数据库相关知识
1. 数据库三大范式
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。即不存在传递依赖。
主键和外键有什么区别?
- 主键(主码):主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
- 外键(外码):外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
2. SQL中的约束
1、NOT NULL: 约束字段的内容不能为空
2、UNIQUE:约束字段唯一性,一个表可以有多个Unique约束
3、PRIMARY KEY:主键约束,约束字段唯一,一个表只能有一个
4、FOREIGN KEY:外键约束,用于预防破坏表之间连接的动作,也能防止非法数据插入外键
5、CHECK:用于控制字段的值的范围。
3.?六种关联查询
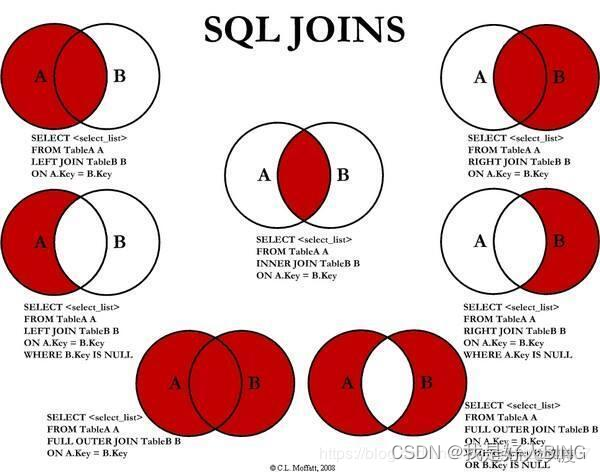
A)内连接:join,inner join
B)外连接:left join,left outer join,right join,right outer join,union(重复的记录会合并)
full join (mysql不支持,但是可以用 left join union right join代替)
C)交叉连接:cross join 想得到A,B记录的排列组合,即笛卡儿积
UNION 和 UNION ALL 的区别
Union:对两个结果进行并集操作,不包括重复行,同时会进行默认规则的排序。
Union All:对两个结果集进行并集操作,包括重复行,不进行排序。
Union 的效率高于 Union All。
4. Delete/Drop/Truncate区别
用法不同
drop(丢弃数据):drop table 表名,直接将表都删除掉,在删除表的时候使用。truncate(清空数据) :truncate table 表名,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。delete(删除数据) :delete from 表名 where 列名=值,删除某一行的数据,如果不加where子句和truncate table 表名作用类似。
truncate 和不带 where子句的 delete、以及 drop 都会删除表内的数据,但是 truncate 和 delete 只删除数据不删除表的结构(定义),执行 drop 语句,此表的结构也会删除,也就是执行drop 之后对应的表不复存在。
属于不同的数据库语言
truncate 和 drop 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 delete 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segment 中,事务提交之后才生效。
DML 语句和 DDL 语句区别:
- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。
- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
另外,由于select不会对表进行破坏,所以有的地方也会把select单独区分开叫做数据库查询语言 DQL(Data Query Language)。
执行速度不同
一般来说:drop > truncate > delete(这个我没有实际测试过)。
delete命令执行的时候会产生数据库的binlog日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。truncate命令执行的时候不会产生数据库日志,因此比delete要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。drop命令会把表占用的空间全部释放掉。
Tips:你应该更多地关注在使用场景上,而不是执行效率。
5. Count(*),Count(1),Count(列名)的区别
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了忽略所有列,用1代表代码行,相当于表中有多少个1,当然也可以设置成2、3.。在统计结果的时候,不会忽略列值为NULL,本质上和count(星)一样。
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率:
- 列名为主键, count(列名) 会比 count(1)快
- 列名不为主键, count(1) 会比 count(列名)快
- 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
- 如果有主键,则 select count(主键) 的执行效率是最优的
- 如果表只有一个字段,则 select count(*)最优。
6. SQL查询语句的优化
可以分为两部分,对语句的优化、对索引的优化
对于语句的优化
1、检查是否请求的不需要的数据,select * 的时候会把所有的列都查询出来;
2、语句重构,拆分复杂查询成多个查询,或者改写子查询成为关联表查询
3、优化count(),count (*) 如果只是需要判断结果的数量,可以改成count(1)
4、优化关联查询:确保on/where语句的列上有索引
5、优化limit语句,当limit offset中的offset值很大时,查询性能会直线下降
7. SQL的生命周期
1. 应用服务器与数据库服务器建立连接
2. 数据库进程拿到请求sql
3. 解析并生成执行计划,并执行
4. 读取数据到内存进行逻辑处理
5. 通过步骤一的连接,发送结果到客户端
6. 关闭连接,释放资源
8. 数据库的设计原则
1)一致性原则:对数据来源进行统一、系统的分析与设计,协调好各种数据源,保证数据的一致性和有效性。
2)完整性原则:数据库的完整性是指数据的正确性和相容性。要防止合法用户使用数据库时向数据库加入不合语义的数据。对输入到数据库中的数据要有审核和约束机制。
3)安全性原则:数据库的安全性是指保护数据,防止非法用户使用数据库或合法用户非法使用数据库造成数据泄露、更改或破坏。要有认证和授权机制。
4)可伸缩性与可扩展性原则:数据库结构的设计应充分考虑发展的需要、移植的需要,具有良好的扩展性、伸缩性和适度冗余。
5)规范化:数据库的设计应遵循规范化理论。规范化的数据库设计,可以减少数据库插入、删除、修改等操作时的异常和错误,降低数据冗余度等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!