DUET: Cross-Modal Semantic Grounding for Contrastive Zero-Shot Learning论文阅读
文章目录

原文链接: https://ojs.aaai.org/index.php/AAAI/article/view/25114/24886
该论文设计了一种新的零样本学习范式,通过迁移语言模型中的先验语义知识,与视觉模型的特征感知能力进行对齐,以增强后者对于未见过图像的识别能力。
摘要
零样本学习(ZSL)旨在预测在训练期间从未出现样本的未知类别。作为类别级视觉特征的注释,属性是零样本图像分类的广泛使用的语义信息。然而,由于缺乏细粒度的注释以及属性不平衡和共现问题,目前的方法常常无法区分图像之间的微妙视觉差异。在本文中,作者提出了一种基于Transformer的端到端ZSL方法,命名为DUET,通过自监督多模态学习范式整合了来自预训练语言模型(PLMs)潜在语义知识。具体而言,论文中(1)开发了一个跨模态语义定位网络来研究模型从图像中分离语义属性的能力;(2)采用了属性级对比学习策略,进一步增强模型对细粒度视觉特征的区分能力,克服属性共现和不平衡问题;(3)提出了 考虑多模型目标的多任务学习策略。论文中发现,DUET在三个标准ZSL基准和一个带有知识图的ZSL基准上均取得了最先进的性能,其组成部分是有效的,预测是可解释的。
1.问题的提出
引出当前研究的不足与问题
零样本学习(Zero-shot learning, ZSL)旨在预测在训练期间从未出现过样本的未知类别。对于零样本图像分类来说,最有效且广泛使用的语义信息是属性,它们用于描述类别级别视觉特征。然而当前的方法难以区分图像间的微妙视觉差异,这不仅来源于细粒度属性注释的不足,还由于属性间的不平衡和共现现象。
属性不平衡问题
即有些属性频繁出现而有些属性很少出现
例如,在零样本场景分类数据集 SUN中,属性“树”和“云”分别与 301 和 318 个类相关联 ,而“铁路”和“消防”只与15和10个类相关联。
属性共现问题
例如,“花”与“叶”一起出现了39次,但单独的“花”只出现了10次;
这种分布偏差可能会影响模型对那些包含稀有属性或新属性组合的看不见的类的判断。

图一
解决方案
在本文中,作者提出了一种基于Transformer的端到端零样本学习方法(DUET),它通过自监督的多模态学习范式将来自预训练语言模型的潜在语义知识进行整合。
贡献如下:
(1)开发了一个跨模态语义基准网络,以研究模型从图像中分离语义属性的能力;
(2)应用了基于属性级对比学习的策略,进一步增强模型对细粒度视觉特征的区分能力,克服属性的共现和不平衡问题;
(3)提出了多任务学习策略,考虑多模型目标。该方法可以同时在连续型的属性向量和离散型/结构化属性特征场景下工作,具有比较好的迁移泛化能力。
关于监督学习,无监督学习,半监督学习,自监督学习,强化学习等
自监督学习 | (1) Self-supervised Learning入门
强化学习与监督学习和无监督学习有什么区别?
【深度学习】04 机器学习类型:监督学习 半监督学习 无监督学习 强化学习视频
深度学习常见名词概念:Sota、Benchmark、Baseline、端到端模型、迁移学习等的定义
2.数据集和模型构建
数据集
- 三个配备标准属性的 ZSL 基准数据集 AWA2、CUB、SUN及其在(Xian 等人,2019)中提出的分割
- 以及知识图谱基准数据集 AWA2-KG,它与 AWA2 具有相同的分割,但包含有关层次类和属性的语义信息,用于评估。
传统的零样本学习范式v.s. DUET学习范式
传统的零样本学习模式主要强调利用更多外部类别知识、进行数据增强,或研究更好的视觉编码器。相比而言,该框架强调跨模态模型的知识迁移(图二所示)。
传统:强调利用更多外部类别知识、进行数据增强,或研究更好的视觉编码器
DUET:强调跨模态模型的知识迁移

图二
DUET 模型总览
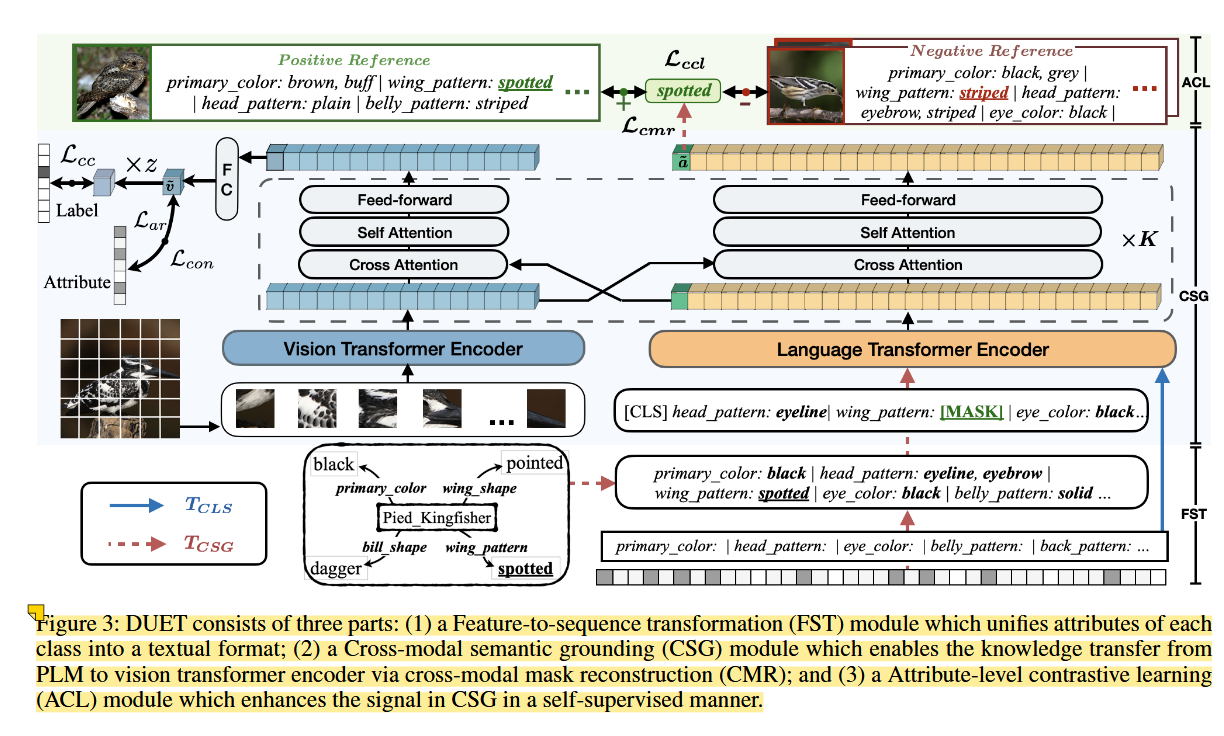
图三
DUET由三部分组成:
(1)特征到序列转换(FST)模块,它将每个类的属性统一为文本格式;
(2) 跨模态语义定位 (CSG) 模块,可通过跨模态掩模重建 (CMR) 将知识从 PLM 转移到视觉变换器编码器;
(3)属性级对比学习(ACL)模块,以自监督的方式增强CSG中的信号。
利用预训练语言模型(PLMs)的知识,以自监督的方式将知识转移到视觉转换器编码器中,从而实现对细粒度语义的有效定位。具体来说,其利用基于提示(prompt)的特征序列转换(FST),将不同类型的属性转换为文本序列。通过跨模态的语义定位网络(CSG,Cross-modal Semantic Grounding)和属性级对比学习(ACL,attribute-level contrastive learning)机制,利用跨模态的掩码复原(CMR,cross-modal mask reconstruction)训练目标从PLM中传递语义知识,同时缓解属性不平衡和共现问题,提高模型对细粒度视觉特征的区分能力。
属性级别对比学习
本文引入了一个巧妙的属性级别对比学习的模式,让模型来重点关注那些整体相似的图像中,容易造成困扰的细粒度特征差异。
-
第一步是属性值序列化,文章从nlp中广泛运用的prompt中获得启发,借鉴表格预训练中的序列化模式,将图片属性值以key: [value,…]的形式进行文本序列化。这样做的好处是可以兼容多种不同的属性格式,包括知识图谱(KG)形式,向量形式,离散格式。当然,为了增加属性分布的多样性(diversity),作者对属性列表进行了基于概率的剪枝(attributes pruning),目的是为了防止模型因为属性的频繁共现而陷入懒惰学习。

-
跨模态的掩码复原。图像和文本同时输入,文本掩码,让模型强制从图像信息中获得相关属性来恢复掩码。这种方法其实在早期的多模态预训练模型中非常见,目的是让模型对齐视觉/语言的理解。而本文用一种巧妙的方法,让视觉模型的零样本学习能力得到了强化:
– 使用预训练的语言模型(Bert)+预训练视觉模型(ViT,Swin,DeiT等),通过添加跨模态注意力层(cross-attention layer)进行桥接,而不是直接用多模态预训练模型。这样的好处是可以最大程度利用语言模型的语义信息和视觉模型的理解能力。
– 在视觉模型选择上,规避掉了使用ImageNet-21K进行预训练的模型,避免零样本测试过程中样本泄露。(测试集的图片不应该在预训练过程见过)
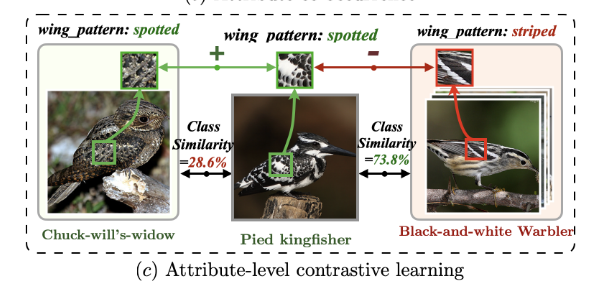
– 属性级别的对比学习(Attribute-level Contrastive Learning)。本文的核心贡献点,可以用图1c表示:对于一个目标样本,选择与其整体特征相似度高的作为负样本,与其整体特性相似度低的作为正样本。对于一个正负样本对,其需要与目标样本有公共的属性key(比如“羽毛图案”),在这种情况下,对负样本的要求是,其他属性尽可能相似,而“羽毛图案”不同; 对正样本的要求是,其他属性尽可能不同,而“羽毛图案”相同;最后,在属性的掩码-恢复过程中,模型被迫找到两个差异悬殊图片中细粒度的属性交集,两个非常相似图片中细粒度的属性差异,从而实现属性感知的解耦。
正负样本解释:
对于目标样本:
正样本:与其整体特性相似度低,其他属性尽可能不同,而“羽毛图案”相同;
负样本:与其整体特征相似度高,其他属性尽可能相似,而“羽毛图案”不同;
正负样本对,需要与目标样本有公共的属性key(比如“羽毛图案”)
3.结果分析
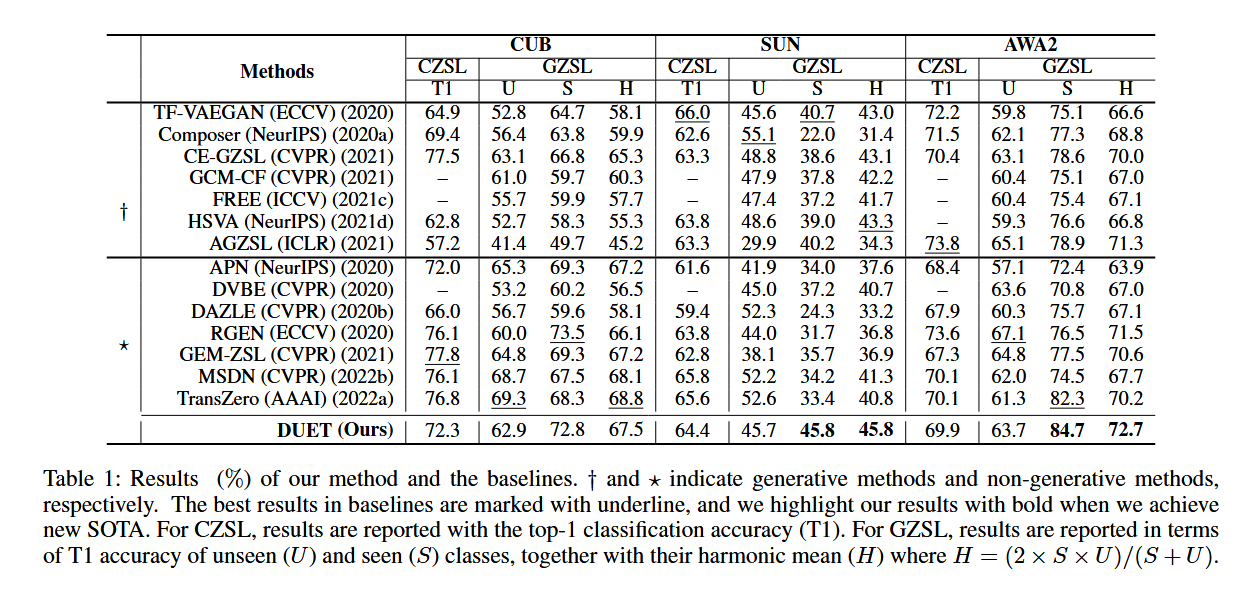
本文作为语言模型在零样本学习上的第一次尝试,在不同数据集上取得了优越甚至sota的效果。其中较为明显地看到,在 标准ZSL数据集(AWA2,CUB,SUN)上,相比于传统ResNet-based的方法,视觉预训练模型对于可见类的预测效果有明显提升(Seen class)。而在 K-ZSL数据集 上,模型也可以达到SOTA效果。此外,模型还获得了细粒度属性预测的附带能力,这是相比传统模型的额外优势。

VIT-based vision transformer encoder.
为了进一步了解论文中的模型,论文中报告了使用 ViT-base(Dosovitskiy 等人,2021)作为视觉编码器的 DUET 结果。对比于 2 个最近的基于 ViT 的 ZSL 方法,ViT-ZSL 和 IEAM-ZSL 。如图 4(b) 所示,DUET 大幅超越了这两种方法,并且也超过了论文中的 SOTA 性能 (H) 4.8%。这表明论文中的 DUET 极大地改善了原始vision transformer较差的 ZSL 能力。可以认为,通过插入更好的vision transformer encoder,性能将进一步提高。
消融研究
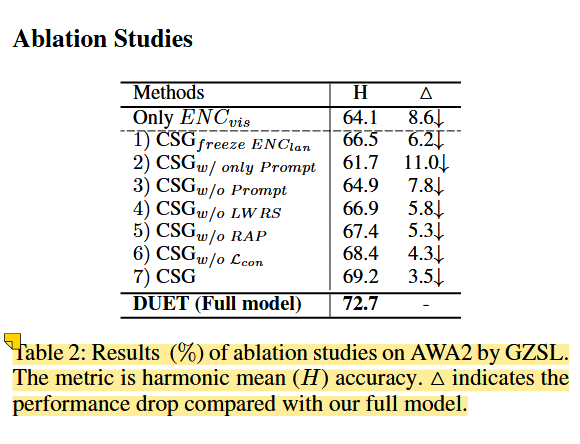
消融研究解释
(1) 冻结language transformer encoder时,性能急剧下降。虽然它可以减少整体可学习参数,但它使模型更难理解提示、文本属性和视觉特征之间的特殊关系。
(2)仅用prompt作为无提示的序列输入
(3)仅concatenating attribute作为无提示的序列输入
论文中观察到采用半序列化属性的 FST 策略确实有利于论文中的模型,提高了 4.3%。
(4)随机屏蔽属性
属性短语掩码(APM)。论文中应用 APM 策略在每个步骤中屏蔽完整的属性短语,然后敦促模型恢复它。论文中认为属性集合中频率较低的判别属性更重要。因此,论文中通过**线性加权随机采样(LWRS)**策略对要屏蔽的目标属性进行采样
(5)不进行属性剪枝
(6)放弃class-level对比学习导致下降0.8%。这一点是因为对比学习可以通过缩小潜在空间中类内的距离来帮助模型学习更好的视觉表示。
(7)应用完整的CSG
此外,论文中的可插拔 ACL 模块在 CSG 的基础上进一步将性能提高了3.5%,这说明这两个模块都是有益的。
属性级对比学习(ACL)模块
4.结论与启示
结论总结
在本文中,论文中提出了一种名为 DUET 的端到端 ZSL 框架,以解决零样本图像分类中众所周知的属性不平衡和共现问题。论文中设计了一种具有新颖的属性级对比学习机制的跨模态语义定位网络,以增强模型对新类的判别能力,可以很好地解决零样本学习中的属性不平衡和共现问题。通过广泛的消融研究以及在具有实值和二元值属性的四个 ZSL 基准上与相当多最先进的方法进行比较,论文中证明了 DUET 的有效性及其对解释的支持。
启发
PLMs的潜在语义知识引入
DUET通过整合PLMs中的潜在语义知识,采用自监督多模态学习,在ZSL任务上取得了卓越的性能。可以认为,利用PLMs的知识能够有效提高ZSL的性能。
多模态,跨模态整合
DUET引入了一个跨模态语义定位网络,用于分离图像中的语义属性。在ZSL中,理解图像中的语义属性可能是提高性能的关键因素。
文本+图像 信息整合
细粒度角度考虑
DUET采用了属性级对比学习策略,以进一步提高模型对细粒度视觉特征的区分能力,克服了属性不平衡和共现的问题。
类级别 —> 属性级别
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 变量和函数提升(js的问题)
- 利用阿里通义千问和Semantic Kernel,10分钟搭建大模型知识助手!
- 【书生·浦语】大模型实战营——第四课笔记
- mysqlbinlog查看binlog
- AutoCAD保存打开新建等操作变成命令行
- Go语言网络轮询器
- 从fuzz视角看CTF堆题--qwb2023_chatting
- Http---HTTP 请求报文
- Java基础语法(注释,关键字,字面量,变量,数据类型,标识符,键盘录入,IDEA安装,类,模块,项目)
- 低代码如何玩转面向对象的类继承