【Python】编程练习的解密与实战(二)

?🌈个人主页:Sarapines Programmer
🔥?系列专栏:《Python | 编程解码》
?诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。
 ?
?
目录
🪐1. 初识Python
Python是一种高级、通用、解释型的编程语言,具有简洁而清晰的语法,被广泛应用于软件开发、数据科学、人工智能等领域。以下是Python技术的一些主要特点和应用领域:
易学易用: Python的语法设计简单,容易学习和理解。这使得它成为初学者和专业开发人员的首选语言之一。
开源: Python是开源的,任何人都可以查看、修改和分发其源代码。这为开发者提供了自由和灵活性。
跨平台: Python可在多个操作系统上运行,包括Windows、Linux和macOS,使其成为跨平台开发的理想选择。
强大的社区支持: Python拥有庞大的全球开发者社区,用户可以获得丰富的文档、库和工具,方便解决各类问题。
广泛应用领域: Python在多个领域都有应用,包括Web开发、数据科学、机器学习、人工智能、自动化测试、网络编程等。
丰富的第三方库: Python拥有丰富的第三方库和框架,如NumPy、Pandas、Django、Flask等,提供了强大的工具来简化开发流程。
动态类型: Python是一种动态类型语言,允许开发者更加灵活地进行变量和对象的操作。
面向对象编程: Python支持面向对象编程,使得代码结构更加模块化、可维护性更强。
总体而言,Python是一门功能强大、灵活易用的编程语言,适用于各种规模和类型的项目,从小型脚本到大型应用,都能够得心应手。
🪐2. 实验报告二
🌍实验目的
-
掌握Jupyter Notebook编程工具的基本用法:
- 学习如何使用Jupyter Notebook进行编程。
- 掌握Jupyter Notebook的基本界面和操作方法。
-
理解并熟悉函数声明、定义及调用:
- 理解函数的声明,即如何定义一个函数的名称和参数。
- 学习如何在Python中定义函数,包括函数体内的代码块。
- 熟悉函数调用的方法,了解如何使用函数并传递参数。
🌍实验要求
-
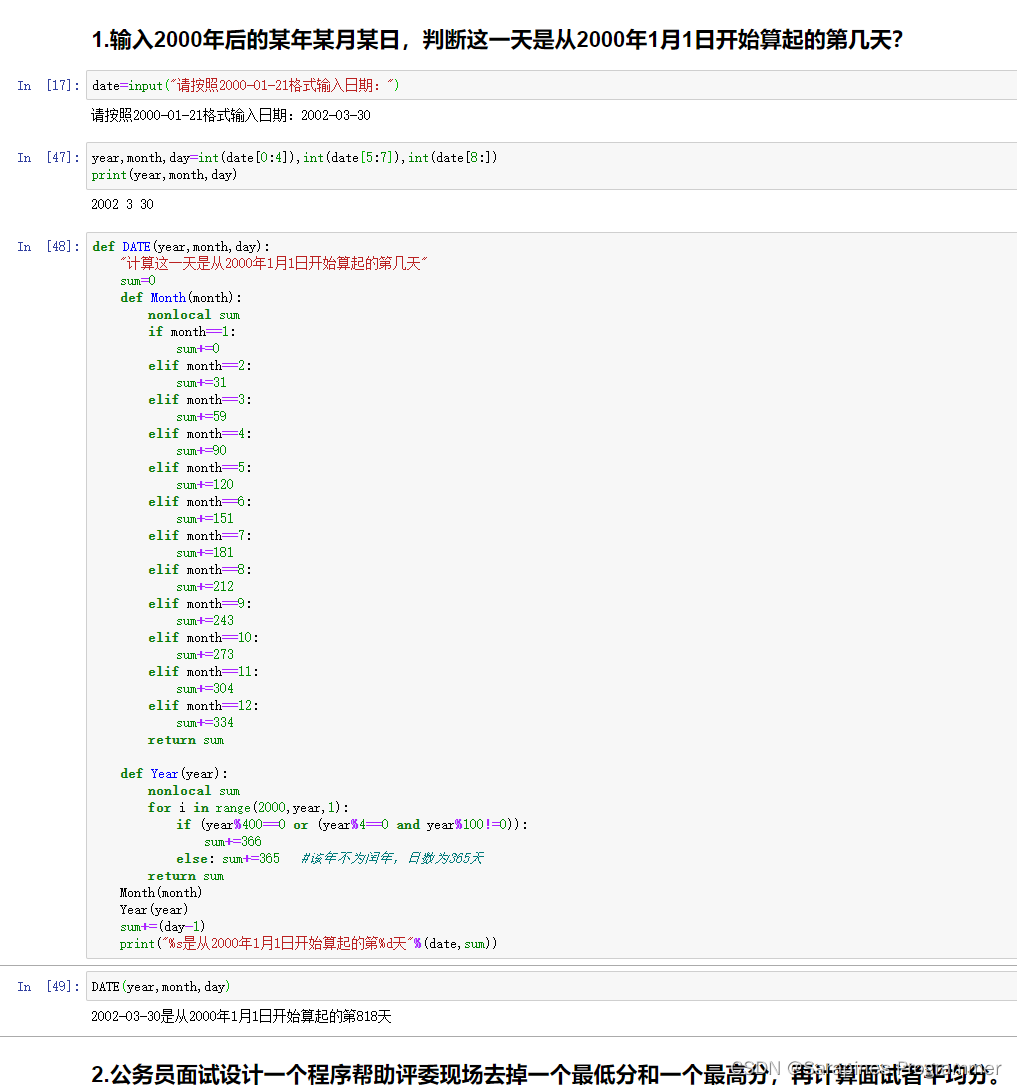
输入2000年后的某年某月某日,判断这一天是从2000年1月1日开始算起的第几天?
-
公务员面试设计一个程序帮助评委现场去掉一个最低分和一个最高分,再计算面试者平均分。
-
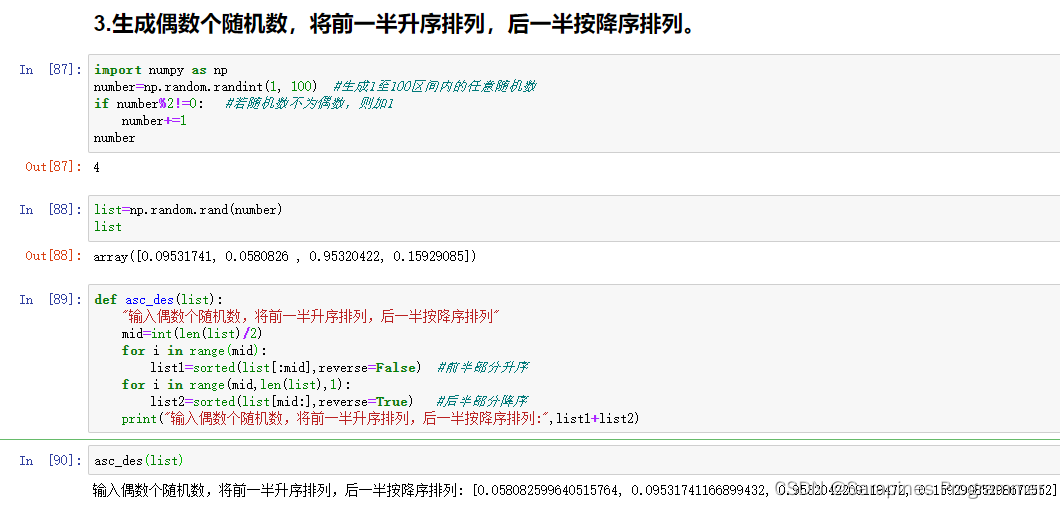
生成偶数个随机数,将前一半升序排列,后一半按降序排列。
-
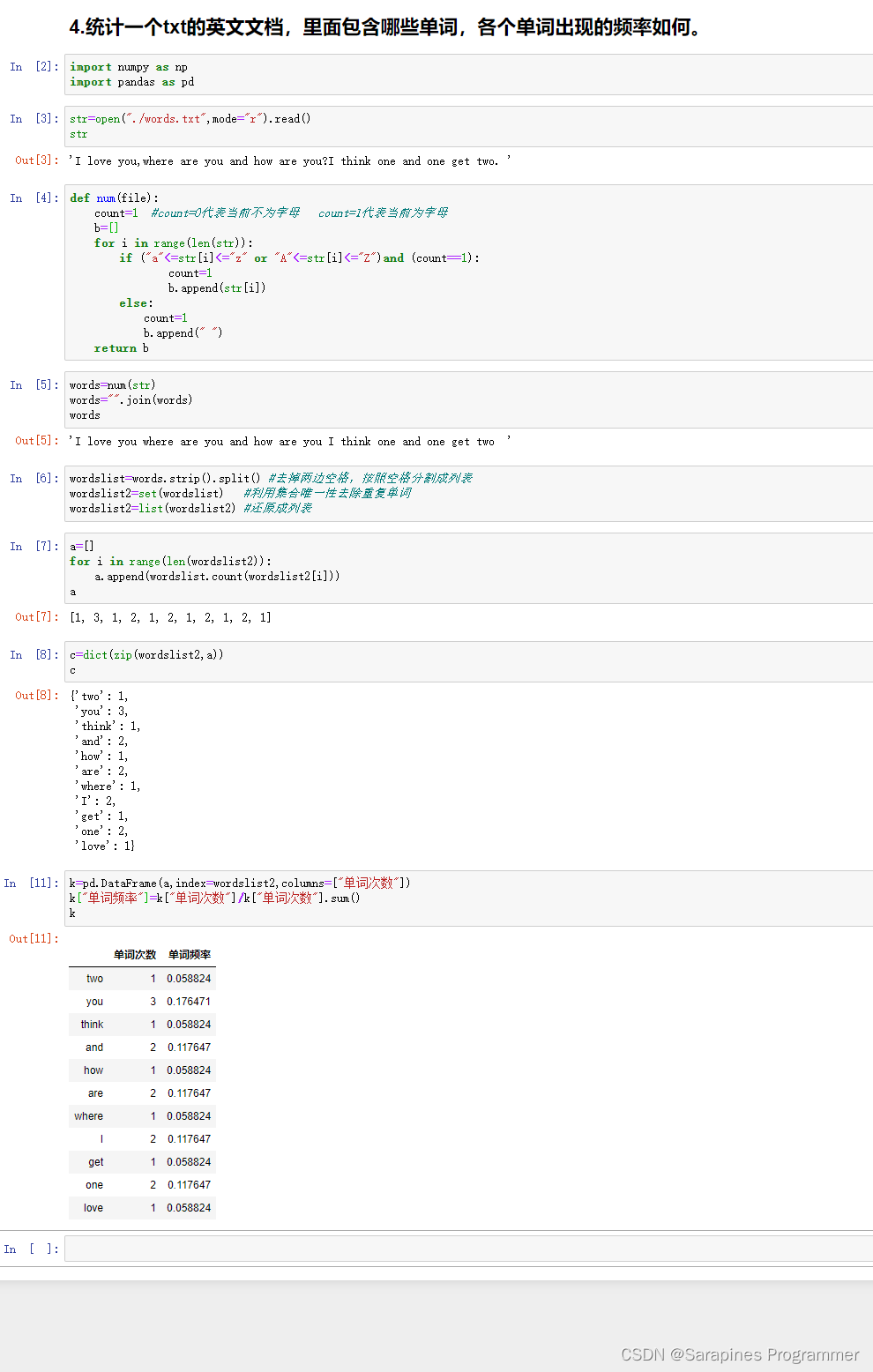
统计一个txt的英文文档,里面包含哪些单词,各个单词出现的频率如何。
🌍实验代码
1.?输入2000年后的某年某月某日,判断这一天是从2000年1月1日开始算起的第几天?
date=input("请按照2000-01-21格式输入日期:")
year,month,day=int(date[0:4]),int(date[5:7]),int(date[8:])
print(year,month,day)
def DATE(year,month,day):
"计算这一天是从2000年1月1日开始算起的第几天"
sum=0
def Month(month):
nonlocal sum
if month==1:
sum+=0
elif month==2:
sum+=31
elif month==3:
sum+=59
elif month==4:
sum+=90
elif month==5:
sum+=120
elif month==6:
sum+=151
elif month==7:
sum+=181
elif month==8:
sum+=212
elif month==9:
sum+=243
elif month==10:
sum+=273
elif month==11:
sum+=304
elif month==12:
sum+=334
return sum
def Year(year):
nonlocal sum
for i in range(2000,year,1):
if (year%400==0 or (year%4==0 and year%100!=0)):
sum+=366
else: sum+=365 #该年不为闰年,日数为365天
return sum
Month(month)
Year(year)
sum+=(day-1)
print("%s是从2000年1月1日开始算起的第%d天"%(date,sum))
DATE(year,month,day)
2.?公务员面试设计一个程序帮助评委现场去掉一个最低分和一个最高分,再计算面试者平均分。
score=input("请输入评委打分项列表(以空格隔开):")
def avag(list):
"求均为字符串类型列表的平均值"
add,count=0,0
for i in range(len(list)): #字符串元素转化为整型元素
list[i]=int(list[i])
list.sort()
for i in range(1,len(list)-1,1):
add+=list[i]
count+=1
print("评委现场去掉一个最低分和一个最高分,面试者平均分为:%.2f"%(add/count))
avag(score.split(" "))
3.?生成偶数个随机数,将前一半升序排列,后一半按降序排列。
import numpy as np
number=np.random.randint(1, 100) #生成1至100区间内的任意随机数
if number%2!=0: #若随机数不为偶数,则加1
number+=1
number
list=np.random.rand(number)
list
def asc_des(list):
"输入偶数个随机数,将前一半升序排列,后一半按降序排列"
mid=int(len(list)/2)
for i in range(mid):
list1=sorted(list[:mid],reverse=False) #前半部分升序
for i in range(mid,len(list),1):
list2=sorted(list[mid:],reverse=True) #后半部分降序
print("输入偶数个随机数,将前一半升序排列,后一半按降序排列:",list1+list2)
asc_des(list)4.?统计一个txt的英文文档,里面包含哪些单词,各个单词出现的频率如何。
import numpy as np
import pandas as pd
str=open("./words.txt",mode="r").read()
str
def num(file):
count=1 #count=0代表当前不为字母 count=1代表当前为字母
b=[]
for i in range(len(str)):
if ("a"<=str[i]<="z" or "A"<=str[i]<="Z")and (count==1):
count=1
b.append(str[i])
else:
count=1
b.append(" ")
return b
words=num(str)
words="".join(words)
words
wordslist=words.strip().split() #去掉两边空格,按照空格分割成列表
wordslist2=set(wordslist) #利用集合唯一性去除重复单词
wordslist2=list(wordslist2) #还原成列表
a=[]
for i in range(len(wordslist2)):
a.append(wordslist.count(wordslist2[i]))
a
c=dict(zip(wordslist2,a))
c
k=pd.DataFrame(a,index=wordslist2,columns=["单词次数"])
k
k["单词频数"]=k["单词次数"]/k["单词次数"].sum()
k🌍实验结果
1.问题一
 ?
?
2.问题二
 ?
?
3.问题三
 ?
?
4.问题四
 ?
?
🌍实验体会
-
问题一 - 计算日期对应的天数:
- 使用字符串切片提取年、月、日,并使用int()进行转化。
- 编写DATE函数,嵌套判断年、月、日的天数,考虑闰年的特殊情况。
-
问题二 - 计算平均分(去掉最高分和最低分):
- 利用split将输入的字符串转化为列表。
- 使用for循环将每个字符串类型数字转化为整型,排序后去除两端,求和取平均。
-
问题三 - 生成随机数并排序:
- 生成偶数个1至100的整型随机数,如果不为偶数则加1。
- 使用for循环取前半部分和后半部分,利用sort()排序,前半部分升序,后半部分降序。
-
问题四 - 统计英文文档中单词及频率:
- 读取txt文档,使用count计数器判断字母与非字母。
- 利用列表b[]保存读取的单词,去除多余符号,转化为str,使用strip()、split()处理。
- 利用集合去重,统计各单词出现次数,使用pandas的DataFrame表示单词及频率。
📝总结
Python领域就像一片未被勘探的信息大海,引领你勇敢踏入Python数据科学的神秘领域。这是一场独特的学习冒险,从基本概念到算法实现,逐步揭示更深层次的模式分析、匹配算法和智能模式识别的奥秘。
渴望挑战Python信息领域的技术?不妨点击下方链接,一同探讨更多Python数据科学的奇迹吧。我们推出了引领趋势的💻 Python数据科学专栏:《Python | 编程解码》,旨在深度探索Python模式匹配技术的实际应用和创新。🌐🔍
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 11-流媒体-LibRtmp推H264流
- python学习2
- RabbitMQ的基本使用,进行实例案例的消息队列
- 基于SSM的校园快递管理系统
- 对STM32 DMA突发传输的理解
- 期末复习.操作系统(第四版)——前三章
- 一本书全面搞懂分布式架构中如何使用RocketMQ的原理和实战案例
- QT-CAD-3D显示操作工具
- Ajax基础入门_Ajax概述,同步与异步,Axios的使用,JSON数据及FastJSON的使用
- What is `addArgumentResolvers` does in `WebMvcConfigurer` ?