扩散模型的机器学习应用

一、说明
????????这篇文章旨在帮助您推导和理解扩散模型。如果您读完本文后的第一个想法是:“为什么我没有想到这个?!?”?那么酷,我成功了。我们不会重建 StableDiffusion,但我们将在最后构建一些玩具模型来演示一切是如何工作的。
????????除了这篇文章之外,我还创建了一个配套的Github 存储库来收集与扩散相关的所有内容。在某些时候,我将参考该存储库以获取更多详细信息。截至 2022 年底,您需要检查两件事:
- 在玩具数据集上从头开始实现扩散模型的简单代码(请参阅DDPM类和此玩具脚本)。
- 完整的教程,包括数学。填补了这篇文章所掩盖的任何空白,并且还有一些有趣的物理知识。如果您觉得这篇文章有趣,我建议您阅读笔记!
二、强制性非技术介绍
????????我不会撒谎。我出于尴尬而开始写这篇文章。
????????上辈子我曾在统计物理学领域工作,感觉就像是这样,这几乎可以用这样的想法来概括:“是的,一个粒子很酷,但你知道什么更酷吗?其中 1023。”?统计物理学是一个广阔的领域,但毫不夸张地说,非平衡物理学的研究在其中占有突出的地位。非平衡物理学是现代物理学中令人兴奋的领域之一,我们仍然没有真正理解它,但仍然包含大量有意义的发现的机会。
????????然而,如果你让我准确描述什么是非平衡物理,老实说我无法告诉你。如果你随机选择任何物理问题并问我“这是非平衡吗?”?我可能会回答:“不,这是帕特里克……”然后,继续以尴尬的沉默坐着,决定是笑还是畏缩。但是,有一种现象我可以说确实属于非平衡物理,因此应该属于我的“专业”领域:扩散。
????????如果您完全跟上 2022 年的 ML 流行文化,那么“扩散”这个词应该会引起您的生成式 AI 流行语警报 ?。当我第一次注意到人们开始随意地讨论非平衡物理术语时,我感到胃部一阵剧痛。我的思绪充斥着漫长的夜晚,艰难地研读范·坎彭的《物理和化学中的随机过程》。但是,如果有一个足够强大的动力来克服数学引起的恶心,那就是尴尬。由于担心有人会问我扩散模型是如何工作的,我开始尽快研究它们。这篇文章并不是关于我试图自我证明我的教育的合理性,也不是抱怨我慢慢地(哈哈,好吧,很快)忘记了我在研究生院学到的一切。不,这是关于分享我来之不易的一些关于扩散模型如何在基础层面上运作的知识。值得庆幸的是,事实证明这些东西非常酷!
三、什么和为什么
3.1 什么是扩散模型?
- 旨在有效地从分布 p(x) 中抽取样本的模型。
- 生成模型。他们学习一些数据的概率分布 p(x)。
- 自然不受监督(与整个生成部分齐头并进),尽管您可以调节它们或学习监督目标。
- 实际上不是模型。扩散模型松散地指的是调度程序、先验分布和转换内核(通常由神经网络参数化)的集合。组合起来,这些部分可以从 p(x) 生成样本。
3.2 为什么扩散模型很酷?
????????扩散模型并不是人们发明的第一个生成模型,公平地说我们为什么特别关心这些模型。为了说明原因,让我们回顾一下历史。
????????您可能会自然而然地想到,在深度学习时代学习概率分布 P(x) 是微不足道的:加载您最喜欢的神经网络,创建参数化函数 E_𝝑(x) 并通过最小化 |P(x) 来学习值 𝝑 ) — E_(x)|。然而,这行不通。原因在于常态化。P(x) 不是我们想要学习的任意函数。它必须遵守 ∫ P(x) dx = 1 的约束,这意味着如果我们想要学习一个无约束函数 E_(x),我们实际上需要优化 |P(x) — E_(x) / ∫ E_𝝑(x) ) dx|,现在由于集成而完全搞砸了。归一化常数 Z(𝝑) = ∫ E_𝝑(x) dx,也称为配分函数,通常用大写字母 Z 表示。遵循学习无约束函数 E_𝝑(x) 的方法的模型称为基于能量的模型(EBM)。
????????值得注意的是,有几种方法可以克服归一化常数问题。冒着错过大量研究的风险,我建议读者参阅 2015 年论文《使用非平衡动力学的深度无监督学习》的第 1.2 节,以获得更好的概述。我只记下一些比较流行的方法:
- 通过使用随机样本近似积分的常用方法来估计训练期间的归一化常数 Z(𝝑)。抽取一个好的随机样本是这里的困难部分。这被称为对比发散训练。
- 了解一些简单的、本质上归一化的函数 q_(x) 的参数,近似P(x)。这就是变分法。
- 仔细构建一堆可逆的、可训练的变换,这些变换采用简单的归一化概率分布(如正态分布)并将其转变为更复杂的东西。这是标准化流量的方法。
- 求解导数 𝛁_x P(x) 而不是 P(x)。由于 𝛁_x Z(𝝑) = 0,这完全消除了归一化常数。这很棒,但目前还不清楚如何利用它。这种方法被称为评分模型,事实证明它可以被证明与某些训练目标的扩散模型等效(参见笔记的倒数第二节基于评分的模型和扩散模型的等效性)
- 将自己从标准化的暴政中解放出来,只需学习一个直接生成样本的函数即可。当你慢慢忘记学习 P(x) 的必要性时,让不稳定的模型在你耳边低语博弈论的甜言蜜语。这就是 GAN 的方法。
????????扩散模型很有趣,因为它们将自己添加为上面列表中的条目 (6)。它们提供了处理标准化问题的不同方法。
四、基本见解
4.1 这个想法
????????您可以将扩散模型方法视为类似于我们之前避免归一化常数的方法列表中的方法 (3) 和 (4) 的组合。扩散模型源自这一简单的想法:
与其直接尝试对分布 P(x) 进行建模,不如我们找到一些采用蹩脚答案 P_crap(y) 的操作,并将其转换为稍微好一点的答案 P_better(x) 呢?
????????为什么这会有帮助?假设我们发现了这样一个操作。如果这个操作可以采用任何旧的猜测 P_crap(x) 并使其变得更好,即使是无限小,那么理论上我们可以一遍又一遍地迭代这个操作,直到我们达到正确的分布 P(x)!现在让我们将第 (6) 项添加到我们的列表中
????????6. 求解采用归一化分布 q_t(x) 的转换核,并将其转换为稍微更好的归一化分布 q_{t+1}(x)。这意味着 p(x) = q_{∞}(x)。这就像一个连续的标准化流程。
????????如果您想要一种有趣的(尽管不完全类似的)视觉呈现正在发生的事情,有一种名为镍钛诺的迷人材料,它能够记住其形状。这是用这些材料制成的回形针的视频。形成的回形针可以被认为是我们想要学习的分布 p(x)。前向(扩散)过程相当于拉直回形针,从而形成漂亮且简单的均匀分布。然后,向后(生成)过程会将其倒入热水中并观察它卷曲回原来的形状。
????????抛开泊松生成流模型
转换内核以一个 D 维 x_t 作为输入,并返回另一个 D 维向量 x_{t+1} 作为输出,这意味着内核产生一个向量场。这是展示矢量场的演示。确保关闭等电位曲线。
我们正在学习向量场的观察非常有帮助。它让我们可以问这样一个问题:“如果我们没有学到任何东西,只是直接计算训练数据集中的每个点被视为一个微小质量时将创建的引力场,会怎么样?”?好吧,你可以。您刚刚创建的是一个函数,它获取空间中的任意点,并将其映射到训练数据中的现有点。这本身并不坏,但我们真正想要的是插值,即映射到不在训练数据集中的点的能力。我可以想到两种方法来实现这一目标。第一种方法是在此映射过程中添加一些随机噪声。这可以变得严格,并且是扩散理论的基础。这是我们在这篇文章中探讨的方法。
第二种方法是仔细构建先验分布和向量场,以便存在将先验映射到 p(x) 的确定性方程。这是泊松生成流模型背后的中心思想。还有更多空白需要填补,但这就是要点。它们简单、强大,并且相对于扩散模型有很多好处。我将在以后的帖子中讨论这些内容。
4.2 等式
????????在本小节中,我们将把我们的想法(使用一些操作将垃圾变成更少的垃圾)转化为数学。从贝叶斯方程可知,我们可以引入一个辅助变量y,使得p(x) = ∫ p(x, y) dy = ∫ p(x | y) p(y) dy。现在让我们将时间离散化为步骤 t ? ?,并将 p(x) 定义为 p(x_t) 对于某个最终时间 t。使用贝叶斯方程,我们可以写出一个一般马尔可夫序列,对任何分布 p(x) 都有效:
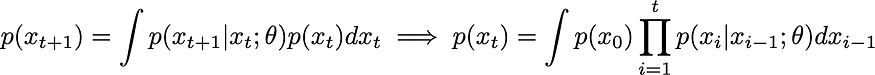
????????我们将函数 p(x_t | x_{t-1}; 𝜗) 称为转换内核。我们通过一些参数 𝜗 对其进行了参数化,这正是我们要训练模型学习的内容。我们还可以引入一个连续版本 p_Δt(x | y),它取决于一个小的时间步 Δt。直观上,转移核 p_Δt(x | y) 表示在时间 t+Δt 时点 x 的概率密度 p(x) 等于时间 t 时所有其他点 y 的概率密度之和,乘以从 y 跳到 x 的转移概率 p(x | y)。换句话说,到达某个地方的唯一方法是从那里开始或从其他地方出发。将所有这些方式加起来,并根据完成该旅行的可能性进行加权,您就得到了新的概率。
????????此时,您可能会想采用正式极限 Δt -> 0 并创建 ?p/?t 项。这样做不会对我们有太大帮助,但我可以告诉你这条路上会发生什么。您本质上是在尝试重新推导主方程?(链接指向 Kramers-Moyal 展开式,因为它具有我想要的主方程版本)。这个方程添加了一个我在直觉中没有提到的部分,即构建一个通用的积分微分偏微分方程,您还必须考虑在时间 t=0 时位于正确位置的某些概率移动到的可能性t=Δt 处的位置错误。无论如何,这里不需要主方程的完整机制。
????????现在我们有了给出数据点 x_t 的对数似然的基本方程,并且我们有一些想要学习的参数。要通过梯度下降学习这些参数,我们需要找到一个损失函数来最小化。但这并不是最难的部分。困难的部分是处理我们刚刚介绍的所有积分和变量 x_0, …, x_t。
五、物理学观点
????????本节对于继续推导扩散模型算法不是必需的,但它会从不同的角度使事情变得更清晰。
5.1 扩散方程的物理学成就
????????首先,我将写下三个方程,并声称这三个方程都描述相同的物理过程:受某些潜在 V(x) 影响的粒子系的演化。这些方程为Langevin 方程、Fokker-Planck 方程和 Onsager-Machlup 泛函。

????????对于 Onsager-Machlup 泛函,我能找到的最好的资源是 Altland 和 Simons凝聚态物理的第 646 页。请注意,在任何固定时间,η(t) 都是从正态分布中得出的!
????????让我们从中间的线开始,即福克-普朗克 (FP) 方程。当 ?p/?t = 0 时,其平稳解出现,解为 p ~ e^{-V / D}。重新排列,我们发现对于选择 V(x) = -ln q(x),平稳解将是 q(x)。换句话说,我们可以编写一个 FP 方程,它在很长一段时间内都能准确地给出我们想要的分布。
????????如果将我们巧妙选择的 V(x) 代入 Langevin 方程(第一行),然后引入一个小时间 ? 并离散化,我们就找到了 Langevin 马尔可夫链蒙特卡罗 (MCMC) 的定义方程
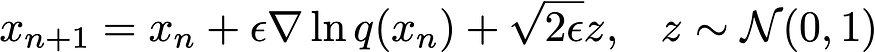
????????只要我们知道要采样的分布的梯度,我们就可以使用上面的方程来模拟一堆粒子x的随机动力学,从而抽取样本。另外,请注意,我们只需要q(x) 的梯度。这听起来很熟悉吗?这正是我们在第 (4) 节“为什么扩散模型很酷”中定义的分数。这意味着我们不需要标准化常数来从 q(x) 中采样。
????????我们现在知道如何定义分布,并在知道分数的情况下从中抽取样本。最后,我们可以使用路径积分表示来定义帮助我们学习分数的训练目标。注意如果我们离散化动作(指数中的事物)会发生什么;我们得到类似 e^{-(x_{t+1} - x_t -? F_t)2 / 4?} 的值,其中 F_t = -𝛁 V(x_t)。现在这只是一个正态分布,它与我们之前的转换核公式具有相同的形式。我们发现,除了它是物理学中任何人都知道如何处理的唯一函数之外,我们还有一个非常令人信服的理由为什么我们应该选择高斯函数。如果我们也离散化通过测量,我们将找到一个无限的转移核乘积,它再现了我们之前的马尔可夫序列方程。
????????除此之外的总结:
- 福克-普朗克方程告诉我们,存在一个具有我们期望值 p(x) 的平稳分布,并且力由得分函数给出。
- Langevin 方程可以从 p(x) 中抽取样本。
- 离散化路径积分可再现马尔可夫序列,可用于创建损失函数来优化我们的模型。
5.2 朗之万放在一边
????????请随意跳过这一点。仅供参考,有更好的方法来采样高维函数,并且许多聪明人花了很多时间思考它们。在这里,我只是想证明Langevin MCMC的这种方法确实有效。下面是一些代码,将使用 Pytorch 计算我制作的随机函数的对数梯度,然后使用 20k 样本运行 Langevin MCMC 1000 个步骤
import torch
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import quad
# pick any random distribution to sample from
numpy_fn = lambda x: (0.2 + np.cos(2 * x) ** 2) * np.exp(- 0.1 * x ** 2)
norm = quad(numpy_fn, -np.inf, np.inf)[0]
torch_fn = lambda x: ((0.2 + torch.cos(2 * x) ** 2) * torch.exp(- 0.1 * x ** 2) ) / norm
# Run Langevin MCMC
samples, steps, eps = 20000, 1000, 5e-2
x = (2 * torch.rand(samples, requires_grad=True) - 1) * 10
for _ in range(steps):
potential = torch.autograd.grad(torch.log(torch_fn(x)).sum(), [x])[0]
noise = torch.randn(samples)
x = x + eps * potential + np.sqrt(2 * eps) * noise
# Plot against the true distribution
y = torch.linspace(-2 * np.pi, 2 * np.pi, 100)
plt.plot(y, torch_fn(y), 'k--')
plt.hist(x.detach().numpy(), density=True, bins=300)
plt.xlim(-2 * np.pi, 2 * np.pi)如果运行代码,您应该得到如下结果:
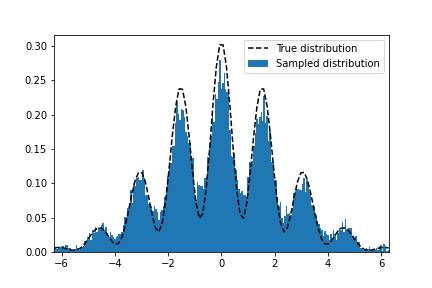
不过我不会撒谎,这个例子是精心挑选的。使用马尔可夫链蒙特卡罗 (MCMC) 方法进行正确采样本身就是一项精细磨练的技能,但希望您可以放心,这至少在理论上是有效的!
六、训练扩散模型
6.1 导出损失函数
????????当 t 趋于无穷大时,我们希望生成分布 p(x_t) 与观察到的分布 p_data(x) 相匹配。然而,由于无穷大很难处理,所以让我们做一些奇怪但符合文献的事情。假设在时间 t=0 时,我们得到所需的分布 p(x, t=0) = p_data(x)。然后,不失一般性,我们强加在未来的某个时间 t=T,我们已经充分破坏(扩散)了我们的分布,使得 p(x, t=0) = N(x |0, 1)。最后,我们需要一个损失来使观察到的分布和参数化分布更加接近。我们可以通过最小化它们的KL 散度来做到这一点,这给了我们看似简单的目标L = — ∫p_data(x_0) ln p(x_0; 𝜗) dx_0。
????????像往常一样,p_data 是不可积的(我们不知道,但我们确实有来自它的样本,即数据集)。通过将积分替换为观察数据集的随机小批量的求和(积分 <=> 求和 swap-a-roo),可以以通常的方式克服这个问题。对数项是最困难的一项。使用我们完全扩展的马尔可夫形式,以及它带来的所有烦人的积分,我们可以这样写:

????????这里我们使用简写 dx_1:T = dx_1…dx_T
????????从这里开始,我们需要删除积分并进行简化,直到我们得到可以编码的东西。这样做是一项艰巨的任务,因此我将概述您需要的主要见解。完整的推导可以在随附的注释中找到。
6.2 通过重要性采样去除积分
????????首先我们需要处理那些烦人的积分。为此,我们将使用一个古老的技巧:重要性采样。如果您有像 ∫ f(x) dx 这样的积分给您带来麻烦,您可以将其近似为其他分布 q( X)。如果您想听起来很奇特,您可以说您从退火重要性采样和 Jarzynski 等式中获得了这个想法的灵感。我们将分布称为 q(x_0, …, x_T)。任何分布都可以,但问题是,我们选择什么?答案是我们能找到的最便宜的答案。
幽默一下:我有一次出国旅行,觉得从当地的葡萄酒商店带几瓶葡萄酒回家会很好。当时我还是一个身无分文的学生,不用说我正在经历一些轻微的贴纸冲击。我不知所措,轻轻走到店主面前,小声礼貌地询问最便宜的瓶子是什么。下一秒,店主惊愕地瞪大了眼睛,一掌拍在桌子上,大声呵斥道:“我们不卖廉价酒!”?我想指出的是,作为一名学生不仅意味着你一文不名,还意味着你很尴尬。因此,我对这个咆哮的店主的反应是眯起眼睛,就好像我正在重演Futurama Fry meme一样,然后回答:“好吧……但根据定义,至少其中一种葡萄酒必须是最便宜的,对吧?”?店主很不安地把她的手从桌子上抬起来,把指关节转向我,用拇指捏住其他手指。然后她向前倾身,用平静得多的声音向我解释说:“最便宜的。没什么便宜的。我可以卖给你最便宜的酒。”?直到今天,我都确保永远不会索要便宜的东西。我总是要求最便宜的🤌。
????????这就是扩散模型的扩散部分发挥作用的地方。基本扩散过程几乎是我们可以为 q(x_0, …, x_T) 构造的最简单的马尔可夫分布,它允许解析表达式。现在让我们为两个发行版指定名称:
????????前向(破坏性/扩散)过程:q(x_0, …, x_T)。这就是我们将分析解决的用于重要性采样的扩散。
????????向后(生成)过程:?p(x_0, …, x_T)。这是包含我们可学习参数和转换内核的东西,并将用于生成样本。
????????现在的损失是:
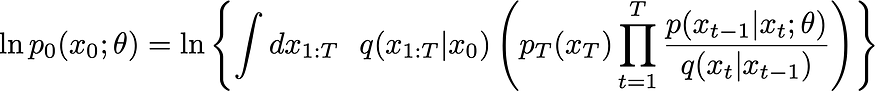
6.3 使用证据下限 (ELBO)
????????技巧#2 是另一个熟悉的技巧(在本例中为近似值)。使用 Jensen 不等式来优化 ELBO。这意味着您可以将对数移至积分和 q(x_1:T | x_0) 之上:
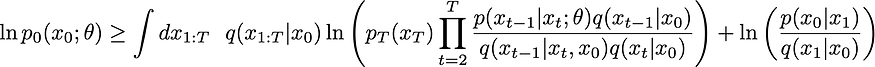
进行一些取消并进一步简化,最终您将能够用 KL 散度来表达这一点

等式。DDPM 文件的 A.21?。没有 KL 散度。
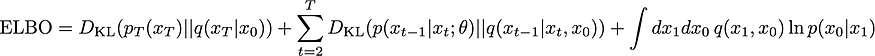
随着KL分歧。
这是一般?形式。
6.4? 将正向过程转变为扩散过程
????????到目前为止,我们还没有谈论过前向过程或后向过程,只是它们是马尔可夫过程。现在让我们为了易于处理而牺牲通用性,将前向过程变成扩散过程。我们将遵循去噪扩散概率模型(DDPM) 论文中的方法,并对前向过渡内核做出以下选择(技巧 #3!)

????????请注意,此选择特定于 DDPM 扩散。它不是所有扩散模型的通用方程。
????????其中 ?_t 是固定的、与时间相关的值。我们可以看到,它们很容易通过方差 β_t = 1 —?_t 与不同时间的噪声方差相关。
6.5 稍后选择较大的方差
????????我们对扩散核的选择可能看起来完全是随机的,但实际上非常聪明。请注意,扩散过程是由其方差定义的,在这里我们决定方差应该与时间相关。之前的计划将奇迹般地使 q(x_t | x_0) 以封闭形式进行分析(如注释所示),并确保方差不会随着时间的推移而爆炸。
????????我还想发表一项重要言论。随着样本距离 p_data(x) 越来越远,选择逐渐增大的方差对于扩散模型的性能至关重要。直觉上,你可以这样想。
????????假设您远离分布的中心。对你来说,它可能看起来类似于天空中的星星——所有形状、凹凸和特征都模糊成远处某个地方的一个聚焦点。在这个阶段,采取大的跳跃是有意义的,直到你足够接近以更好地解决距离,然后才减少跳跃的大小。否则,您将花费大量时间优化与太空旅行的正确方向无关的随机事物。
6.6 将后向(生成)内核定义为高斯
????????不管你相信与否,到目前为止,生成过程仍然是普遍的。如果你把物理学放在一边,那么下一步的动机应该是清楚的。如果没有,请认为这是一个简单的选择。我们将通过具有可学习均值和固定方差的正态分布来参数化后向核:p(x_t | x_{t-1}) = N(μ(x, t; 𝜗), β(t))。这会将大量积分转换为两个高斯函数之间的 KL 散度,并且一般来说,会使大部分数学变得更简单。最终,您会发现总损失是每个可能时间步的损失之和,并且每个损失具有相同的形式。结果是:

????????根据定义的方差,我们定义 β_t = 1 — ?_t。我们还将 ?_t bar 定义为截至时间 t 的所有 alpha 的乘积:∏_0^t ?_t。
其中 L_{t-1} 是第 (t-1) 个时间步的损失,最后一步涉及仅根据噪声 ? 重写它,以便我们得到:

第一个方程是 ?_𝜗 的定义,第二个方程是 x_t 的定义,第三个方程是所需的损失
μ 项仅在采样时才需要记住。
6.7 最终结果,去噪目标
????????损失表达式非常简单,也直观。它表示在任何给定的时间步长,都会有一定量的高斯噪声应用于输入,我们的任务是预测它(因此去噪)。这表明了以下简化,在实践中结果证明性能更高:降低损失函数中的系数。我们终于达到了扩散算法。在这里,我将从原始论文中复制/粘贴算法,而不是重新输入它

资料来源:Ho、Jonathan、Ajay Jain 和 Pieter Abbeel。“去噪扩散概率模型。”?神经信息处理系统的进展33(2020):6840–6851。
σ_t 只是标准差,由 √(1-?_t) 给出(老实说,不知道为什么他们不能直接这么写🤷?♂?)。
6.8 采样
????????我略过这一点,但由于我们有正态分布,所以抽样很容易推导出来。上述推导来自重参数化技巧,即可以通过首先采样 z ~ N(0, 1),然后计算 x = μ + σ z 来从 x ~ N(μ, σ) 中采样。通过从 x_T 开始采样,然后向后采样,我们发现 x_{T-1} ~ p(x_{T-1} | x_T) 很容易采样,这意味着 x_{T-2} ~ p(x_{T -2} | x_{T-1}) 很容易采样等等。这也被称为祖先采样,它也包含更复杂的图形条件依赖关系。
????????为了完整起见,如果您查看算法 2 中的步骤 (4),请注意它具有朗之万方程的形式,正如我们之前讨论的那样。
七、故障排除
7.1 输入不良的问题
????????当我第一次阅读最终的 DDPM 算法时,说实话,我对它竟然能起作用感到非常震惊。为什么我们的模型能够通过消除一些随机高斯噪声来获取任何信息?当我们的数据点 x 远离分布中心时,这将如何工作?当我们实际上只是及时得到一个快照时,我们如何才能学习动态呢?
????????对于第一个问题,答案是如果你看看等式:(5) 在训练算法中,我们实际上将噪声输入到模型中。这里的关键点是,我们也在时间中进食。额外的信息似乎会产生影响。我的猜测是,它允许模型推断它与真实分布的接近程度,并使用它来更好地过滤噪声。
????????对于第三个问题,我认为答案是集成。如果平衡分布已知,写出福克-普朗克方程就会很简单。无论如何,这就是它们最初设计的目的。一般来说,我们可以通过(a)长时间模拟一些粒子或(b)在较短的时间内模拟大量粒子来确定平衡。当你获得越来越多的数据时,我认为你会越来越接近选项(b),这就是为什么它有效。
????????对于第二个问题,答案是不会。哈哈。我不会伤害研究此问题的 OG 作者,因此我会参考他自己的博客来讨论此问题。在“基于分数的朴素生成建模及其陷阱”部分标题下,您将找到要点。简而言之,低密度区域完全被损失函数所困扰。下面是学习左下角和右上角两个高斯流的视觉效果:
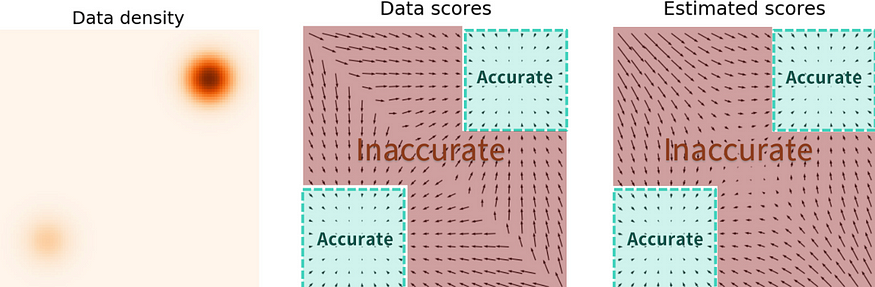
来源: https:?//yang-song.net/blog/2021/score/
????????我认为这个问题在泊松流模型中得到了一定程度的解决,因为这些模型偏向于再现单极子场。但是,我没有证据支持这一点。
7.2 高差异
????????最糟糕的感觉是看着你的扩散模型慢慢地越来越接近一个相当好的图像,结果却大喊“skrt skrrrrtttt”,并在最后一刻突然转向看起来像是 90 年代的电视,调到了 100 频道。步骤之间需要权衡。大小和方差。较小的方差+更多的步数总是能够更准确地表示随机 ODE,但它的计算量也更大。这里一定要注意。
八、编码
????????让这些东西在实践中发挥作用实际上可能有点烦人,主要是由于上一节中有关低密度区域的问题 (2)。您需要确保先验分布是在能够通过扩散从真实目标分布到达的区域中采样的。此外,您还需要调整扩散步骤的数量和方差表。其他一些论文(参见改进的去噪扩散概率模型)着手优化这些东西,并发现用一些简单的一维时间函数替换我们导出的花哨的离散方差表可以做得更好。
就编码而言,它实际上非常简单。你需要:
- 该模型将向量 x 和时间 t 作为输入,并返回与 x 维度相同的另一个向量 y。具体来说,该函数类似于 y = model(x, t)。根据您的方差计划,对时间 t 的依赖性可以是离散的(类似于变压器中的令牌输入)或连续的。如果它是离散的,你可以使用老式的变压器位置编码(无耻的自插),如果它是连续的,你可以使用高斯随机特征。
- 一个 Mixin,处理特定模型的所有调度、采样和去噪损失计算。
为了说明其工作原理,我们将尝试使用扩散模型来学习简单的 2D 螺旋图案。这是2015 年原始论文中使用的玩具数据集,因此我们将使用 DDPM 重做它。
对于示例调度程序,您可以在此处查看 DDPM 类。为了方便起见,我复制/粘贴如下:
import torch
from torch import nn
class DDPM(nn.Module):
"""Dataclass to maintain the noise schedule in the DDPM procedure of discrete noise steps
Mathematically, the transition kernel at time $t$ is defined by:
$$
q(x_t|x_{t-1}) = \mathcal{N}(x_t| \sqrt{\alpha_t} x_{t-1}, 1 - \alpha_t)
$$
We further define quantities $\beta$ and $\bar \alpha$ in terms $\alpha$:
$$
\beta_t \equiv 1 - \alpha_t
$$
$$
\bar \alpha_t = \prod_{t' < t}\alpha_{t'}
$$
which will be useful later on when computing transitions between non adjacent times.
"""
def __init__(self, n_steps: int, minval: float = 1e-5, maxval: float = 5e-3):
super().__init__()
assert 0 < minval < maxval <= 1
assert n_steps > 0
self.n_steps = n_steps
self.minval = minval
self.maxval = maxval
self.register_buffer("beta", torch.linspace(minval, maxval, n_steps))
self.register_buffer("alpha", 1 - self.beta)
self.register_buffer("alpha_bar", self.alpha.cumprod(0))
def diffusion_loss(self, model: nn.Module, inp: torch.Tensor) -> torch.Tensor:
device = inp.device
batch_size = inp.shape[0]
# create the noise perturbation
eps = torch.randn_like(inp, device=device)
# convert discrete time into a positional encoding embedding
t = torch.randint(0, self.n_steps, (batch_size,), device=device)
# compute the closed form sample x_noisy after t time steps
a_t = self.alpha_bar[t][:, None]
x_noisy = torch.sqrt(a_t) * inp + torch.sqrt(1 - a_t) * eps
# predict the noise added given time t
eps_pred = model(x_noisy, t)
# Gaussian posterior, i.e. learn the Gaussian kernel.
return nn.MSELoss()(eps_pred, eps)
def sample(self, model: nn.Module, n_samples: int = 128):
with torch.no_grad():
device = next(model.parameters()).device
# start off with an intial random ensemble of particles
x = torch.randn(n_samples, 2, device=device)
# the number of steps is fixed before beginning training. unfortunately.
for t in reversed(range(self.n_steps)):
# apply the same variance to all particles in the ensemble equally.
a = self.alpha[t].repeat(n_samples)[:, None]
abar = self.alpha_bar[t].repeat(n_samples)[:, None]
# deterministic trajectory. eps_theta is similar to the Force on the particle
eps_theta = model(x, torch.tensor([t] * n_samples, dtype=torch.long))
x_mean = (x - eps_theta * (1 - a) / torch.sqrt(1 - abar)) / torch.sqrt(
a
)
sigma_t = torch.sqrt(1 - self.alpha[t])
# sample a different realization of noise for each particle and propagate
z = torch.randn_like(x)
x = x_mean + sigma_t * z
return x_mean # clever way to skip the last noise addition????????对于离散时间和连续时间情况下的一些示例模型,您可以查看此处的代码。
????????训练过程与正常训练过程几乎相同,只是您的批次中没有目标,并且您必须使用 DDPM 调度程序中的扩散_损失方法来计算损失。您可以在DDPM 包的main.py 脚本中找到训练循环。
????????如果训练成功,您会发现生成的分布如下所示:
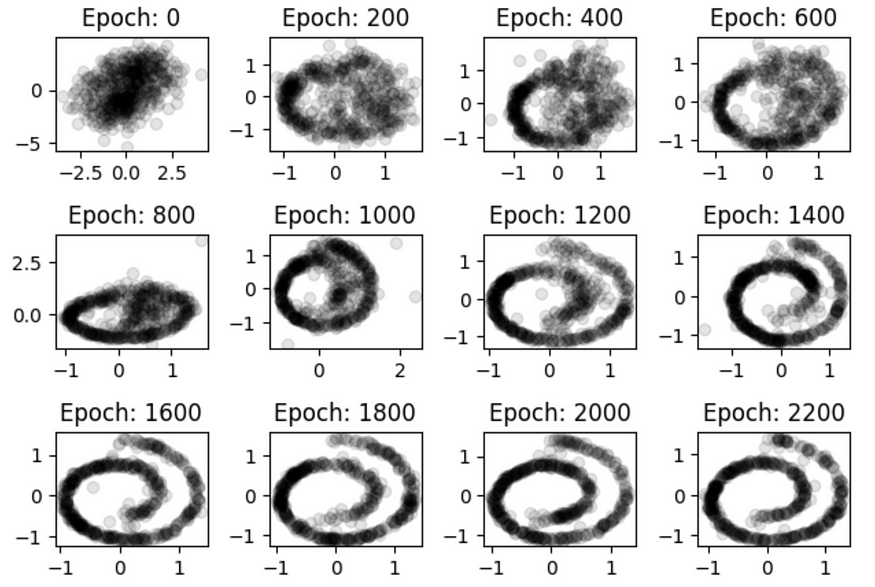
从随机的高斯斑点发展到整齐有序的螺旋。
九、把事情包起来
????????在过去的几年里,扩散空间中的事物发展得非常快,这是有充分理由的。最近(2022 年)的一些模型(例如 Dalle-2、StableDiffusion 和 Midjourney)的结果至少可以说是令人惊讶的。结合当前对生成式人工智能的热情,新的发展正在快速发生。因此,除了本文之外,还有很多令人兴奋的事情值得探索。
????????首先,我没有提到任何流行的文本到图像模型。这些是大型、复杂的多模式架构,其中有许多 GPU 超出了本文的范围。进一步研究的其他途径可能包括实际训练扩散模型的更好方法。我只是简单地提到,已经有一些关于优化这些的研究,但当然,您还可以进行更深入的研究。另一个有趣的途径是观察条件模型。我提到的一些论文也谈到了这一点,但我不想走得太远。在引导这些扩散模型走向特定结果方面已经有很多有趣的工作,无论是阶级条件作用还是其他。其他研究领域着眼于新颖性和保真度之间的权衡,以及如何以其他方式(例如负采样)调整输出。
????????对我来说,在开始这篇博文之前我想要回答的最大问题是,“这些东西实际上是如何工作的,为什么?”?我希望这篇文章至少给出了一些部分令人满意的答案 !
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 社科院与美国杜兰大学金融管理硕士项目—用智慧和勇气,书写2024新篇章
- 面向对象编程(写程序的套路)
- 训练属于自己的大模型LM Studio使用记录
- 新字符设备驱动中-goto对于错误的处理方法
- 任务11:使用FTP下载NCDC气象数据
- 选岗到上岸
- Java快捷键
- [③Meson]: run_command()命令使用
- 最新版xposed编写教程
- NetApp 利用适用于混合云的实时解决方案解决芯片设计方面的数据管理挑战