Flink入门教程
发布时间:2024年01月21日
? ? ? ? 使用flink时需要提前准备好scala环境
一、创建maven项目
二、添加pom依赖
<properties>
<scala.version>2.11.12</scala.version>
</properties>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.14.0</version>
</dependency>三、编码实现
? ? ? 准备数据源test_flink.txt
河南 郑州
河南 信阳
郑州 金水区
河南 开封
郑州 管城区
信阳 浉河区
信阳 平桥区
开封 龙亭区? ? ? ? ?编码实现
import org.apache.flink.api.scala._
import org.apache.flink.api.scala.ExecutionEnvironment
object FlinkWordCount {
def main(args: Array[String]): Unit = {
//创建执行环境
val environment = ExecutionEnvironment.getExecutionEnvironment
//读取文件
val dataSet = environment.readTextFile("D:/workplace/java-item/res/file/test_flink.txt")
//将读取的字符扁平化操作,并且按照空字符分割装入到元祖之中,按照元组的第一个元素分组,分组后按照元组的第二个值求和
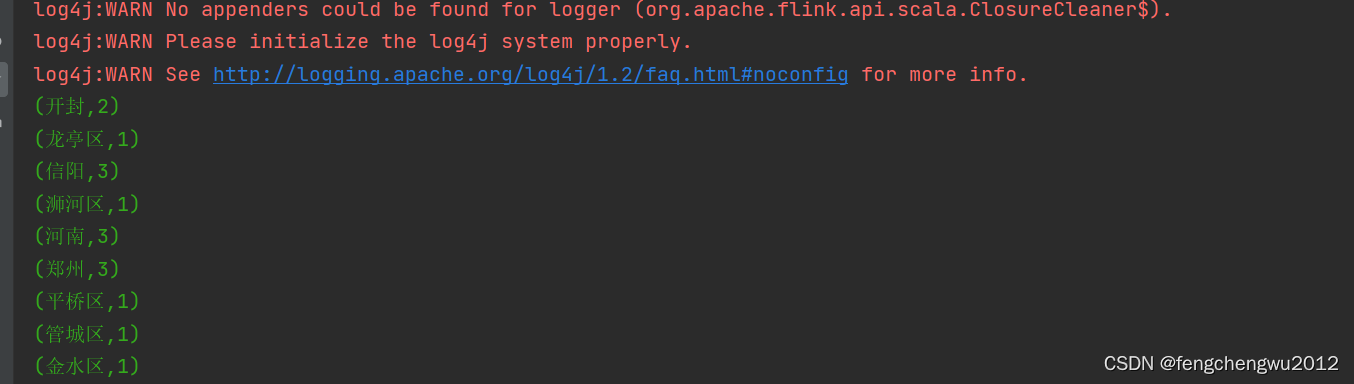
val aggregateDataSet = dataSet.flatMap(_.split(" ")).map((_, 1)).groupBy(0).sum(1)
///打印聚合数据
aggregateDataSet.print()
}
}
文章来源:https://blog.csdn.net/fengchengwu2012/article/details/135729366
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据库设计和SQL基础语法】--查询数据--分组查询
- 【新特性演示】YOLOv8实现旋转对象检测
- 继承中的对象模型
- 经常使用耳机对耳朵听力有影响吗?戴哪种耳机不伤耳朵听力?
- 【计算机毕业设计】SSM健身房俱乐部管理系统
- 2019年认证杯SPSSPRO杯数学建模D题(第二阶段)5G时代引发的道路规划革命全过程文档及程序
- 计算机试题
- XML技术分析03
- vite多页面打包学习(一)
- 结算时间和可组合性助力Sui上DeFi蓬勃发展