Nginx 实战闲谈第一讲:HTTP协议介绍
基本介绍
1.HTTP含义
HTTP 全称:Hyper Text Transfer Protocol
中文名:超文本传输协议
HTTP就是将用户的请求发送到服务器,将服务器请求到的内容传输回给浏览器,浏览器进行解析,解析后变成便于观看的页面。,
2.超文本含义
包含有超链接(Link)和各种多媒体元素标记(Markup)的文本。这些超文本文件彼此链接,形成网状(Web),因此又被称为网页(Web Page)。这些链接使用URL表示。最常见的超文本格式是超文本标记语言HTML。
html文件 -> 包含各种各样的元素(URL链接)-> 形成WebPage简称web页面
3.URL含义
URL即统一资源定位符(Uniform Resource Locator),用来唯一地标识万维网中的某一个文件
当我们访问baidu.com 实际上访问 http://www.baidu.com/index.html
URL由协议、主机和端口(默认为80)以及文件名三部分构成: #URL: http://www.baidu.com:80/index.html 协议 域名 端口 请求的文件及路径 #协议:stf、ssh、tcp、http、file #域名:访问的主机名字(有代表性,好记,唯一) #端口:进入网站的门户 #文件:真实存在于服务器上的文件
HTTP URL HTML三者关系 一个完整html页面,是由很多URL组成的,而HTTP协议是用来传输和解析html页面的
HTTP协议原理
1.HTTP协议原理
1、 首先,当你在浏览器中输入一个网址的时候(https://www.baidu.com/index.html)浏览器会帮你分析你输入的这个URL
2、 其次,浏览器会向DNS服务器请求解析,该URL中的域名www.baidu.com,解析出百度服务器所在的IP地址
3、 DNS服务器,会将解析出来的IP地址110.111.112.113并返回给浏览器。
4、 浏览器接收到DNS返回的IP地址,立即与该IP所在的服务器建立TCP连接(80端口)。
5、 浏览器请求文档,也就是咱们常说的html页面,GET /index.html,并发出HTTP请求报文。
6、 服务器给出响应,将请求的index.html文档返回给浏览器,也就是响应HTTP请求的报文。
7、 TCP连接响应完之后,释放TCP连接。
8、 最后就能显示出,你请求的这个页面了
2.HTTP数据报文
GET那一部分内容被称为:请求头信息 GET和HTTP之间有一个空行被称为:请求空行 HTTP中的信息被称为:回应信息 HTTP与faa之间也有个空行被称为:响应空行 faa部分被称为:主体
HTTP请求页面信息
1.基本信息
#请求的URL
Request URL: https://blog.driverzeng.com/zenglaoshi/2039.html
#请求的方式
Request Method: GET
#状态码
Status Code: 200
#远程主机和端口
Remote Address: 122.193.130.81:443
#表示从https协议降为http协议时不发送referrer给跳转网站的服务器
Referrer Policy: no-referrer-when-downgrade
2.请求头部信息
#请求的域名
:authority: blog.driverzeng.com
#请求的类型
:method: GET
#请求的文件路径
:path: /zenglaoshi/2039.html
#请求的协议
:scheme: https
#请求的资源类型
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
#请求过程压缩
accept-encoding: gzip, deflate, br
#字符类型
accept-language: zh-CN,zh;q=0.9
#登录验证
authorization: Basic emxzX2FkbWluOjFxYXokUkZW
#缓存控制
cache-control: no-cache
#缓存验证
cookie: PHPSESSID=7155d8f835a6580a0fbe6c930c265a40
#缓存
pragma: no-cache
upgrade-insecure-requests: 1
#用户的客户端
user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36
3.响应的头部信息
#阿里云信息存储时间
ali-swift-global-savetime: 1597742129
#缓存控制
cache-control: no-store, no-cache, must-revalidate
#压缩
content-encoding: gzip
#文件类型和字符集
content-type: text/html; charset=UTF-8
#时间
date: Tue, 18 Aug 2020 09:15:29 GMT
#加密id
eagleid: 9903e79615977421289024140e
#失效时间
expires: Thu, 19 Nov 1981 08:52:00 GMT
#软连接
link: <https://blog.driverzeng.com/wp-json/>; rel="https://api.w.org/"
link: <https://blog.driverzeng.com/?p=2039>; rel=shortlink
#缓存
pragma: no-cache
#web服务
server: Tengine
#状态码
status: 200
#跨域访问
timing-allow-origin: *
#渲染
vary: Accept-Encoding
#各级缓存
via: cache20.l2cn1817[275,200-0,M], cache4.l2cn1817[276,0], cache4.l2cn1817[276,0], kunlun9.cn206[283,200-0,M], kunlun2.cn206[284,0]
-----cdn服务器的参数-----
x-cache: MISS TCP_MISS dirn:-2:-2
x-pingback: https://blog.driverzeng.com/xmlrpc.php
x-powered-by: PHP/7.1.21
x-swift-cachetime: 0
x-swift-savetime: Tue, 18 Aug 2020 09:15:29 GMT
HTTP请求方法
在HTTP请求报文中的方法(Method),是对所请求对象所进行的操作,也就是一些命令。请求报文中的操作有:
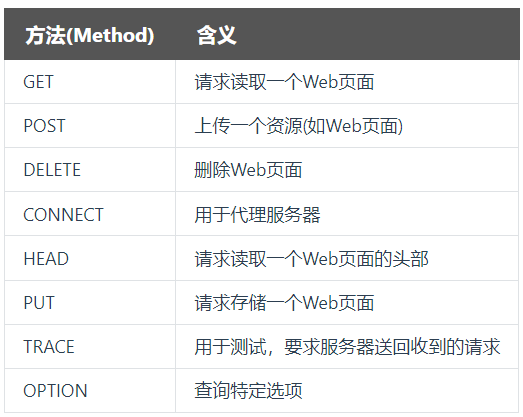
HTTP响应方法
状态码(status-code)是响应报文状态行中包含的一个3位数字,指明特定的请求是否被满足,如果没有满足,原因是什么。
状态码分为以下五类:

HTTP请求头部信息
| Header | 解释 | 实例 |
|---|---|---|
| Accept | 指定客户端能够接收的内容类 | Accept: text/plain, text/html |
| Accept-Charset | 浏览器可以接受的字符编码集。 | Accept-Charset: iso-8859-5 |
| Accept-Encoding | 指定浏览器可以支持的web服务器返回内容压缩编码类型。 | Accept-Encoding: compress, gzip |
| Accept-Language | 浏览器可接受的语言 | Accept-Language: en,zh |
| Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段 | Accept-Ranges: bytes |
| Authorization | HTTP授权的授权证书 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 指定请求和响应遵循的缓存机制 | Cache-Control: no-cache |
| Connection | 表示是否需要持久连接。(HTTP 1.1默认进行持久连接) | Connection: close |
| Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 | Cookie: $Version=1; Skin=new; |
| Content-Length | 请求的内容长度 | Content-Length: 348 |
| Content-Type | 请求的与实体对应的MIME信息 | Content-Type: application/x-www-form-urlencoded |
| Date | 请求发送的日期和时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | 请求的特定的服务器行为 | Expect: 100-continue |
| Host | 指定请求的服务器的域名和端口号 | Host: www.cnblogs.com |
| If-Match | 只有请求内容与实体相匹配才有效 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | 只在实体在指定时间之后未被修改才请求成功 | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | 限制信息通过代理和网关传送的时间 | Max-Forwards: 10 |
| Pragma | 用来包含实现特定的指令 | Pragma: no-cache |
| Proxy-Authorization | 连接到代理的授权证书 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | 只请求实体的一部分,指定范围 | Range: bytes=500-999 |
| Referer | 先前网页的地址,当前请求网页紧随其后,即来路 | Referer: https://www.cnblogs.com/jhno1/p/15767499.html |
| TE | 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 | TE: trailers,deflate;q=0.5 |
| Upgrade | 向服务器指定某种传输协议以便服务器进行转换(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | User-Agent的内容包含发出请求的用户信息 | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | 通知中间网关或代理服务器地址,通信协议 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 关于消息实体的警告信息 | Warn: 199 Miscellaneous warning |
HTTP响应头部信息
| Header | 解释 | 示例 |
|---|---|---|
| Accept-Ranges | 表明服务器是否支持指定范围请求及哪种类型的分段请求 | Accept-Ranges: bytes |
| Age | 从原始服务器到代理缓存形成的估算时间(以秒计,非负) | Age: 12 |
| Allow | 对某网络资源的有效的请求行为,不允许则返回405 | Allow: GET, HEAD |
| Cache-Control | 告诉所有的缓存机制是否可以缓存及哪种类型 | Cache-Control: no-cache |
| Content-Encoding | web服务器支持的返回内容压缩编码类型。 | Content-Encoding: gzip |
| Content-Language | 响应体的语言 | Content-Language: en,zh |
| Content-Length | 响应体的长度 | Content-Length: 348 |
| Content-Location | 请求资源可替代的备用的另一地址 | Content-Location: /index.htm |
| Content-MD5 | 返回资源的MD5校验值 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range | 在整个返回体中本部分的字节位置 | Content-Range: bytes 21010-47021/47022 |
| Content-Type | 返回内容的MIME类型 | Content-Type: text/html; charset=utf-8 |
| Date | 原始服务器消息发出的时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| ETag | 请求变量的实体标签的当前值 | ETag: “737060cd8c284d8af7ad3082f209582d” |
| Expires | 响应过期的日期和时间 | Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified | 请求资源的最后修改时间 | Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
| Location | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 | Location: https://www.cnblogs.com/jhno1/p/15767499.html |
| Pragma | 包括实现特定的指令,它可应用到响应链上的任何接收方 | Pragma: no-cache |
| Proxy-Authenticate | 它指出认证方案和可应用到代理的该URL上的参数 | Proxy-Authenticate: Basic |
| refresh | 应用于重定向或一个新的资源被创造,在5秒之后重定向(由网景提出,被大部分浏览器支持) | Refresh: 5; url=https://www.cnblogs.com/jhno1/p/15767499.html |
| Retry-After | 如果实体暂时不可取,通知客户端在指定时间之后再次尝试 | Retry-After: 120 |
| Server | web服务器软件名称 | Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Set-Cookie | 设置Http | Cookie Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
| Trailer | 指出头域在分块传输编码的尾部存在 | Trailer: Max-Forwards |
| Transfer-Encoding | 文件传输编码 | Transfer-Encoding:chunked |
| Vary | 告诉下游代理是使用缓存响应还是从原始服务器请求 | Vary: * |
| Via | 告知代理客户端响应是通过哪里发送的 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 警告实体可能存在的问题 | Warning: 199 Miscellaneous warning |
| WWW-Authenticate | 表明客户端请求实体应该使用的授权方案 | WWW-Authenticate: Basic |
HTTP总结
原理
1.用户输入域名 - > 浏览器跳转 - > 浏览器缓存 - > Hosts文件 - > DNS解析(递归查询|迭代查询)
客户端向服务端发起查询 - > 递归查询
服务端向服务端发起查询 - > 迭代查询
2.由浏览器向服务器发起TCP连接(三0次握手)
客户端 -->请求包连接 -syn=1 seq=x 服务端
服务端 -->响应客户端 syn=1 ack=x+1 seq=y 客户端
客户端 -->建立连接 ack=y+1 seq=x+1 服务端
3.客户端发起http请求:
1)请求的方法是什么: GET获取
2)请求的Host主机是: blog.driverzeng.com
3)请求的资源是什么: /index.html
4)请求的端口是什么: 默认http是80 https是443
5)请求携带的参数是什么: 属性(请求类型、压缩、认证、浏览器信息、等等)
6)请求最后的空行
4.服务端响应的内容是
1)服务端响应使用WEB服务软件
2)服务端响应请求文件类型
3)服务端响应请求的文件是否进行压缩
4)服务端响应请求的主机是否进行长连接
5.客户端向服务端发起TCP断开(四次挥手)
客户端 --> 断开请求 fin=1 seq=x --> 服务端
服务端 --> 响应断开 fin=1 ack=x+1 seq=y --> 客户端
服务端 --> 断开连接 fin=1 ack=x+1 seq=z --> 客户端
客户端 --> 确认断开 fin=1 ack=x+1 seq=sj --> 服务端
HTTP协议
http1.0:短连接,一次TCP连接,仅发起一次请求
http1.1:长连接,一次TCP连接,发起多次请求
http2.0:HTTPS用
http3.0
用户访问集群架构的流程
1.客户端发起http请求,请求会先抵达前端的防火墙
2.防火墙识别用户身份,正常的请求通过内部交换机通过tcp连接后端的负载均衡,传递用户的http请求
3.负载接收到请求,会根据请求的内容进行下发任务,通过tcp连接后端的web,转发发用户的http请求
4.web接收到用户的http请求后,会根据用户请求的内容进行解析,解析分为如下:
静态请求:web直接返回给负载均衡->防火墙->用户
动态请求:web向后端的动态程序建立TCP连接,将用户的动态http请求传递至动态程序->由动态程序进行解析
5.动态程序在解析的过程中,如果碰到查询数据库请求,则优先与缓存建立tcp连接,并发起数据查询操作。
6.如果缓存没有对应的数据,动态程序再次向数据库建立tcp连接,并发起查询操作。
7.最后数据由, 数据库->动态程序->缓存->web服务->负载均衡->防火墙->用户。
HTTP相关术语
1.PV 、UV、IP
假设公司有一座大厦,大厦有100人,每个人有一台电脑和一部手机,上网都是通过nat转换出口,每个人点击网站2次, 请问对应的pv,uv,ip分别是多少?
PV : 页面独立浏览量
UV : 独立设备
IP : 独立IP
那么上面的题:
PV: 100*2*2 = 400
UV: 100*2 = 200
IP: 1
日PV千万量级并不大
2.SOA松藕合架构
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和契约联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
#一个电商公司,他的网站页面功能会有很多
注册
登录
首页
详情页
购物车
价格标签
留言
客服
支付中心
物流
仓储信息
订单相信
图片
好了,第一讲就分享到这里,本专栏持续更新中,欢迎关注"安前码后",觉得用心整理的话,帮忙给个三连,更多干货持续输出中…
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用java调用python批处理将pdf转为图片
- 深度学习中框架和库的区别是什么。
- 六个字总结用友U8 BI方案:不加班、涨业绩
- 跳跃游戏 + 45. 跳跃游戏 II
- 出版基础知识 | 出版物市场篇
- 1、Git概述与安装
- 基础数论1
- <Articles v-if=“!loading“ :articles=“props.articles“ />的区分
- Echarts使用,Echarts图表自适应窗口大小
- MS761比较器可兼容MAX9030