基于Kettle开发的web版数据集成开源工具(data-integration)-应用篇
发布时间:2024年01月04日
📚第一章 基本流程梳理
📗页面基本操作
从登录开始->新建项目->保存项目->运行项目开始(问题还是挺多的,不过主要还是借鉴任务编排这一块,无伤大雅)

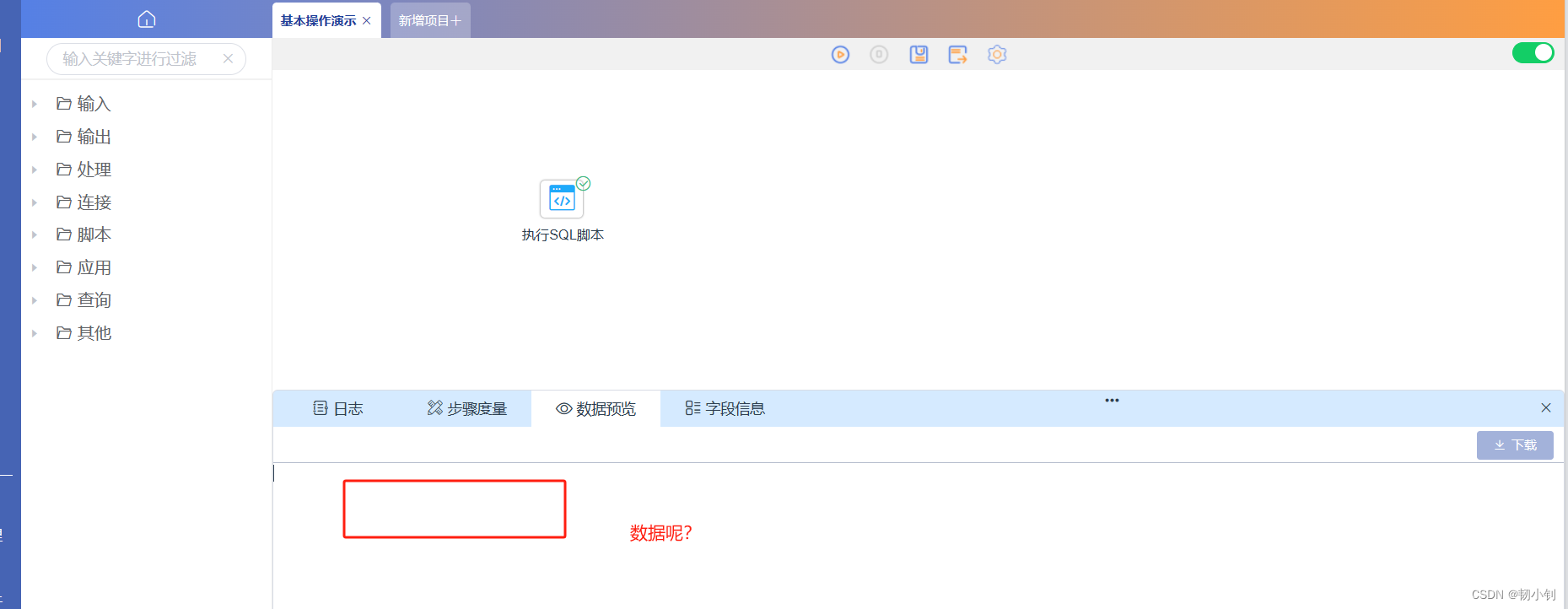
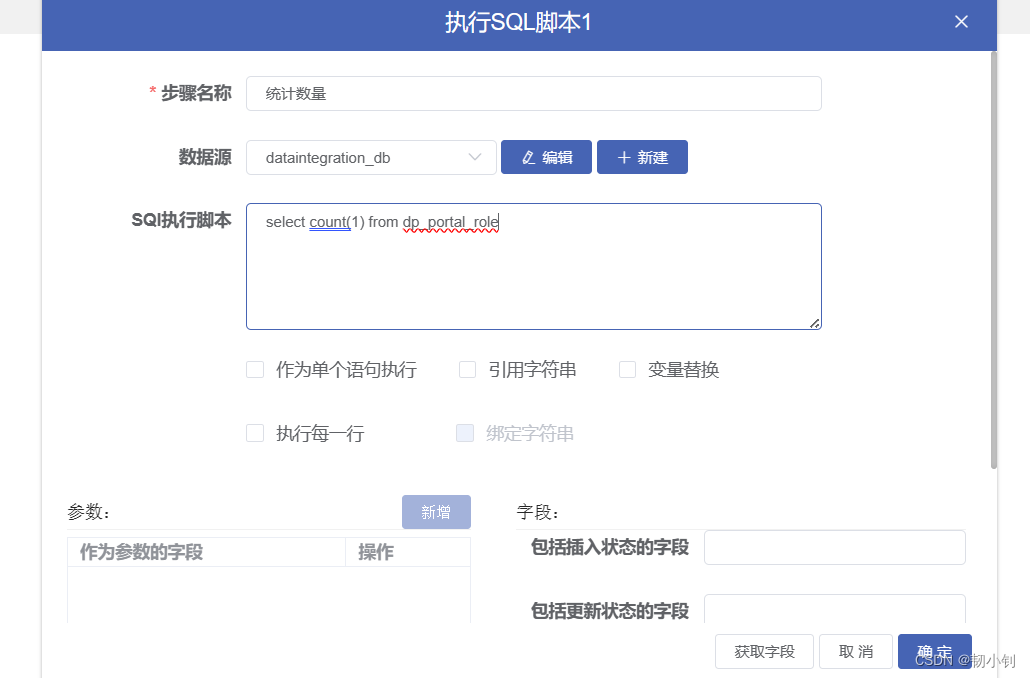
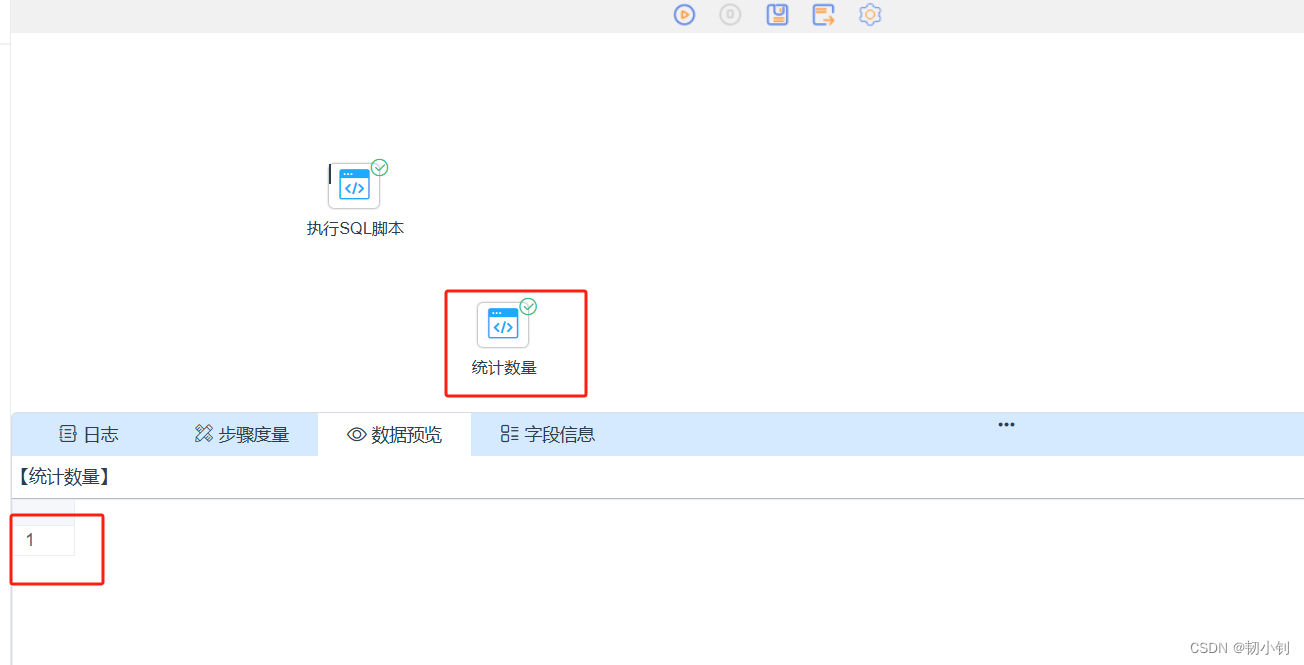
select role_name,`describe` from dp_portal_role
📗对应后台服务流程
参照页面基本操作,梳理后台对应的服务及表等
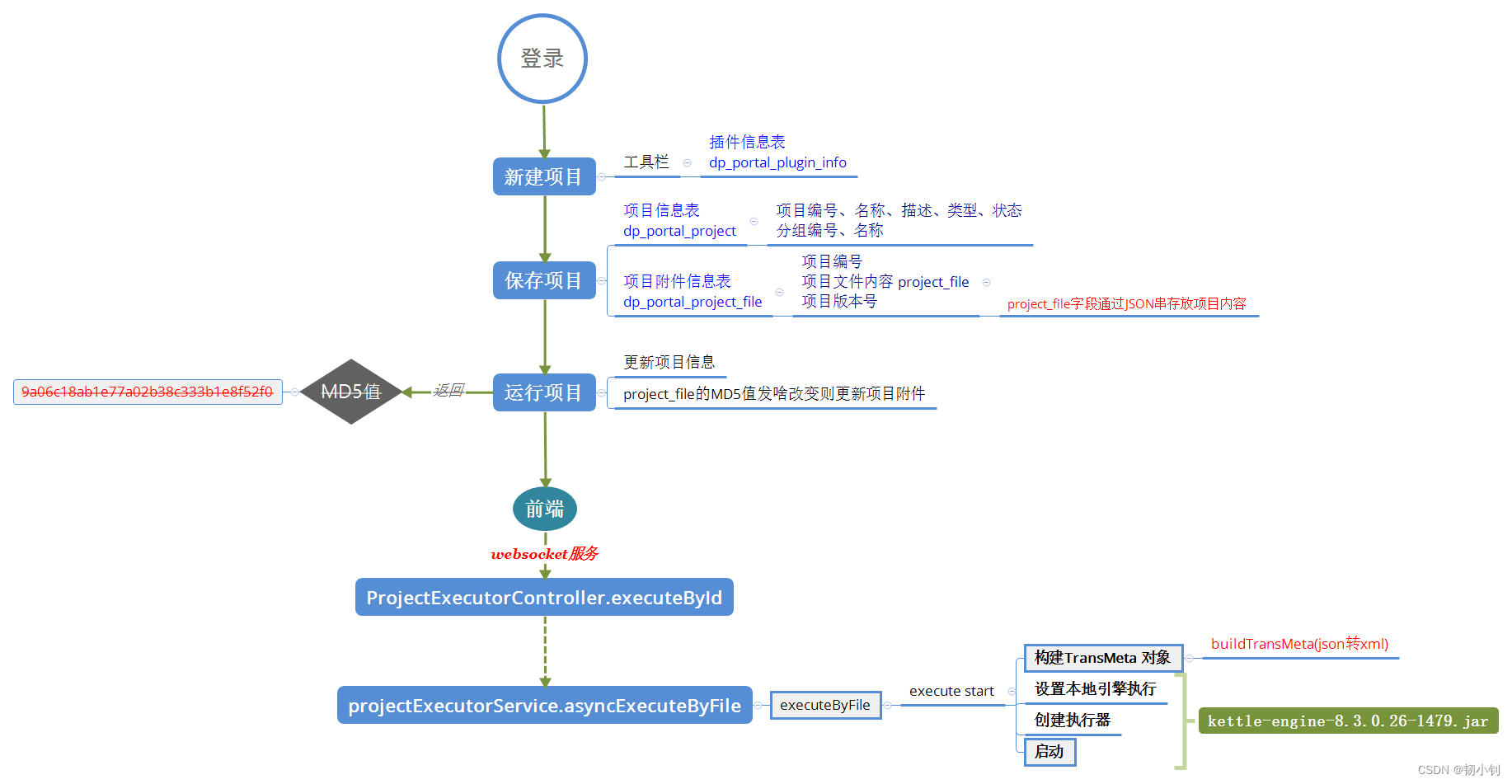
- 项目主要对应两种表
- 项目信息表
dp_portal_project:项目编号、名称、描述、类型、状态,分组编号、名称 - 项目附件信息表
dp_portal_project_file:项目编号、项目文件内容project_file、项目版本号;其中project_file字段通过JSON串存放项目内容
- 项目信息表
- 运行项目
- 调用更新项目信息接口
ProjectServiceApiController.updateSelective - 前端通过调用
websocket服务,调用运行接口ProjectExecutorController.executeById@MessageMapping和@SendToUser注解是用来处理WebSocket消息并实现广播或点对点消息推送的:WebSocket客户端向服务器发送一条指向/executeById路径的消息。- 服务器端通过
@MessageMapping找到并执行executeById方法。 - 方法内部完成业务逻辑处理后,返回的结果会被自动通过
WebSocket协议推送给对应用户,即在每个已认证用户的特定通道上发布结果。


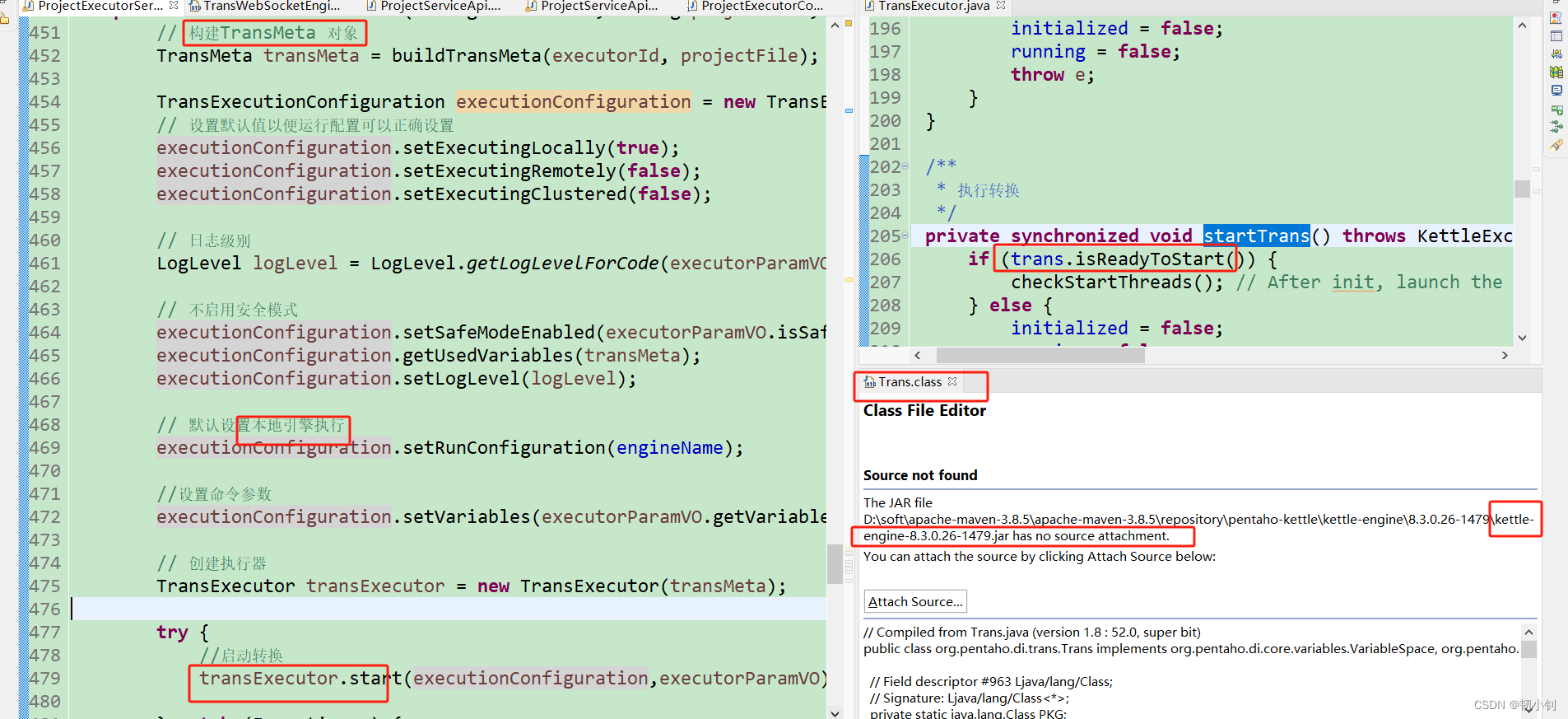
projectExecutorService.asyncExecuteByFileexecuteByFile.execute.start()- 构建
TransMeta对象,buildTransMeta(json转xml) - 设置本地引擎执行
- 创建执行器
- 启动
- 构建
- 调用
Kettle本地引擎
- 调用更新项目信息接口
📚第二章 二开思路
通过上面的流程梳理,发现任务编排工作流主要在前端,各种字段属性和kettle对应都是前端传给后台的,后台直接保存的JSON串,我这里只需要任务编排这块功能,springcloud也用不到,后面如果借鉴该项目,大概要做哪些事?
📗前端
应该可以直接复用,我们用的也是vue2+element架构
📗后端
该项目涉及的技术组件比较多,用到了springcloud,相对来说有点麻烦,到了具体开发阶段,涉及的就比较多了,下一步可以先简单点,就导出一个作业文件,提取相关代码,能够成功执行作业之后,在开始大刀阔斧的开展工作,一步一步推进:
- kettle本地引擎执行代码
- 作业文件组装、转换代码
文章来源:https://blog.csdn.net/qq_36434219/article/details/135378698
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Jmeter压力测试实战分析详解
- python数据分析之交叉验证
- cf round917 B题讲解
- 《Kotlin核心编程》笔记:反射、注解和加锁
- 古今内衣股票代码(古今内衣:A股上市代号!)
- 最实用的 8 个免费 Android 数据恢复软件
- 【读书笔记】信息架构:超越Web设计-第五章《信息架构详解》
- mysql 分组排序后取第一条数据
- 超维空间S2无人机使用说明书——32、使用yolov7进行目标识别
- 2024年解决网络抓取中CAPTCHA问题的顶级CAPTCHA解决方案