动态分区分配算法-第四十四天
目录
前言
????????动态分区分配算法:在动态分区分配方式中,当很多个空闲分区都能满足需求时,应该选择哪个分区进行分配?
首次适应算法(First Fit)
核心思想:每次从低地址开始查找,找到第一个满足大小地空闲分区
实现方法:空闲分区以地址递增地次序排列,每次分配内存时顺序查找空闲分区链或空闲分区表,找到大小能满足要求的第一个空闲分区,找到后就修改满足要求的分区的分区大小和起始地址等信息

最佳适应算法(Best Fit)
核心思想:为了保证“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片地空闲区,即优先使用更小地空闲区
实现方法:空闲分区按容量递增次序链接,每次分配内存时顺序查找空闲分区链或空闲分区表,找到大小能满足要求的第一个空闲分区,找到后就修改满足要求的分区的分区大小和起始地址等信息,同时还需要对空闲分区链和空闲分区表重新排序使其依旧按容量递增的次序链接,如果分出去后还是有序就不需要重新排序了

缺点:每次都选最小的分区进行分配,会留下越来越多的、很小的、难以利用的内存块,即很多的外部碎片
最坏适应算法(Worst Fit)
核心思想:为了解决最佳适应算法的问题(太多难以被利用的外部碎片),在每次分配时优先使用最大的连续空闲区,这样分配后剩余的空闲区就不会太小,更方便使用
实现方法:空闲分区按容量递减次序链接,每次分配内存时顺序查找空闲分区链或空闲分区表,找到大小能满足要求的第一个空闲分区,找到后就修改满足要求的分区的分区大小和起始地址等信息,同时还需要对空闲分区链和空闲分区表重新排序使其依旧按容量递减的次序链接,如果分出去后还是有序就不需要重新排序了

缺点:每次都选最大的分区进行分配,虽然可以让分配后留下的空闲区更大、更可用,但是这种方式会导致较大的连续空闲区被迅速用完,如果之后有"大进程"到达,就没有内存分区可用了
临近适应算法(Next Fit)
核心思想:首次适应算法每次都从链/表头开始查找,这可能会导致低地址出现很多很小的空闲分区,而每次分配查找时,都要经过这些分区,因此也增加了查找的开销,如果每次都从上次查找结束的位置开始检索,就能解决上述问题
实现方法:空闲分区以地址递增的顺序排列(可以排成一个循环链表),每次分配内存时从上次查找结束的位置开始查找空闲分区链或空闲分区表,找到大小能满足要求的第一个空闲分区
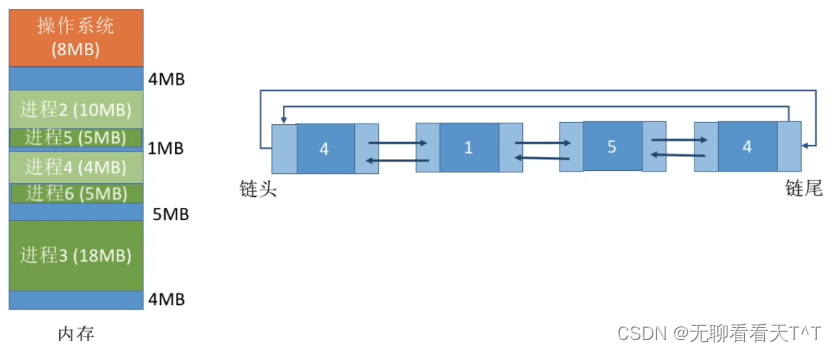
缺点:会使高地址的大分区也被用完
本节思维导图
| 算法 | 算法思想 | 分区排列顺序 | 优点 | 缺点 |
| 首次适应 | 从头到尾找适合的分区 | 空闲分区以地址递增次序排列 | 综合看性能最好,算法开销小,回收分区后一般不需要对空闲分区队列重排序 | |
| 最佳适应 | 优先使用更小的分区,以保留更多大分区 | 空闲分区以容量递增次序排列 | 会有更多的大分区被保留下来,更能满足大进程的需求 | 会产生很多太小的、难以利用的碎片;算法开销大,回收分区后可能需要对空闲分区队列重新排序 |
| 最坏适应 | 优先使用更大的分区,以防止产生太多小的不可用的碎片 | 空闲分区以地址递减次序排列 | 可以减少难以利用的小碎片 | 大分区容易被用完,不利于大进程;算法开销大(原因同上) |
| 临近适应 | 由首次适用算法演变而来,每次从上次查找结束位置开始查找 | 空闲分区以地址递增次序排列(可排列成循环链表) | 不用每次都从低地址的小分区开始检索。算法开销小(原因同首次适应算法) | 会使高地址的大分区也被用完 |
~over~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 写点东西《Docker入门(下)》
- flask不使用flask-login插件
- 数据分析硬核工具Origin各版本安装指南
- 深度解析Dubbo的可扩展机制SPI源码:从理论到实践,打造高效、稳定的分布式服务框架
- 【WPF.NET开发】克隆打印机
- Java线程池配置由繁至简,找到适合自己的天命线程池
- 安泰高压功率放大器在半导体测试中的应用
- 尚硅谷——第六章、面向对象(下)
- 自编C++题目——摇一摇
- Java 微服务框架 HP-SOA v1.0.6 发布 — 完整支持 Dubbo 和 Spring Cloud