【DeepLabv3+】训练自己的数据集(小白版)
代码来源于代码
本地训练,设备3050
一、数据集准备
1.数据集创建
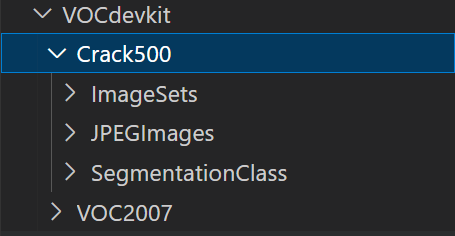
在原始的根目录VOCdevkit下创建数据集Crack500文件夹,下面再创建三个文件夹。
ImageSets下创建文件夹,命名为Segmentation。里面存放生成的txt文件
JPEGImages 放原始的图片
SegmentationClass 放原始图片对应的mask图片的png格式
2.数据集的处理
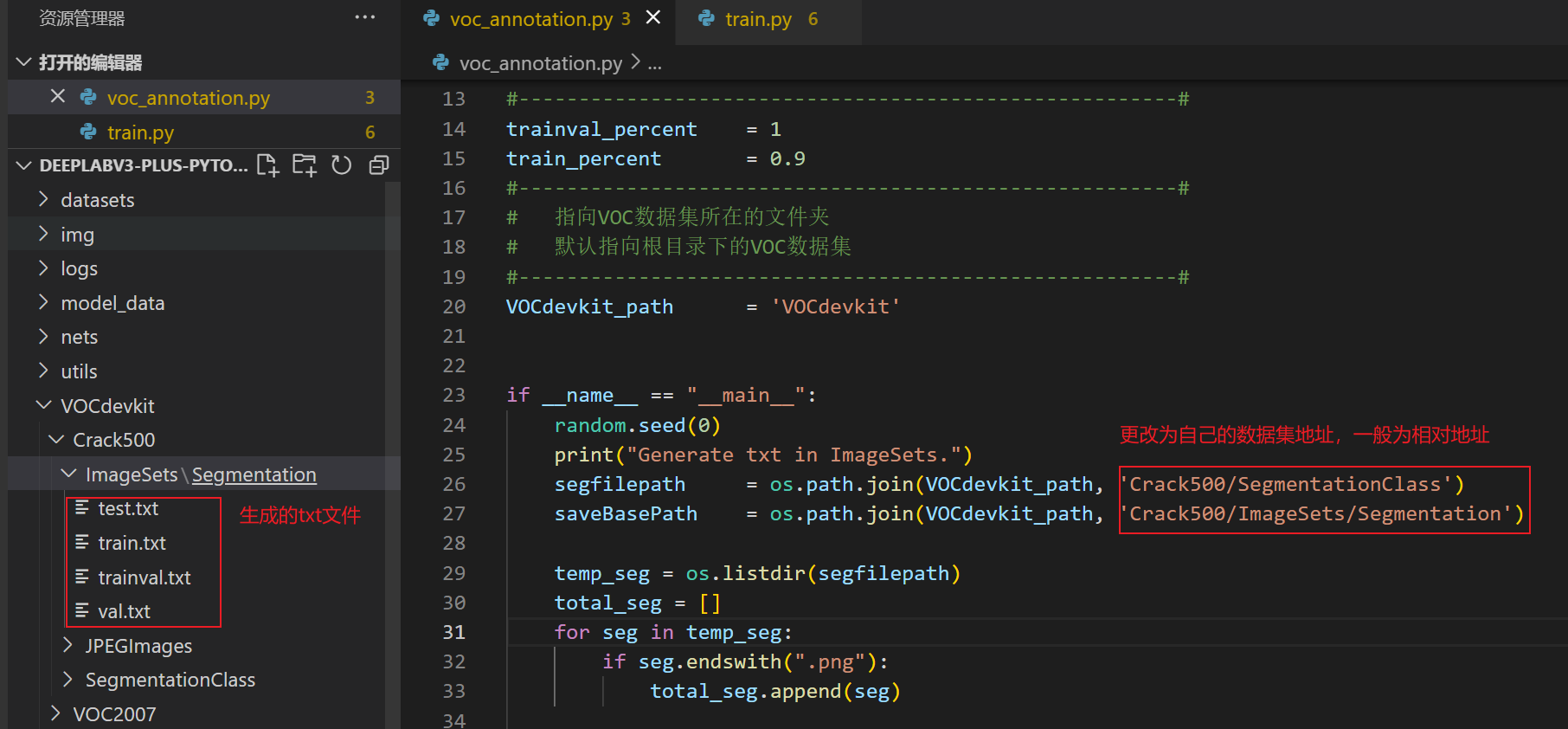
需要用到根目录下的voc_annotation.py,目的是获得训练用的train.txt以及val.txt。(自己的数据集需要进行这一步操作)
改为自己的数据集路径,一般为相对地址。
二、训练
1.改参数
在train.py文件中
主要修改:
num_classes
backbone
model_path
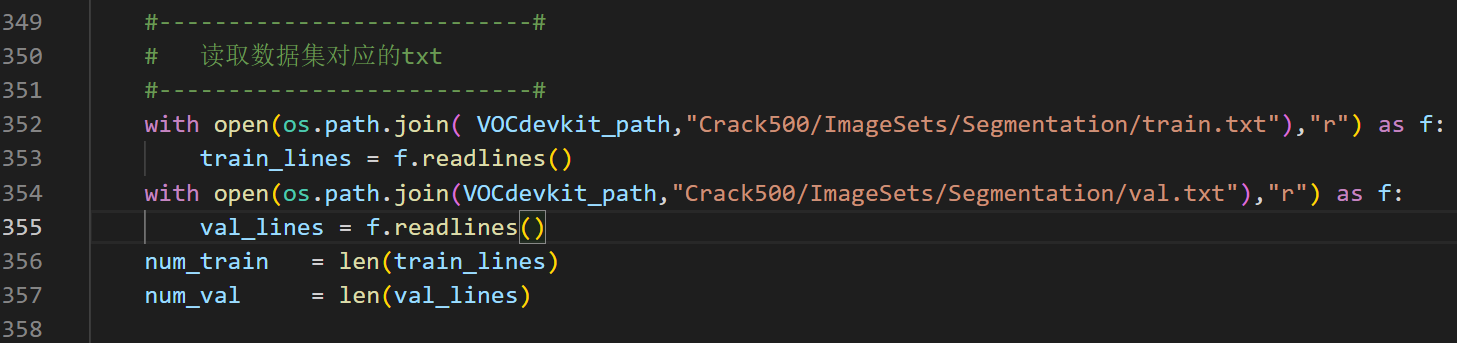
txt文件路径

这里是在VOCdevkit下新建的一个数据集Crack500,需要修改txt文件地址
同理,根目录下的utils>dataloader.py下的读取图像的路径也需要修改

2.运行train.py
3.结果存放在根目录下的logs文件夹下
4.运行get_miou.py
运行之前需要去deeplab.py里修改model_path、num_classes和backbone,
刚才运行好的pth文件在log里存放。
三、预测
训练结果预测需要用到两个文件,分别是deeplab.py和predict.py。
需要去deeplab.py里面修改model_path以及num_classes,这两个参数必须要修改。
model_path指向训练好的权值文件,在logs文件夹里。
num_classes指向检测类别的个数+1。
单张图片检测时,可以在predict.py里修改参数"mode=dir_predict"
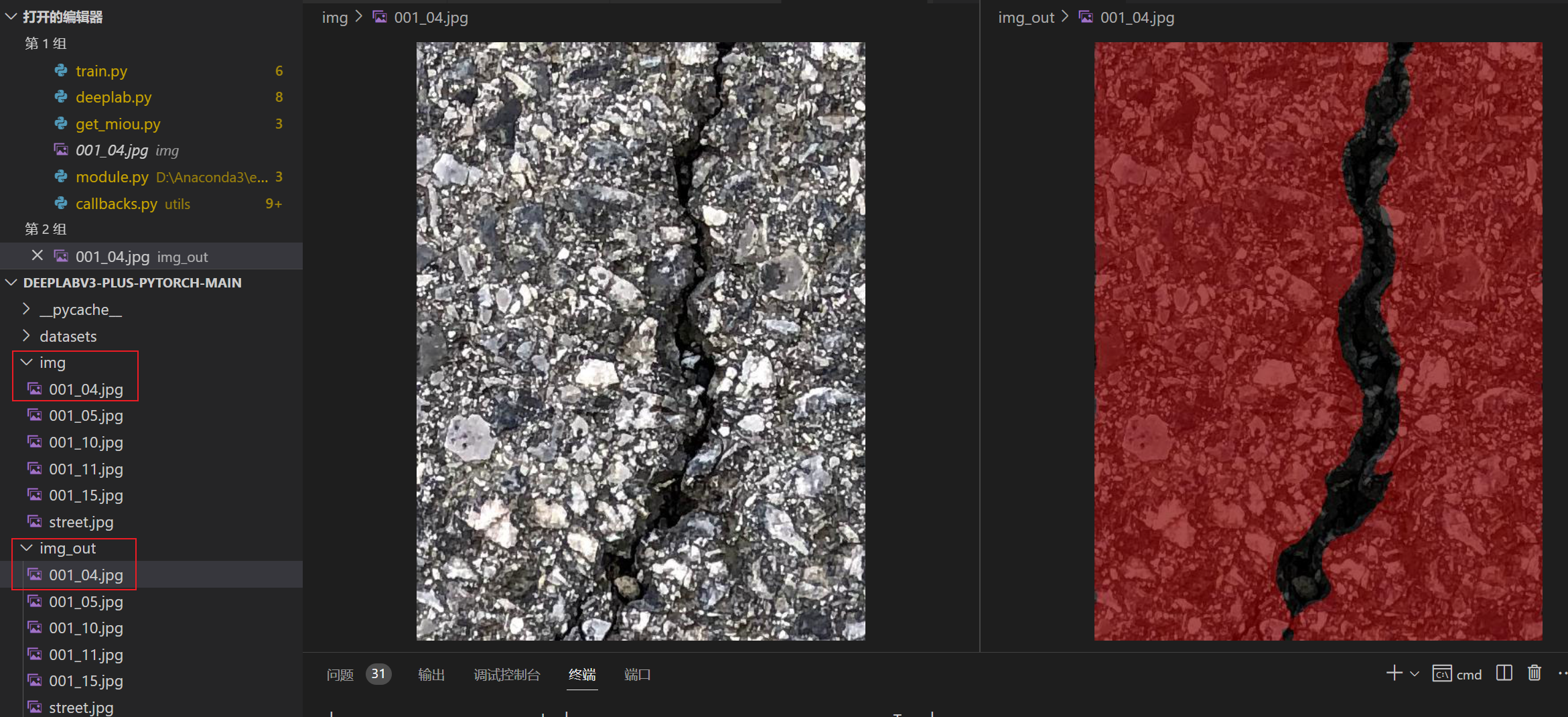
原始图像放在img里,检测的图片放在img_out里,如下图所示。
可能遇到的报错
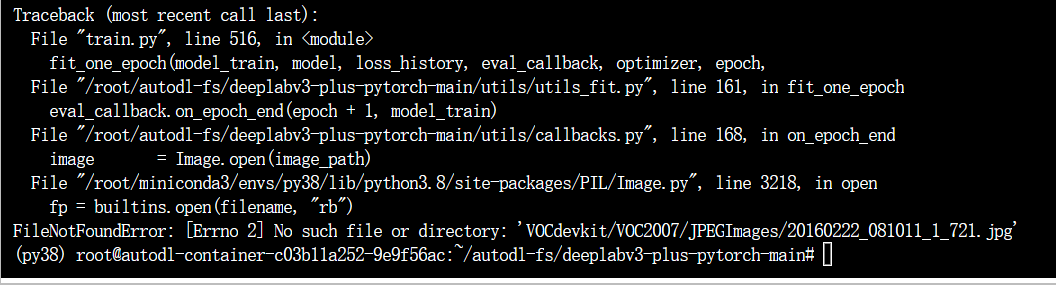
解决办法:
utils>callbacks.py下
参考文献:deeplabv3+
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 好玩!腾讯开源 PhotoMaker:高效地定制化生成任意风格的逼真人类照片!
- GPT 如何不挂VPN使用
- Kafka - Topic 消费状态常用命令
- C# vs报错 id为XX的进程当前未运行
- 在 CentOS 7.4 上使用 Docker极速部署 LNMP (Linux, Nginx, MySQL, PHP) 环境和 WordPress
- JavaScript系列-循环语句
- WinSCP显示服务器隐藏的文件
- Spring MVC 拦截器
- GPT 魔力涌现
- TiDB中Table映射到KV