【S2ST】UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units
UnitY: Two-pass Direct Speech-to-speech Translation with Discrete Units
Abstract
Direct S2ST 由于简单的pipeline,从而实现了更快的推理速度,本文介绍了UnitY, 一个两阶段的方法。首先产生文本的表示,然后预测音频的离散序列。应用了subword prediction在第一阶段的decoder,新颖的第二阶段的decoder结构设计和搜索策略,从而实现了模型性能的提升。为了利用大量未标记的文本数据,本文基于自监督去噪自动编码任务预训练第一阶段文本解码器。在各种数据尺度上对基准数据集的实验评估表明,UnitY 比speech-to-unit翻译模型高出 2.5-4.2 ASR-BLEU,解码速度提高了 2.83×。我们表明,即使在第二阶段解码预测频谱图时,所提出的方法也能提高性能。然而,与这种情况相比,预测离散单元实现了 2.51× 的解码加速。
Introduction
传统的S2ST是级联的系统:ASR+MT+TTS。随着sequence-to-sequence模型的出现,可以实现直接的S2ST,相比级联系统,拥有简洁的pipeline和低延时。但是由于数据的稀缺,direct S2ST模型的效果离级联系统还有差距。在S2TT领域,数据稀缺可以通过leveraging pre-training, multi-task learning, pseudo labeling和knowledge distillation缓解。因此,直接 S2TT 模型的翻译质量接近级联 S2TT 模型的翻译质量。这些措施在S2ST任务中也取得了不错的效果。
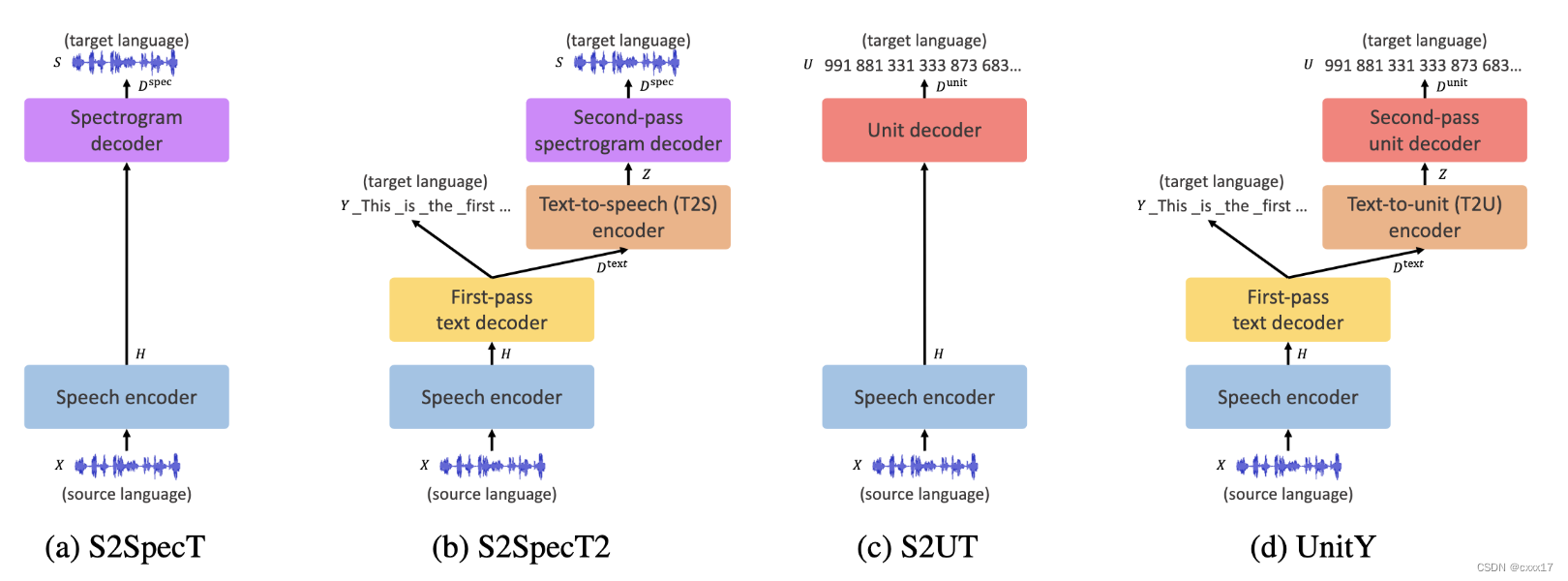
最近的工作提出建模Hubert离散的单元,而不是连续的语音表示。S2UT缩短了target的长度,提高了训练和推理的速度。离散的unit可以接声码器,生成音频。另一方面,Translatotron2 明确地将目标表示分解为语言和声学表示。前者预测音素,后者以连续的linguistic 表示合成target的谱。
本文提出的方法,同时借鉴了S2UT model和Translatotron2的优点。与Translatotron2不同的是,UnitY建模subwords而不是phoneme,同时建模离散的声学单元。为了获得更好的翻译质量和解码效率,UnitY用一个比较深的text decoder, 一个浅层的unit decoder。我们进一步在两个解码器之间引入了一个文本到文本单元 (T2U) 编码器,以弥合文本和声学表示之间的差距。随着大规模预训练的成功,我们利用未标记的文本有效地预训练具有多语言 BART (mBART) 的first pass text encoder, 应用subword.
大量的实验表明UnitY的优越性,翻译质量:UnitY实现了4.2, 3.7,2.5的asr BLEU的提升(在the Fisher Es→En,CVSS-C, multi-domain En?Es),其次,UnitY 与S2UT 和改进后的Translatotron2 的模型上实现了 2.83× 和 2.51× 的解码加速。
UnitY
X表示source speech输入,Y = (y1, . . . , yM ) and U = (u1, . . . , uL)表示相应的文本翻译和离散序列,注意U中不包含duration信息,以防导致坍塌。
Architecture
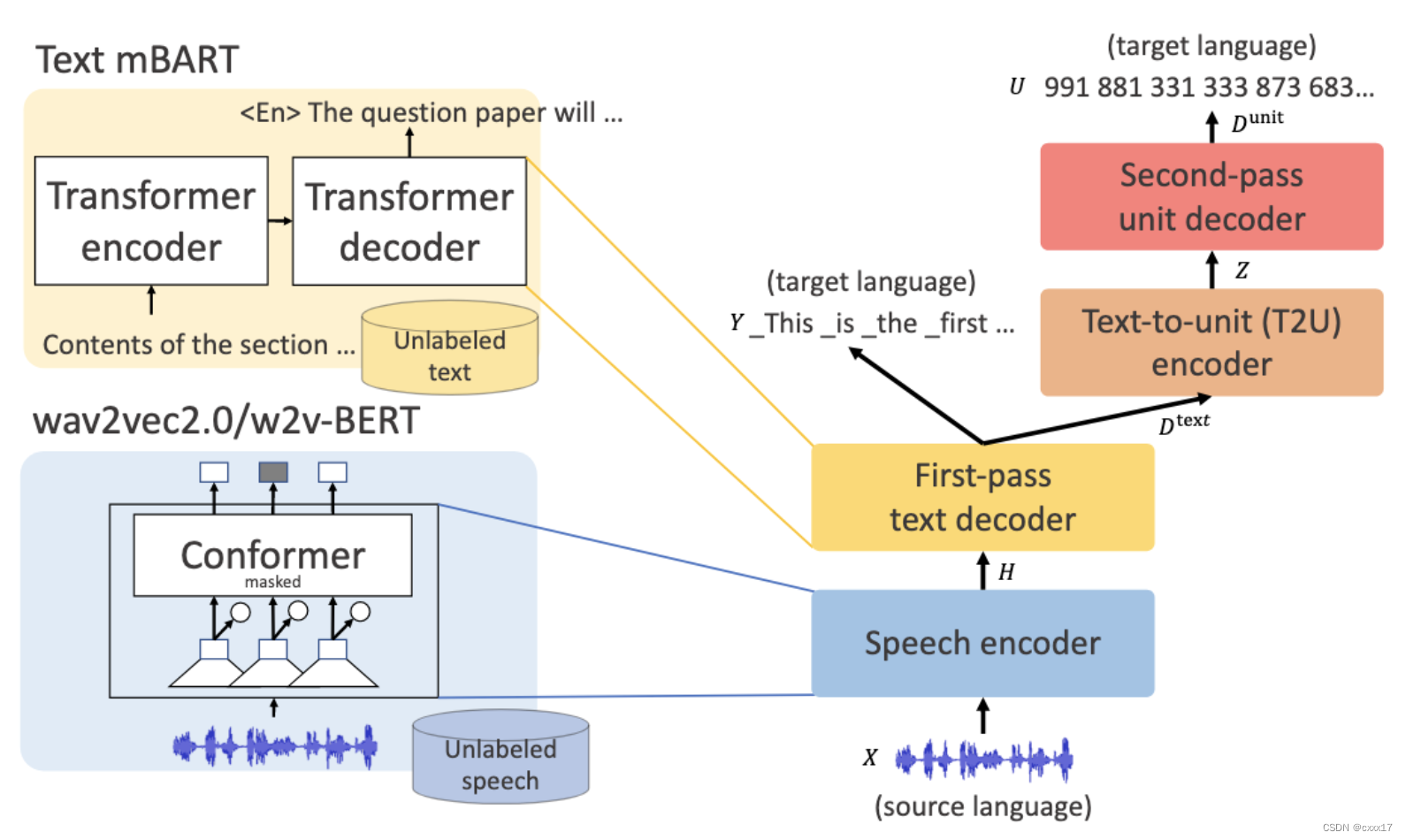
包括4个部分,speech encoder, first pass text encoder, text-to-unit encoder和second pass decoder. 相比tranlatotron2 我们做了5个结构的调整,1)生成subwords而不是phoneme,2)生成离散单元,而不是连续的谱,从而绕过duration的建模3)将BLSTM替换成Transformer,4)引入T2U模块,5)讲更多的模型容量分配给first-pass text decoder.
- Speech encoder
conformer based wav2vec/w2v-BERT - First pass text encoder
基于speech encoder的输出,生成target speech的subwords,Loss如图
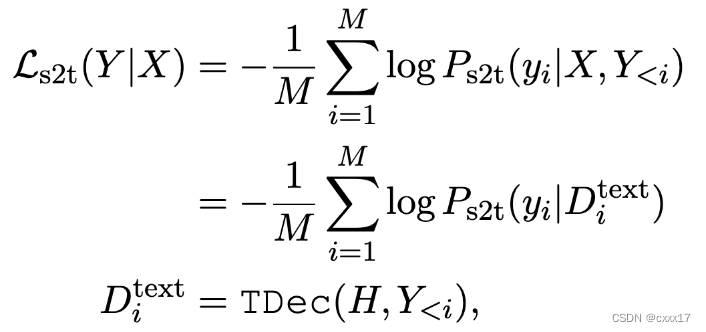
由于cross attention的作用,认为 D t e x t D^{text} Dtext除了包含内容信息以外,还包含了声学信息。用subwords替换phoneme有5个好处。
1)序列长度变短了,训练和推理效率增加了
2)使用大的词表,提升了翻译质量
3)文本的输出帮助用户理解翻译内容
4)可以扩展到更多的target language,不需要准备分别的G2P
5)能直接产生可读的文本,而不需要经过WFST后处理 - Text-to-unit encoder
不改变序列长度,负责建模text->unit - Second pass decoder
基于Text-to-unit encoder的输出,产生unit tokens, 后面再接unit vocoder.
训练的Loss总的下来:
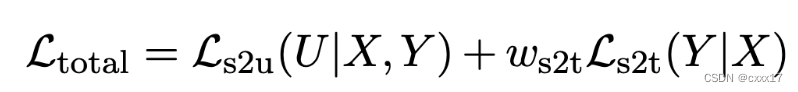
Text decoder pre-training
Speech encoder用wav2vec2.0, unit decoder 用mBART初始化。为了充分利用未标记的文本数据,我们使用未标记的文本数据预训练的基于文本的 mBART (t-mBART) 初始化 UnitY 的text decoder, unit decoder 用 mBART 初始化。
Search algorithm
两个beam search在first pass decoder 和 second pass decoder。第一阶段的beam size大一点会比较好。
Deep-shallow two-pass decoders
分配给First pass decoder更多的参数,second pass decoder更少的参数,这样的分配提升了翻译质量,和推理速度(因为第一阶段预测的序列比较短)。
Experimental setting
Data
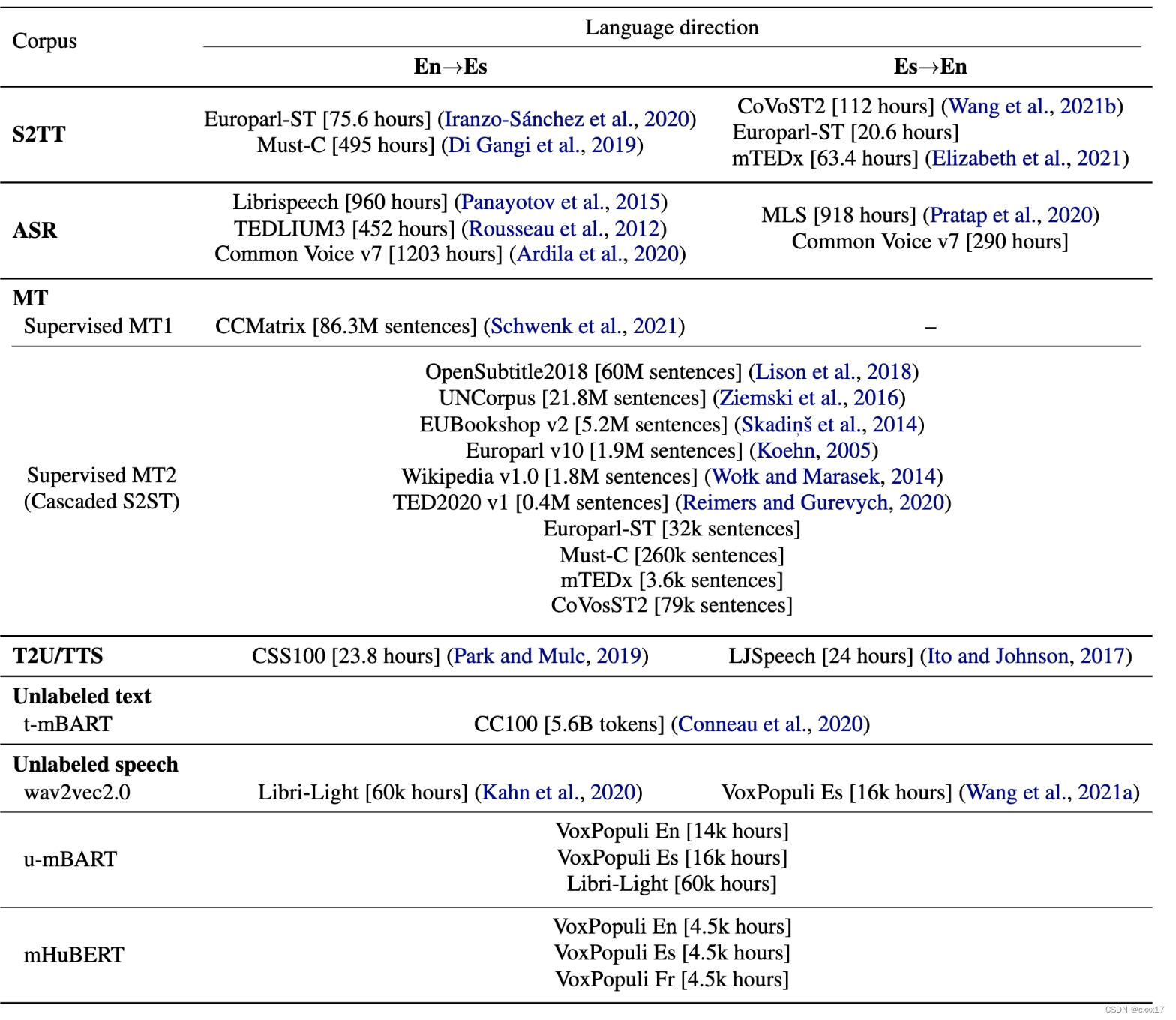
Pre-processing
Speech
Target speech 22k, extract unit token in 16k, 应用了句子级别的cmvn
Discrete units
English用librispeech训的Hubert 100类, 其他的语言用multilingual hubert抽100类
Text
小写文本数据并删除除撇号之外的所有标点符号
Data filtering
去掉过度生成的样本
Pre-training

Baseline
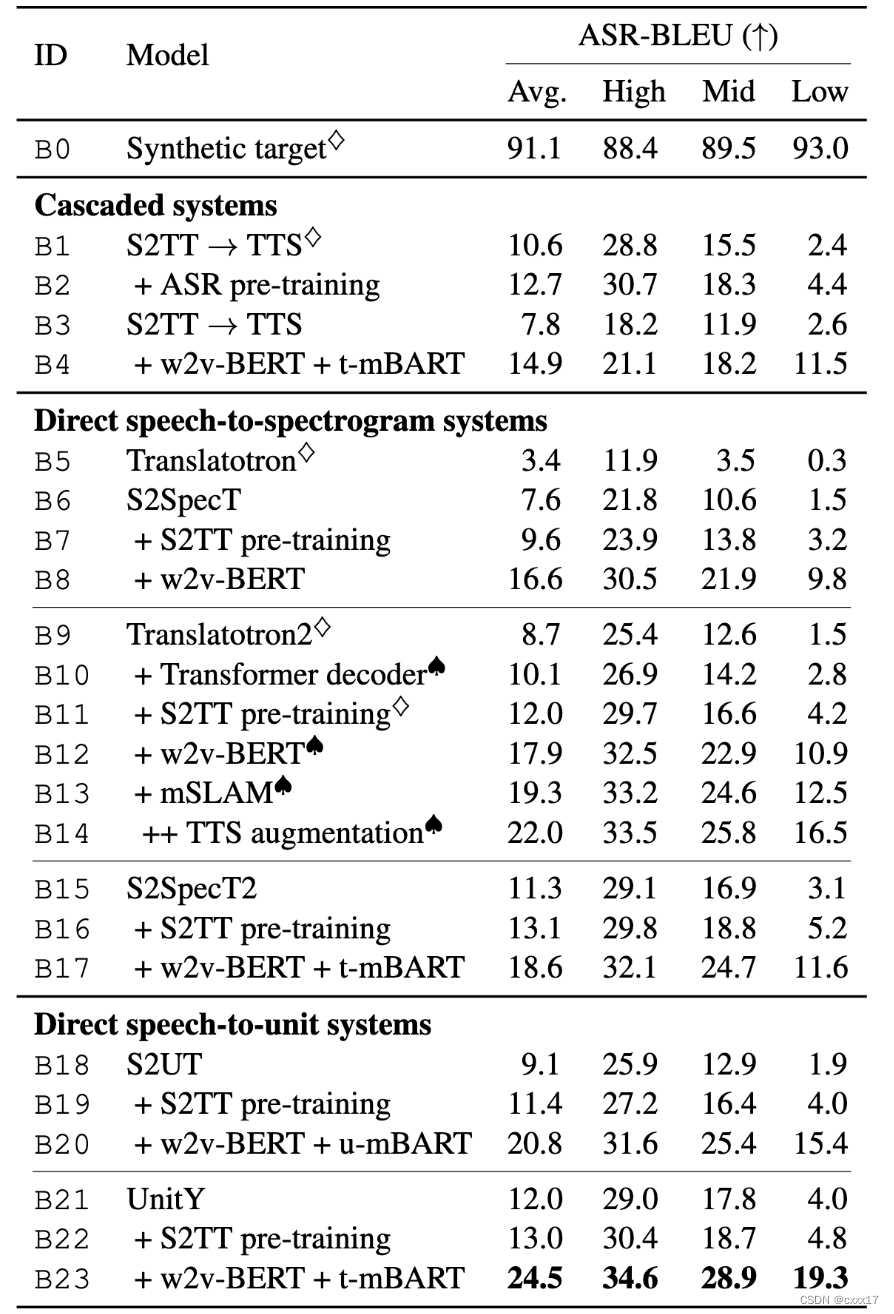
两个级联 S2ST 系统和四个直接 S2ST 系统。
级联:ASR->MT->TTS, S2TT->TTS
直接:
Architecture
见附录G
Evaluation
ASR-BLEU
Experimental results
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【大数据OLAP引擎】StartRocks存算分离
- 面试之线程状态
- 10种网站安全隐患及防御方法
- 黑马程序员springboot3和vue3中big-event(大事件)项目中更新用户密码功能vue代码的实现
- go从0到1项目实战体系四:函数
- 单例模式及数组也能无锁:AtomicIntegerArray
- 补题与总结:AtCoder Beginner Contest 333 D、E
- 使用smartctl记录MSATA使用信息及导出文件内容为txt,批量将txt导入excel
- 技术知识点:Treeshaking是什么?
- 阿里云和腾讯云2核2G3M服务器上传速度多少?