ViT的极简pytorch实现及其即插即用
发布时间:2023年12月29日
先放一张ViT的网络图
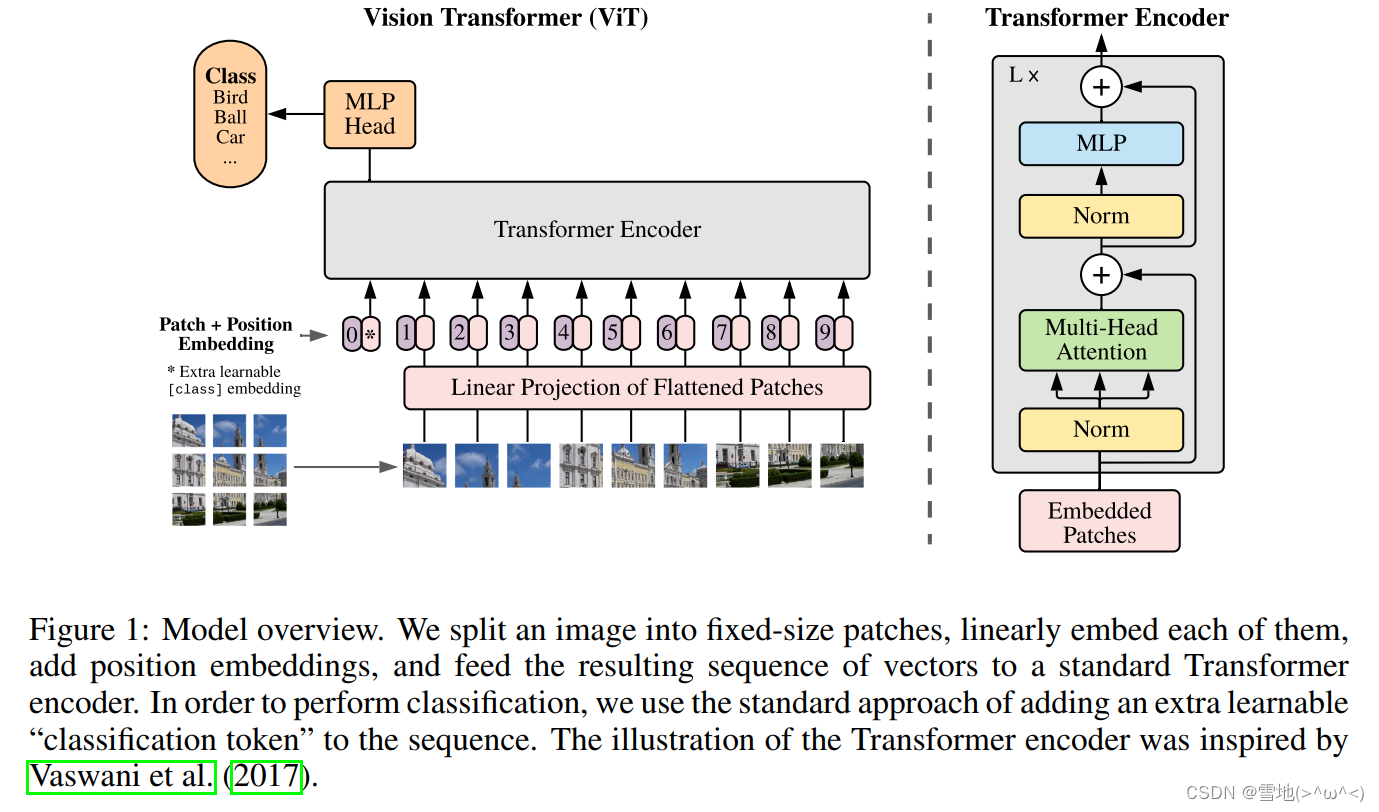
可以看到是把图像分割成小块,像NLP的句子那样按顺序进入transformer,经过MLP后,输出类别。每个小块是16x16,进入Linear Projection of Flattened Patches, 在每个的开头加上cls token和位置信息,也就是position embedding。
去掉数据读取部分,直接上一个极简的ViT代码:
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)## 对tensor张量分块 x :1 197 1024 qkv 最后是一个元祖,tuple,长度是3,每个元素形状:1 197 1024
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size) # 224*224
patch_height, patch_width = pair(patch_size) # 16 * 16
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
# (b,3,224,224) -> (b,196,768) 14*14=196 16*16*3=768
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim), # (b,196,1024)
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img) # img 1 3 224 224 输出形状x : 1 196 1024
b, n, _ = x.shape # 1 196
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b) # (1,1,1024)
x = torch.cat((cls_tokens, x), dim=1) # (1,197,1024)
x += self.pos_embedding[:, :(n + 1)] # (1,197,1024)
x = self.dropout(x) # (1,197,1024)
x = self.transformer(x) # (1,197,1024)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0] # (1,1024)
x = self.to_latent(x) # (1,1024)
return self.mlp_head(x) # (1,1000)
if __name__ == '__main__':
v = ViT(
image_size = 224,
patch_size = 16,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
print(preds.shape)
去掉cls和最后的全连接分类头,变成即插即用的模块:
import torch
from torch import nn
from einops import rearrange
from einops.layers.torch import Rearrange
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)## 对tensor张量分块 x :1 197 1024 qkv 最后是一个元祖,tuple,长度是3,每个元素形状:1 197 1024
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, dim = 1024, depth = 3, heads = 16, mlp_dim = 2048, dim_head = 64, dropout = 0.1, emb_dropout = 0.1):
super().__init__()
channels, image_height, image_width = image_size # 256,64,80
patch_height, patch_width = pair(patch_size) # 4*4
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width) # 16*20
patch_dim = 64 * patch_height * patch_width # 64*8*10
self.conv1 = nn.Conv2d(256, 64, 1)
self.to_patch_embedding = nn.Sequential(
# (b,64,64,80) -> (b,320,1024) 16*20=320 4*4*64=1024
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim), # (b,320,1024)
)
self.to_img = nn.Sequential(
# b c (h p1) (w p2) -> (b,64,64,80) 16*20=320 4*4*64=1024
Rearrange('b (h w) (p1 p2 c) -> b c (h p1) (w p2)', \
p1 = patch_height, p2 = patch_width, h = image_height // patch_height, w = image_width // patch_width),
nn.Conv2d(64, 256, 1), # (b,64,64,80) -> (b,256,64,80)
)
# 位置编码
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
def forward(self, img):
x = self.conv1(img) # img 1 256 64 80 -> 1 64 64 80
x = self.to_patch_embedding(x) # 1 320 1024
b, n, _ = x.shape # 1 320
x += self.pos_embedding[:, :(n + 1)] # (1,320,1024)
x = self.dropout(x) # (1,320,1024)
x = self.transformer(x) # (1,320,1024)
x = self.to_img(x)
return x # (1 256 64 80)
if __name__ == '__main__':
v = ViT(image_size = (256,64,80), patch_size = 4,)
img = torch.randn(1, 256, 64, 80)
preds = v(img) # (1, 1000)
print(preds.shape)
文章来源:https://blog.csdn.net/qq_36563273/article/details/135283077
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 呼叫中心质量监控
- 基于Springboot+Mybatis+微信小程序实现小型运动管理平台
- Java算法 leetcode简单刷题记录2
- 新能源汽车制造设备状态监测:无线温振传感器的应用
- Kafka下沉到HDFS报错
- Leetcode—859.亲密字符串【简单】
- 有效网络安全意识的正确策略
- 用git bash调用md5sum进行批量MD5计算
- 超实用+全覆盖!17个大分类,近500款主流实用精品AI工具导航,太贴心了!总有一款适合你。
- 2024年预测,这五类业务欺诈威胁将激增