关于html导出word总结一
发布时间:2024年01月13日
总结
测试结果不理想,html-to-docx 和? ?html-docx-js?最终导出的结果 都 差强人意,效果可以见末尾的附图
环境
?"electron": "24.3.0"
依赖库
html-docx-js
html-to-docx
file-saver
测试结果
?html-docx-js?
这个库在前端? 【我】 无法使用,在用的时候,库本身的代码里需要全局变量 __dirname, 这个在前端浏览器环境好像是没有的,是属于node环境的变量
html-to-docx
这个可以用,但效果不好,最终效果见下方附图,这里附上使用代码,下面的代码文件可以直接使用。
import { saveAs } from 'file-saver'
import HTMLtoDOCX from 'html-to-docx'
const printStyles = `
@media print {
body, html {
margin: 0;
padding: 0;
}
}`
function getHtmlContent(ctrlId) {
// 获取整个页面的 HTML
const pageHTML = document.documentElement.outerHTML
// 使用 DOMParser 解析 HTML
const parser = new DOMParser()
const doc = parser.parseFromString(pageHTML, 'text/html')
// 找到 #printableArea
const printableArea = doc.querySelector(ctrlId)
if (!printableArea) return ''
// 隐藏 #printableArea 以外的所有元素
doc.body.childNodes.forEach(node => {
if (node !== printableArea) {
if (node.style) node.style.visibility = 'hidden'
}
})
// 删除所有 .no-print 元素
const noPrintElements = printableArea.querySelectorAll('.no-print')
noPrintElements.forEach(el => el.remove())
// 获取所有的 style 和 link 标签
const styles = doc.querySelectorAll('style, link[rel="stylesheet"]')
return `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Document</title>
<style>
${Array.from(styles).map(style => style.outerHTML).join('\n')}
</style>
<style>
${printStyles}
</style>
</head>
<body>
${printableArea.outerHTML}
</body>
</html>
`
}
/**
* 这个接口可以把一个 HTML 字符串转成 docx 文件
* 但经过测试,在某些html页面下,存在导出的 docx 文件无法打开的问题,比如整个页面都是table套table...
* 通过HTMLtoDOCX导出的word,word内容版式是非常不理想的
* 先保留这个代码万一以后用得到~
* @param {*} ctrlId #abc
*/
export const exportWord = async function(ctrlId) {
const htmlString = getHtmlContent(ctrlId)
const fileBuffer = await HTMLtoDOCX(htmlString, null, {
table: { row: { cantSplit: true }},
footer: true,
pageNumber: true
})
// console.log('fileBuffer', fileBuffer)
saveAs(fileBuffer, 'html-to-docx.docx')
}
附注
用python把html导出docx
格式错乱,没用
原生table标签导出为xlsx
原网页效果

导出的xlsx效果
效果还行

代码
import FileSaver from 'file-saver'
import * as XLSX from 'xlsx'
function getHtmlContent(ctrlId) {
// 获取整个页面的 HTML
const pageHTML = document.documentElement.outerHTML
// 使用 DOMParser 解析 HTML
const parser = new DOMParser()
const doc = parser.parseFromString(pageHTML, 'text/html')
// 找到 #printableArea
const printableArea = doc.querySelector(ctrlId)
if (!printableArea) return ''
// 隐藏 #printableArea 以外的所有元素
doc.body.childNodes.forEach(node => {
if (node !== printableArea) {
if (node.style) node.style.visibility = 'hidden'
}
})
// 删除所有 .no-print 元素
const noPrintElements = printableArea.querySelectorAll('.no-print')
noPrintElements.forEach(el => el.remove())
return printableArea
}
export const exportExcel = async function(ctrlId) {
const exportContent = getHtmlContent(ctrlId)
// console.log(XLSX)
/* generate workbook object from table */
// var wb = XLSX.utils.table_to_book(document.querySelector(ctrlId))
var wb = XLSX.utils.table_to_book(exportContent)
/* get binary string as output */
var wbout = XLSX.write(wb, { bookType: 'xlsx', bookSST: true, type: 'array' })
try {
FileSaver.saveAs(new Blob([wbout], { type: 'application/octet-stream' }), 'sheetjs.xlsx')
} catch (e) {
if (typeof console !== 'undefined') { console.log(e, wbout) }
}
// return wbout
}
通过pdf转word
导出pdf,通过pdf转word,确实还不错 , 但是pdf里的文字都被截取成图片放到word里了。。
附图
原网页
下图是上面的代码中函数getHtmlContent返回的html保存到html文件后,打开的样子,后面的导出都以? ?getHtmlContent返回的html ?为准
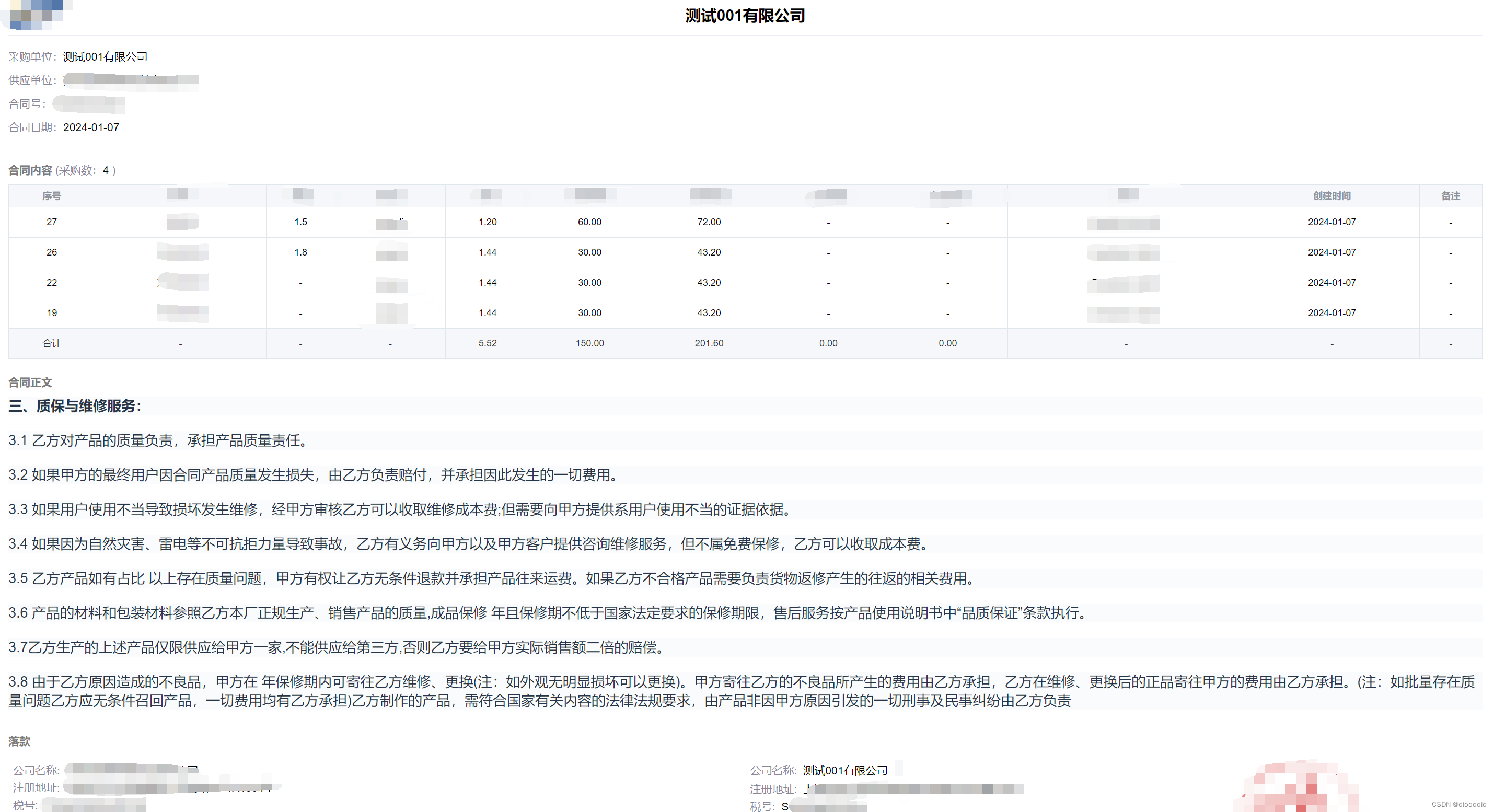
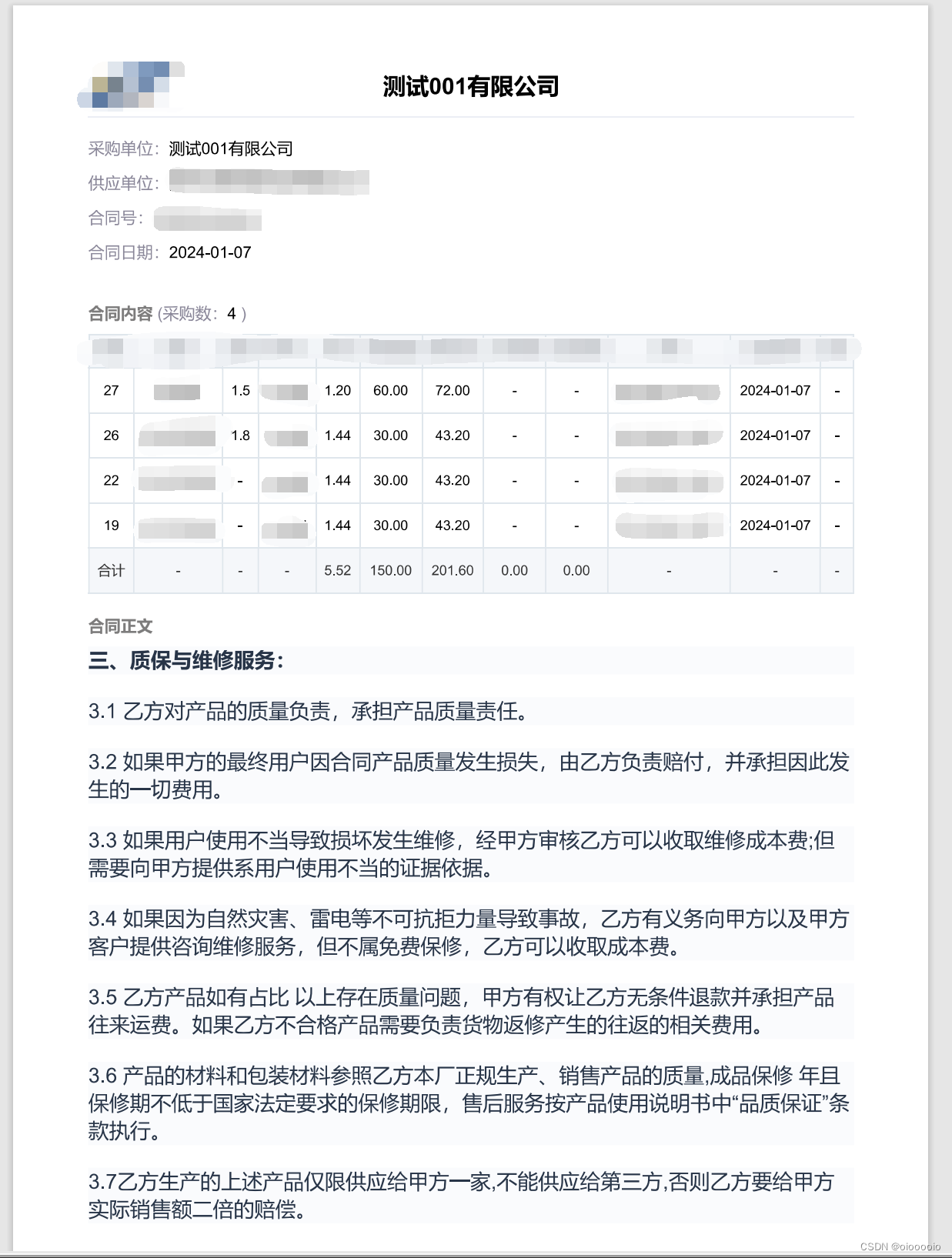
html-to-docx 库导出的docx

第二页就不放了~
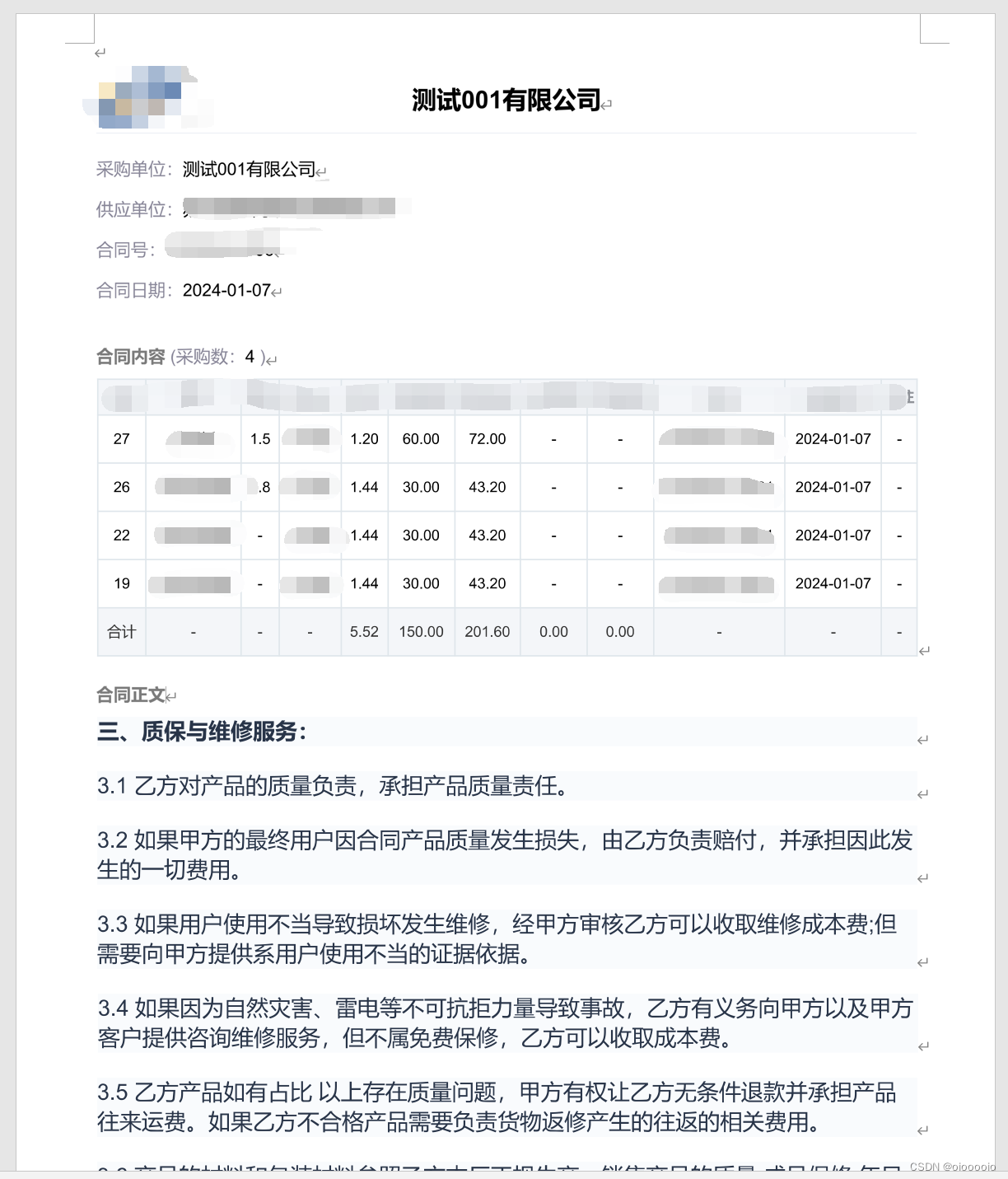
导出为pdf
pdf的效果是完美的~
pdf转word
效果非常不错,但其中的每一段文字都是图片,无法编辑
文章来源:https://blog.csdn.net/oiooooio/article/details/135574885
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 百模大战中的AI行业新趋势:变革、创新与未来
- 【计算机网络】快速做题向 极限数据传输率的计算(有噪声/无噪声)
- Python字符串
- css3背景与渐变
- 网页应用的未来:在线封装APP与下一代WebApp集成技术
- 【无标题】
- 鸿蒙基础开发实战-(ArkTS)像素转换
- 2.0.0 BGP高级特性-ASFilter、CommunityFilter、ORF、对等组
- 2024年原创深度学习算法项目分享
- CyclicBarrier学习一