人工神经网络(一):CNN、Transformer网络的应用
一、实验目的和要求
1.1 学习情况考察
考察学生对于人工神经网络课程呢的学习情况
1.2 深入研究人工神经网络应用
学习不同领域、不同任务下,不同网络的应用。
二、实验内容与方法
2.1 猫咪分类
2.1.1任务简介:
根据所学的人工神经网络的知识对十二种猫进行分类,属于CV方向经典的图像分类任务。图像分类是计算机视觉领域的一个基本任务,其目标是将输入的图像分配给某个预定义的类别(即标签)。
2.1.2数据集介绍:
(1)数据集包含12种猫的图片,并划分为训练集与测试集。
(2)训练集:提供图片以及图片所属的分类,共有2160张猫的图片,含标注文件。
(3)测试集:仅提供彩色图片,共有240张猫的图片,不含标注文件。
2.1.3任务要求:
分别使用CNN网络以及Transformer网络实现2种不同的基于深度学习的识别方式,可以使用预训练模型,测试集的识别率大于等于0.9,为此,该任务中我们采用ResNet(CNN)以及Vision Transformer(Transformer)。
2.2 新闻内容分类
2.2.1任务简介:
根据所学的人工神经网络的知识对14种新闻标题进行分类,属于NLP方向经典的文本分类任务。文本分类是计算机自然语言处理领域的一个基本任务,其目标是将输入的文本内容分配给某个预定义的类别(即标签)。
2.2.2数据集介绍:
数据集包含训练集、测试集和验证集。其中的划分如下表所示:
| 用途 | 数量 | 备注 |
| Train | 752471 | |
| Dev | 80000 | |
| Test | 83599 | 不含标签 |
标签类别有:'财经', '科技', '时政', '房产', '社会', '游戏', '家居', '时尚', '股票', '彩票', '娱乐', '教育', '星座', '体育'。
2.2.3任务要求:
分别使用CNN网络以及Transformer网络实现2种不同的基于深度学习的识别方式,可以使用预训练模型,在Dev上的识别率大于等于0.9,不建议使用参数量和计算量比较大的模型,使用pytorch和paddle框架都可以;对此,我采用的是paddle框架下的roberta(Transformer)以及RCNN(CNN)。


2.3 中英文翻译
2.3.1任务简介:
根据所学的人工神经网络的知识进行中英文翻译,属于CV方向经典的机器翻译任务,机器翻译是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。
参考项目:
https://aistudio.baidu.com/projectdetail/474524?channelType=0&channel=0
2.3.2数据集介绍:
本教程使用CWMT数据集中的中文英文的数据作为训练语料,CWMT数据集在900万+,质量较高,非常适合来训练Transformer机器翻译。
2.3.3任务要求:
使用Transformer网络实现基于深度学习的识别方式,可以使用预训练模型,不建议使用参数量和计算量比较大的模型,使用pytorch和paddle框架都可以;
三、实验步骤与过程
3.1猫咪分类
3.1.1 数据预处理
包括解压数据集、引入包、环境配置等。
3.1.2 相关定义
(1)ResNet

(2)Vision Transformer

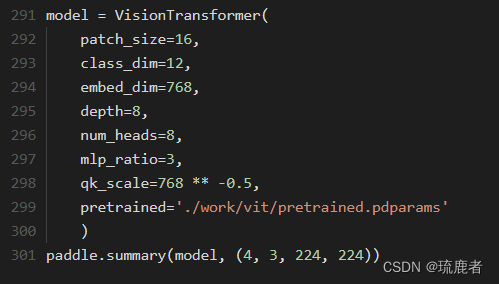
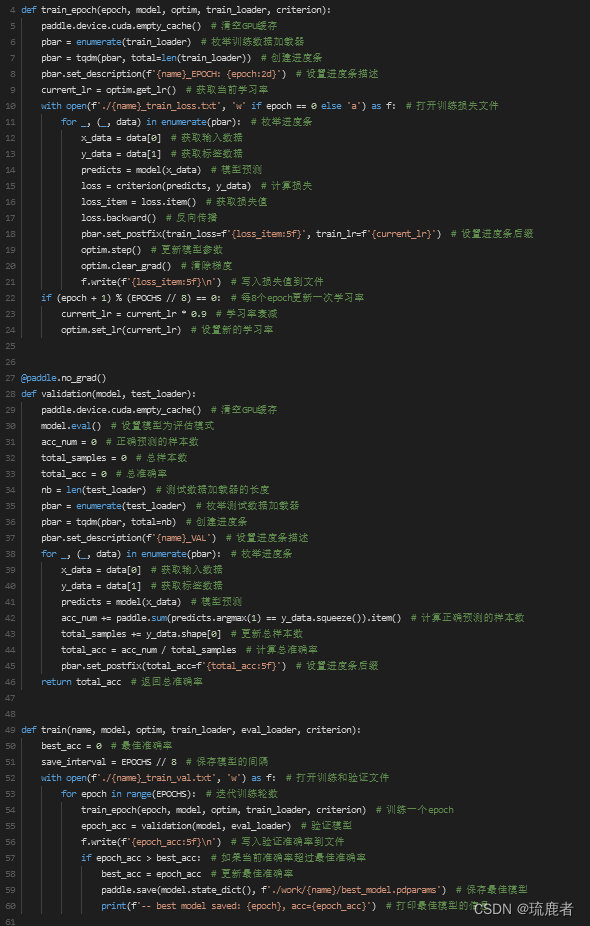
3.1.3 模型训练
首先初始化

在进行训练相关定义
(1)ResNet

(2)Vision Transformer

3.1.5模型预测
与模型预测相关定义

(1)ResNet模型预测

(2)ViT模型预测
3.2?新闻标题分类
3.2.1 数据预处理
(1)RoBERTa:
主要包括:处理数据集文件、导入包、环境配置
!!pip install paddlenlp
(2)RCNN:
主要包括:构建词汇表,生成词典、导入包、环境配置
3.2.2 相关定义
(1)RoBERTa:
包括定义了数据集对应文件及其文件存储格式、数据集加载函数、数据加载和处理函数、数据加载函数dataloader、模型训练验证评估函数以及要进行微调的预训练模型'roberta-wwm-ext-large'。
(2)RCNN:
包括定义了?NewsData、模型结构:'TextRCNN':利用`paddle.nn.Linear`构造全连接网实现多类器。
3.2.3 模型训练、评估
(1)RoBERTa:


(2)RCNN:

3.2.4 模型测试
(1)RoBERTa:


(2)RCNN:

3.3中英文翻译
3.3.1 数据预处理
包括配置环境,安装依赖,引入包、还包括包括jieba分词、bpe分词和词表、下载预训练模型。
3.3.2 相关定义
包括构造训练集、测试集、评估集Dataloader、以及构造模型。
3.3.3 模型训练

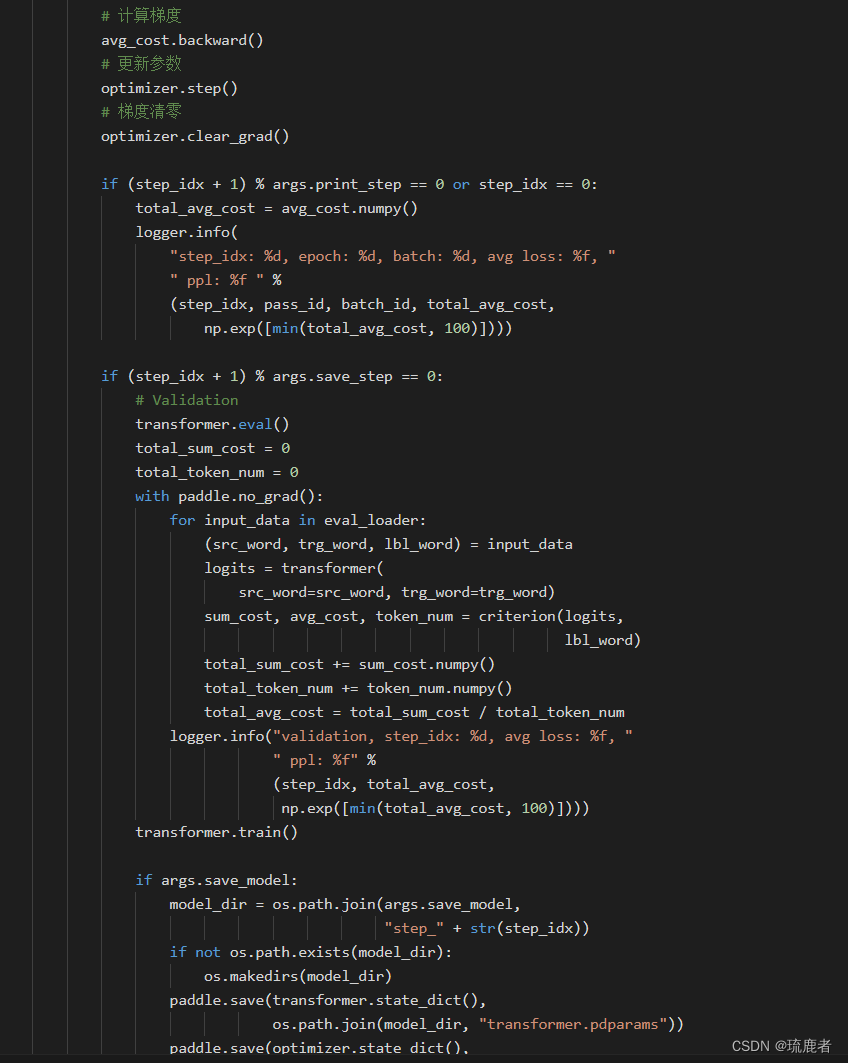

3.3.4 模型评估

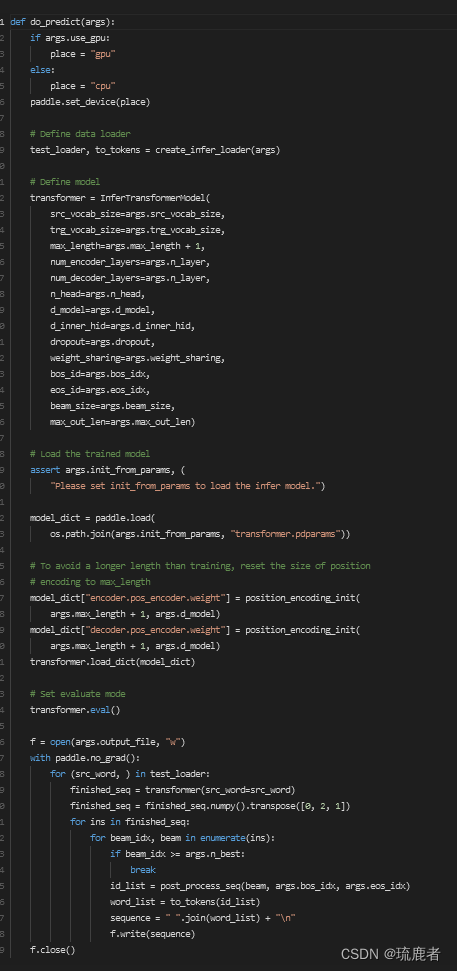
3.3.5 模型测试
四、实验结论与体会
4.1 猫咪分类
4.1.1 ACC曲线
(1)ResNet152 ACC曲线

(2)ViT ACC曲线

4.1.2 总结
训练效果:
(1)ResNet152

(2)ViT

测试效果:
(1)ResNet152

(2)ViT

4.1.3 比较
在同等训练条件下:ViT模型相比与ResNet,训练时间更长,训练参数更大,训练精度更高。
4.2 新闻标题分类
4.2.1 总结
训练效果:
(1)RoBERTa模型在验证集上的分数:
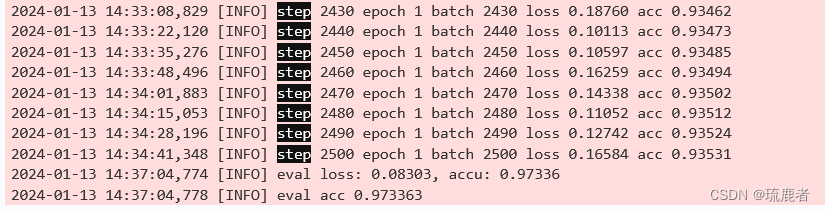
(2)RCNN模型:

预测结果:
(1)RoBERTa:
最终预测结果在result.txt中
?
(2)RCNN:

4.2.2 比较
总体而言,相比于RCNN,RoBERTa的训练时间更短,且准确率更高,在预测标题分类里展现出更卓越的性能。
4.3 中英文翻译
4.3.1 总结
训练效果:

模型评估:

即:BLEU = 38.11, 74.5/49.1/32.5/21.7 (BP=0.951, ratio=0.952, hyp_len=22252, ref_len=23371)
4.4 心得体会
4.4.1 数据集的认识:
?通过猫咪分类任务,我更加深入地理解了数据集的相关知识。包括手动编写划分数据集中训练集和验证集的能力。
4.4.2 超参数调优的必要性:
通过对不同任务的超参数调优,我们意识到模型性能的优化并不仅仅取决于网络结构,还需要仔细调整超参数。不同任务可能需要不同的学习率、批次大小等超参数,这种个性化的调整是提高模型性能的关键步骤。
4.4.3 模型性能:
在猫咪分类、新闻标题分类和中英文翻译任务中,我们采用了不同的网络结构,并在实验中灵活应用。这种灵活性能够更好地适应不同类型的任务,并在特定领域取得更好的效果,因此大量的实验发现并对比对于找到一个合适的模型来解决问题至关重要。
五、项目成果
?task1:
https://aistudio.baidu.com/projectdetail/7402499?contributionType=1
?task2:
1、classfication-news-RoBERTa
https://aistudio.baidu.com/projectdetail/7401646?contributionType=1
2、classfication-news-RCNN
https://aistudio.baidu.com/projectdetail/7401687?contributionType=1
task4:
translation-Transformer
https://aistudio.baidu.com/projectdetail/7401966?contributionType=1
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!