使用 MinIO 构建兼容 S3 的股票市场数据湖
在我之前关于 MinIO 的所有帖子中,我必须编写代码,我使用了 MinIO 的 Python SDK,这记录在这里。我更喜欢这个 SDK,因为它易于使用,并且它提供了对 MinIO 企业功能的编程访问,例如生命周期管理、对象锁定、存储桶通知和站点复制。(我在我的博文《AI/ML 的对象管理》中展示了如何使用代码设置生命周期管理和对象锁定。如果您的应用程序以编程方式设置存储桶,并且您需要这些功能,那么 MinIO SDK 是一个不错的选择。但是,MinIO 符合 S3 标准,您可以使用任何实现 S3 的 SDK 连接到 MinIO。
另一个流行的 S3 访问开发工具包是 Amazon 的 S3 客户端,它是其 botocore 库的一部分,该库是 AWS 上许多服务的低级接口。该库也适用于 MinIO,它提供了对我之前提到的所有企业功能的访问。如果您正在考虑将应用程序及其数据从 AWS 遣返到本地数据中心的 MinIO,则无需更改任何代码。更改配置中的 URL、访问密钥和密钥,您就可以开始了。
第三种选择是 S3fs 库。它不提供对 MinIO SDK 和 S3 客户端等企业功能的访问,但它易于使用,许多其他库和工具(如 PyArrow 和 MLFlow)使用其类来设置 S3 数据源。
在这篇文章中,我将使用 S3fs Python 库与 MinIO 进行交互。为了让事情变得有趣,我将创建一个迷你数据湖,用市场数据填充它,并为那些希望分析股票市场趋势的人创建一个股票行情图。
安装所需的库
除了 s3fs 库之外,我们还需要 Yahoo Finance 库来下载历史市场数据。我还将使用 Seaborn 和 Matplotlib 作为股票行情图表。可以使用以下命令安装这四个库。
pip install matplotlib
pip install s3fs
pip install seaborn
pip install yfinance
下载市场数据
在过去的十年里,市场观察家们已经养成了发明新术语来指代最热门股票的习惯。2013 年,吉姆·克莱默 (Jim Cramer) 创造了 FANG 一词——一个首字母缩写词,指的是 Facebook、亚马逊、Netflix 和谷歌。2017 年,投资者开始将苹果纳入这一组,首字母缩略词成为 FAANG。当 Facebook 更名为 Meta 和 Google 更名为 Alphabet 时,首字母缩略词进一步演变为 MAMAA。
现在,在 2024 年,我们有了一个新标签:The Magnificent Seven。壮丽七人组由苹果、亚马逊、Alphabet、Meta、Microsoft、英伟达和特斯拉组成。让我们使用雅虎财经库下载 2023 年全年 Magnificent Seven 的市场数据。
import datetime
import os
import yfinance as yf
start_date = datetime.datetime(2023, 1, 1)
end_date = datetime.datetime(2023, 12, 31)
download_dir = os.path.join(os.getcwd(), 'marketdata')
magnificient_seven = ['AAPL', 'AMZN', 'GOOGL', 'META', 'MSFT', 'NVDA', 'TSLA']
for ticker_string in magnificient_seven:
ticker = yf.Ticker(ticker_string)
historical_data = ticker.history(start=start_date, end=end_date)
file_path = os.path.join(download_dir, f'{ticker_string}.parquet')
historical_data.to_parquet(file_path)
print(f'{ticker_string} downloaded.')
如果成功,输出将为:
AAPL downloaded.
AMZN downloaded.
GOOGL downloaded.
META downloaded.
MSFT downloaded.
NVDA downloaded.
TSLA downloaded.
设置 S3 连接
我们需要做的第一件事是创建一个 S3FileSystem 对象。我们需要与 S3 数据源交互的所有方法都挂在这个对象上。下面的代码将从环境变量中获取 MinIO 的终端节点、访问密钥和私有密钥,并创建一个 S3FileSystem 对象。
from s3fs import S3FileSystem
key = os.environ['MINIO_ACCESS_KEY']
secret = os.environ['MINIO_SECRET_ACCESS_KEY']
endpoint_url = os.environ['MINIO_URL']
s3 = S3FileSystem(anon=False, endpoint_url=endpoint_url,
key=key,
secret=secret,
use_ssl=False)
创建存储桶
一旦我们有了 S3FileSystem 对象,我们就可以使用它来创建存储桶。makedir() 函数将做到这一点。下面的代码首先检查存储桶是否存在,然后再创建它。makedir() 函数有一个 exist_ok 参数,如果存储桶已经存在,您会认为该参数将允许 makedir 成功完成。不幸的是,我发现情况并非如此。如果存储桶已存在,则无论此参数的设置方式如何,此函数都将引发异常。因此,最好显式检查存储桶是否存在,并且仅在存储桶不存在时调用 makedir()。
bucket_name = 'market-data'
if not s3.exists(bucket_name):
s3.makedir(f's3://{bucket_name}', exist_ok=True)
上传市场数据
为了将对象上传到我们新创建的存储桶,我们将使用 s3fs 的 put_file() 函数。此函数会将单个文件上传到 S3 对象存储中的目标,在本例中为 MinIO。它采用本地源文件和远程路径作为参数。
magnificient_seven = ['AAPL', 'AMZN', 'GOOGL', 'META', 'MSFT', 'NVDA', 'TSLA']
for ticker_string in magnificient_seven:
local_file_path = os.path.join(download_dir, f'{ticker_string}.parquet')
remote_object_path = f'{bucket_name}/{ticker_string}.parquet'
s3.put_file(local_file_path, remote_object_path)
print(f'{ticker_string} uploaded.')
S3fs 还提供了一个 put() 函数,该函数会将本地的全部内容直接上传到指定路径。如果您的本地目录有子文件夹,它甚至有一个递归开关。
完成上述代码后,您的 MinIO 存储桶将如下面的屏幕截图所示。
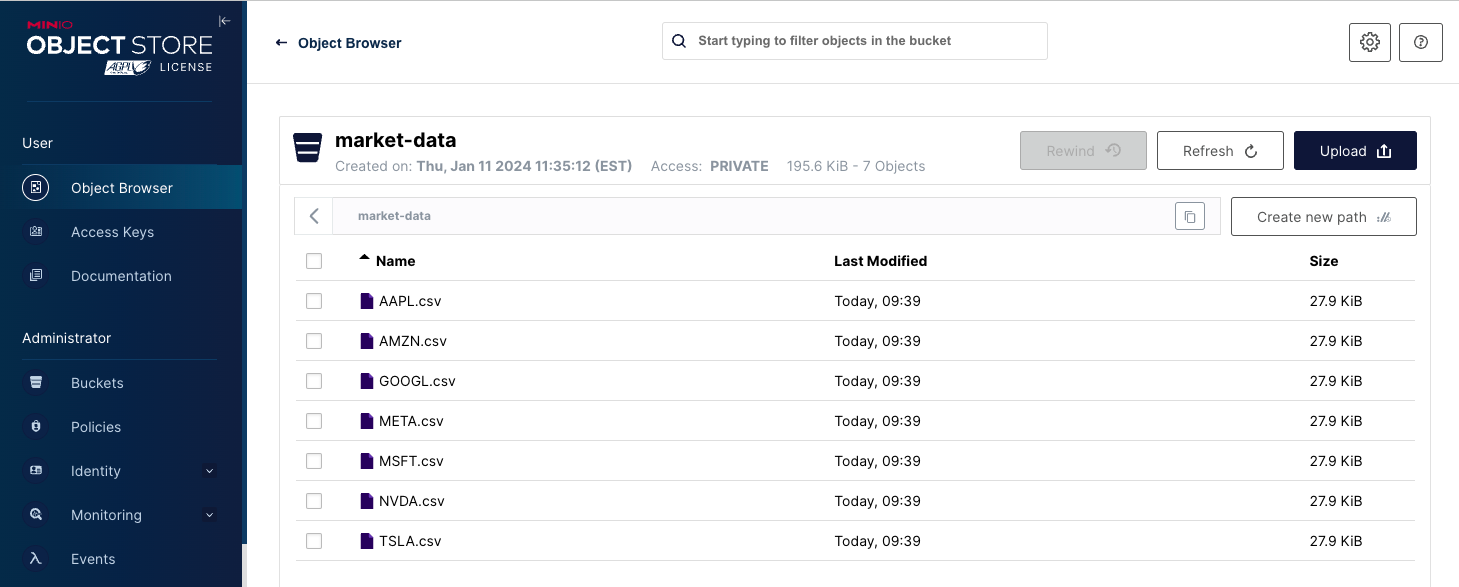
列出对象
列出存储桶中的对象非常简单。s3fs 对象有一个 ls() 方法,该方法将远程位置作为参数。如下所示。
object_list = s3.ls(f's3://{bucket_name}', detail=False)
object_list
当您调用 ls() 方法并将 detail 参数设置为 False 时,返回值将是一个简单的 Python 列表,其中包含路径中所有对象的完整路径引用。当您需要列表进行循环时,请使用这种风格的 ls()。下面显示了壮丽七大物体的列表。
['market-data/AAPL.csv',
'market-data/AMZN.csv',
'market-data/GOOGL.csv',
'market-data/META.csv',
'market-data/MSFT.csv',
'market-data/NVDA.csv',
'market-data/TSLA.csv']
如果需要从此函数返回更多详细信息,请将 detail 参数设置为 True。显示详细信息的示例输出如下所示。(为简洁起见,已截断。
[{'Key': 'market-data/AAPL.parquet',
'LastModified': datetime.datetime(2024, 1, 12, 14, 39, 12, 124000, tzinfo=tzutc()),
'ETag': '"03e6abc232e58b1d83aa0b175ae04cf3"',
'Size': 28612,
'StorageClass': 'STANDARD',
'type': 'file',
'size': 28612,
'name': 'market-data/AAPL.csv'},
集成
如前所述,许多第三方库使用 s3fs 的 S3FileSystem 类与符合 S3 的对象存储进行交互。下面的代码展示了如何使用 Pandas 将对象从 MinIO 读取到 Pandas DataFrame 中。
import pandas as pd
ticker_string = 'NVDA'
storage_options={
'key': key,
'secret': secret,
'endpoint_url': endpoint_url,
}
historical_data = pd.read_csv(f's3://{bucket_name}/{ticker_string}.parquet', storage_options=storage_options)
historical_data.tail(10)
输出:
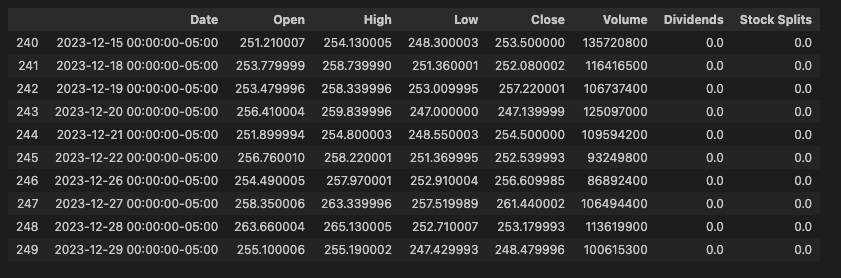
上面的代码根本不需要文件系统即可将数据从 MinIO 获取到 Pandas DataFrame 中。对于需要从原始数据创建数据集的数据科学家来说,这是一个重要的功能。这也是 Quants 手中的一项强大功能,因为 Pandas 建立在 NumPy 之上,它允许创建数学算法来识别交易机会。
PyArrow 是另一个流行的库,它利用 s3fs 进行 S3 访问对象存储。如果您正在处理大型对象,请考虑使用 PyArrow 的 S3 接口。
绘制市场数据
在结束之前,让我们享受最后一点乐趣。我现在想做的是从 MinIO 中提取我们所有的市场数据,并将其加载到一个 DataFrame 中。下面使用 Panda 的 concat 函数完成此操作。请注意,我还必须添加一个股票行情列。
storage_options={
'key': key,
'secret': secret,
'endpoint_url': endpoint_url,
}
df_list = []
for ticker_string in magnificient_seven:
new_data = pd.read_parquet(f's3://{bucket_name}/{ticker_string}.parquet',
storage_options=storage_options)
new_data['Ticker'] = ticker_string
df_list.append(new_data[['Ticker', 'Close']])
historical_data = pd.concat(df_list, axis=0)
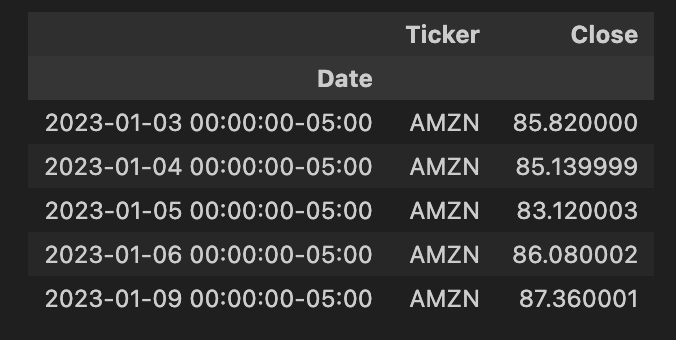
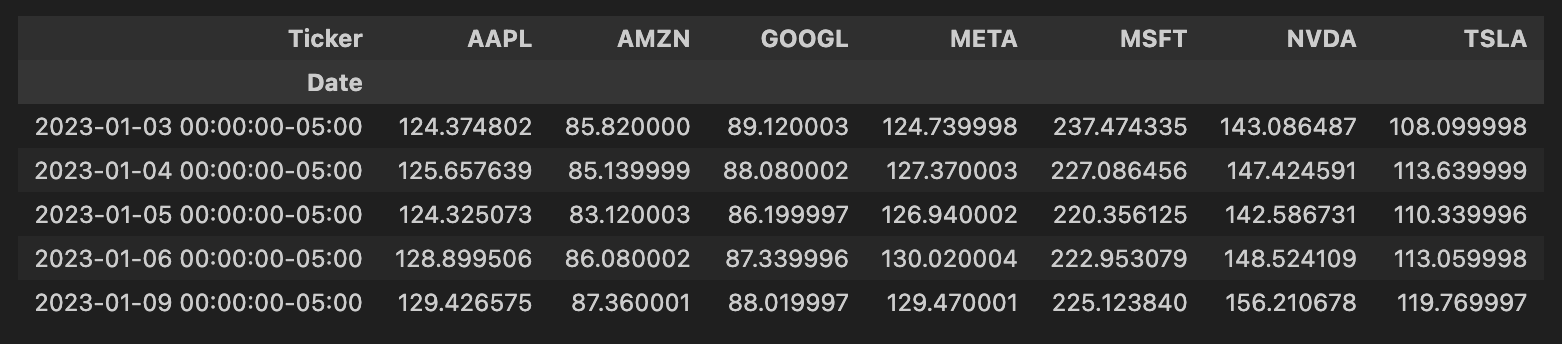
historical_data[historical_data['Ticker']=='AMZN'].head()
historical_data = historical_data.reset_index()
pt = historical_data.pivot(columns='Ticker', index='Date', values='Close')
pt.head()
输出:
接下来,我们需要对股票代码值上的数据进行透视。
historical_data = historical_data.reset_index()
pt = historical_data.pivot(columns='Ticker', index='Date', values='Close')
pt.head()
我们的透视数据现在如下面的屏幕截图所示。
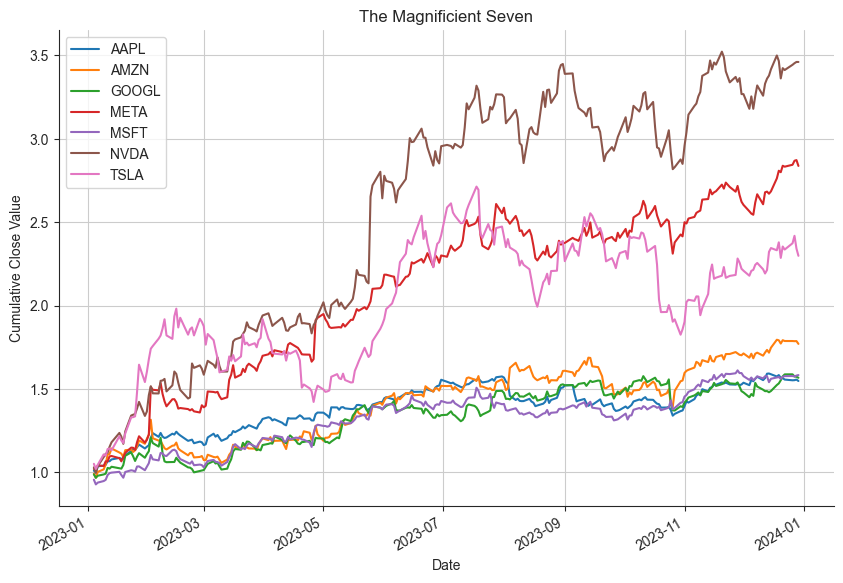
import matplotlib.pyplot as plt
import seaborn as sns
# Use Seaborn to set the style.
sns.set_style('ticks')
# Plot all the close prices as cumulutive closing values.
((pt.pct_change()+1).cumprod()).plot(figsize=(10, 7))
plt.legend()
plt.title('The Magnificient Seven')
# Define the labels
plt.ylabel('Cumulative Close Value')
plt.xlabel('Date')
# Plot the grid lines
plt.grid(True)
sns.despine()
plt.show()
总结
在这篇文章中,我们对 MinIO 和 s3fs 库玩得很开心。我们下载了一些市场数据,使用 s3fs 库将其上传到 MinIO,然后将数据集成到 Pandas 中——同样使用 MinIO 的 S3 接口。最后,我们使用 Matplotlib 和 Seaborn 可视化了我们的数据。
后续步骤
如果您一直在关注我们的博客,那么您就会知道我们喜欢现代数据湖(也称为数据湖仓一体),就像我们喜欢数据湖一样。现代数据湖是数据仓库和数据湖合二为一的产品。这是通过 Iceberg、Hudi 和 Deltalake 等开放表格式 (OTF) 实现的。现代数据湖建立在对象存储之上,允许与数据湖直接集成,同时提供能够通过 SQL 进行高级数据操作的处理引擎。如果您喜欢本文中的内容,并希望更进一步,请考虑构建现代数据湖。几个月前,我在这篇文章中展示了如何:使用 Apache Iceberg 和 MinIO 构建数据湖仓一体。
立即下载 MinIO,了解构建数据湖仓一体是多么容易。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 建筑物防雷检测安全接地应用解决方案
- 机器人活动区域 - 华为OD统一考试
- 【UE5】metahuman头发闪烁
- 《PCI Express体系结构导读》随记 —— 第I篇 第1章 PCI总线的基本知识(4)
- 【Android】自定义View onDraw()方法会调用两次
- C++日期类的实现
- 什么是 SPI,它有什么用?
- 目标检测YOLO实战应用案例100讲-基于目标检测的水稻病害识别(续)
- SpringBoot整合JWT+Spring Security+Redis实现登录拦截(二)权限认证
- 空间换时间-五秒出解:从900ms到5ms的幕后优化大揭秘!