多粒度在研究中的应用
发布时间:2024年01月03日
FontDiffuser: One-Shot Font Generation via Denoising Diffusion with Multi-Scale Content Aggregation and Style Contrastive Learning
存在的问题
现有的字体生成方法虽然取得了令人满意的性能,但在处理复杂字和风格变化较大的字符(尤其是中文字符)时,仍会出现严重的笔画缺失、伪影、模糊、结构布局错误和风格不一致等问题,如上图4所示。
原因分析
-
大多数方法都采用基于 GAN 的框架,由于其对抗训练的性质,可能会出现训练不稳定的问题。
-
这些方法大多只通过单一尺度的高维特征来感知内容信息,而忽略了对保留源内容(尤其是复杂字符)的细粒度细节。
-
许多方法利用先验知识来帮助字体生成,例如字符的笔画或部件组成;然而,对于复杂的字符来说,获取这些细粒度信息的成本很高;
-
在过去的方法中,目标风格通常由一个简单的分类器或判别器来进行特征表示学习,这种分类器或判别器很难学习到合适的风格,在一定程度上阻碍了在风格变化较大时的风格转换。
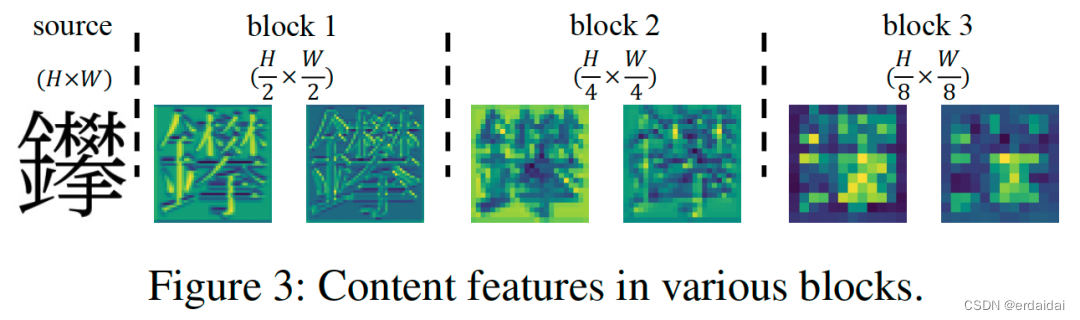
图1 在内容编码器中不同尺度的特征图
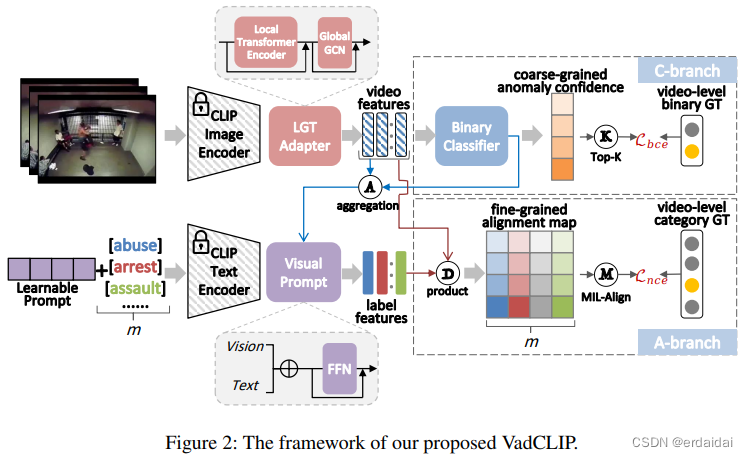
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
将视觉语言模型应用于弱监督视频异常检测
「简述:」VadCLIP是利用对比语言-图像预训练(CLIP)模型进行弱监督视频异常检测的新方法。它通过直接利用冻结的CLIP模型,无需预训练和微调,简化了模型适应过程。与现有方法不同,VadCLIP充分利用CLIP在视觉和语言之间的精细关联,采用双分支结构。一个分支进行粗粒度二分类,另一个分支则充分利用语言-图像对齐进行细粒度分析。通过双分支结构,VadCLIP实现了从CLIP到WSVAD任务的迁移学习,实现了粗粒度和细粒度的视频异常检测。
文章来源:https://blog.csdn.net/erdaidai/article/details/135359809
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Java注解的作用是什么?】
- EMC整改评估要素,需要提供什么?
- 揭秘!样本册制作秘籍
- Flask框架小程序后端分离开发学习笔记《2》构建基础的HTTP服务器
- C++实现字符串匹配的暴力法
- 大模型推理优化实践:KV cache 复用与投机采样
- 浅谈轻量级Kubernetes—K3s
- 美国初创公司Rabbit推出口袋AI设备R1;吴恩达课程:使用LangChain.js构建强大的JavaScript应用
- 复盘理解/实验报告梳理 数据结构PTA实验三
- Java面向对象--类与对象