDepartment = factory.createDepartment();
iDepartment.insert(department);
iDepartment.getDepartment(1);
}
}
结果如下:
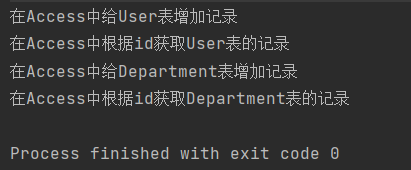
只有一个User类和User操作类的时候,是只需要工厂方法模式的,但如果有多个类并且又多个数据库操作时,工厂方法就不适用的。所以解决这种涉及到多个产品系列的问题,就需要使用抽象工厂方法。
抽象工厂+简单工厂
难道抽象工厂就这么完美,没有缺点了吗?
仔细分析上述代码,如果还需要增加一个业务表呢?比如Price表,需要做些什么?
增加三个类:IPrice、SqlserverPrice、AccessPrice;
修改三个地方:IFactory、SqlserverFactory、AccessFactory;
而且如果使用的数据库种类越多,需要增加和修改的地方就更多。没错。抽象工厂方法也有一个缺点,那就是增加新产品类需要更改抽象工厂接口,这会导致抽象工厂的改变和工厂实现的改变,增加了代码的复杂度(虽然很多时候这个代价都是可以接受的)。
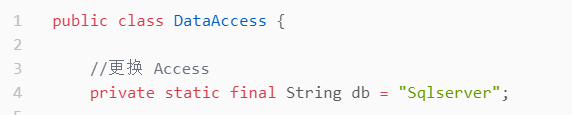
在这种情况下,可以**使用简单工厂模式,**将IFactory、SqlserverFactory、AccessFactory合并为一个类——DataAccess类,将显式的数据库选择逻辑收敛其中:
DataAccess类:
public class DataAccess {
//更换 Access
private static final String db = "Sqlserver";
public static IUser CreateUser() {
IUser result = null;
switch (db) {
case "Sqlserver":
result = new SqlserverUser();
break;
case "Access":
result = new AccessUser();
break;
}
return result;
}
public static IDepartment CreateDepartment() {
IDepartment result = null;
switch (db) {
case "Sqlserver":
result = new SqlserverDepartment();
break;
case "Access":
result = new AccessDepartment();
break;
}
return result;
}
}
这时只需要在客户端调用DataAccess类即可:
//抽象工厂加简单工厂
public class Client3 {
public static void main(String[] args) {
User user = new User();
Department department = new Department();
IUser iUser = DataAccess.CreateUser();
iUser.insert(user);
iUser.getUser(1);
IDepartment iDepartment = DataAccess.CreateDepartment();
iDepartment.insert(department);
iDepartment.getDepartment(1);
}
}
使用抽象工厂+简单工厂,可以很大的简化代码,并且将修改和增加的地方都收敛至一处,一定程度上降低了开发的难度。
反射机制
在DataAccess中,如果需要更换数据库,需要手动修改,并且其中还有switch-case之类的语句:
通过反射机制可以解决这个问题。有关反射机制,简单来说,就是在程序运行的过程中,根据类属性,去动态地创建对应的类实例,而不需要像上面这样通过硬编码的方式来选择数据库。详情请见:链接
Java中反射可以这么实现,参考简说设计模式:
public class DataAccess {
private static final String name = "com.whitedew.abstractfactory.impl";
private static final String db = "Access";//要更换,换成Sqlserver即可
public static IUser createUser() throws InstantiationException, IllegalAccessException, ClassNotFoundException {
String className = name + "." + db + "User";
return (IUser) Class.forName(className).newInstance();
}
public static IDepartment createDepartment() throws InstantiationException, IllegalAccessException, ClassNotFoundException {
String className = name + "." + db + "Department";
return (IDepartment) Class.forName(className).newInstance();
}
}
可见,通过反射技术,去除了代码里的if-else、switch-case分支,简化了代码。不过似乎还是觉得意犹未尽,如果我要更换更换某一个数据库不还是需要重新更改代码然后编译吗?事实真是这样?
上述代码中,**包名与具体的数据库类型都是使用字符串类型,**这也就意味着这两者是可以进行实时读取的。我们可以新建一个配置文件,在其中注明所要使用的数据库类型,当我们需要更换数据库时,都不需要重新编译,便可进行无缝切换。
其实,Java的Spring框架就在很多地方使用到了抽象工厂模式,有兴趣地小伙伴可以去一探究竟。
总结
现在我们来对三种工厂模式做一个总结:
- 简单工厂模式:通过接收的参数不同,来返回不同的对象实例,实现了客户端与具体业务对象的解耦;
- 工厂方法模式:在简单工厂模式的基础上进一步完善,符合开放-封闭原则;
- 抽象工厂模式:抽象工厂是应对多层业务耦合所出现的,典型的例子就是上述的数据与业务对象;
这三种模式在实际开发中非常实用,有关三者的取舍需要根据实际情况来确定,甚至有的时候需要进行重构。工厂模式和抽象工厂模式都是创建型设计模式,它们的主要区别在于创建对象的抽象程度和所创建的对象类型。如果只需要创建单个对象,则可以使用工厂模式,如果需要创建一组相关的对象,则可以使用抽象工厂模式。
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SQL语言
- java验证手机号
- 面试百问之count(1) 和 count(*) 区别是什么?
- 刷卡打印机,后台更换别人绑定的卡,无法生效,怎么解决?
- Java之网络编程
- 阿里云GPU服务器ECS实例规格详细说明
- OpenHarmony应用开发-进程间通讯
- 二氧化硅行业分析:预计2029年将达到81亿美元
- cadence SPB17.4 - allegro - CAM350_V10.7CN 引入槽孔(.rou)文件报错问题的优雅解决思路
- Redis数据删除策略(惰性删除+定期删除)