羊驼系列大模型LLaMa、Alpaca、Vicuna
发布时间:2024年01月20日
羊驼系列大模型:大模型的安卓系统
GPT系列:类比ios系统,不开源
LLaMa让大模型平民化
LLaMa优势
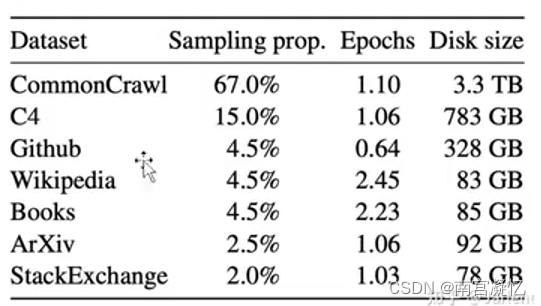
 用到的数据:大部分英语、西班牙语,少中文
用到的数据:大部分英语、西班牙语,少中文
模型下载地址
https://huggingface.co/meta-llama

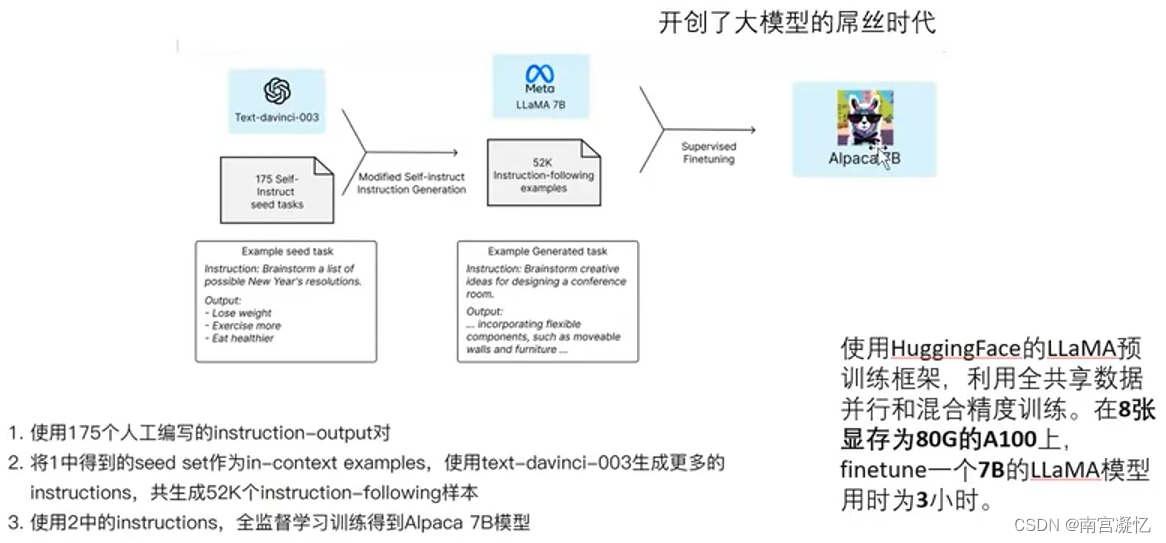
Alpaca模型
Alpaca是斯坦福从Meta的LLaMA 7B微调而来的全新模型 (套壳)仅用了52k数据,性能约等于GPT-3.5。
训练成本奇低,总成本不到600美元
- 在8个80GB A100上训练了3个小时,不到100美元;
- 生成数据使用OpenAl的AP1,500美元。(数据标注: 问题问chatgpt,用它的回答作为标注数据)
Alpaca模型的训练
Vicuna模型
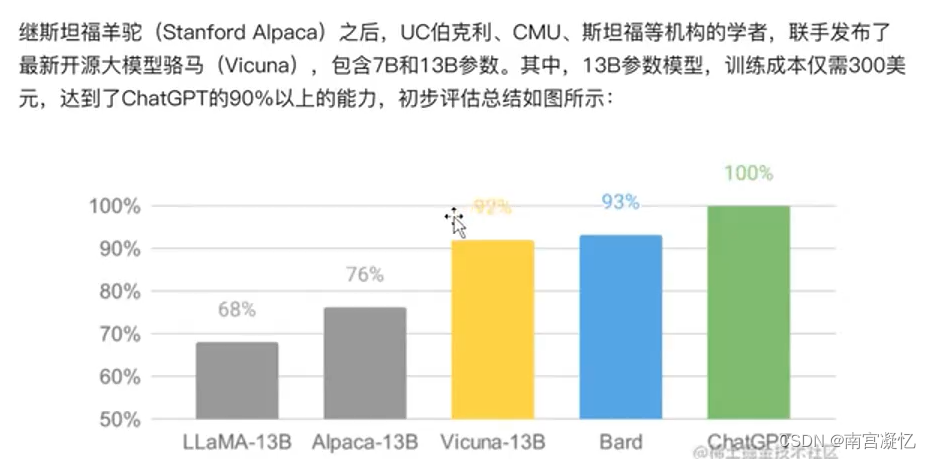
Vicuna简介
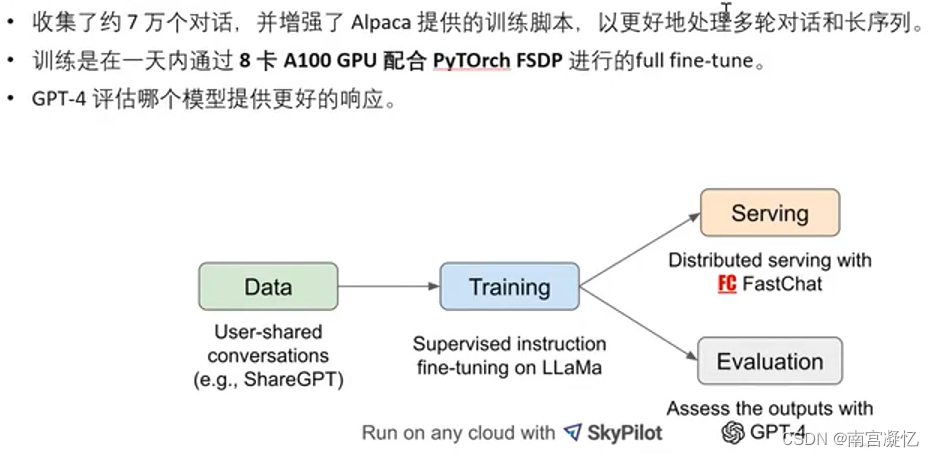
具体工作流程
用GPT4做评估,用更厉害的大模型做大模型
ChatGPT没找到合适的盈利模式
诸驼对比
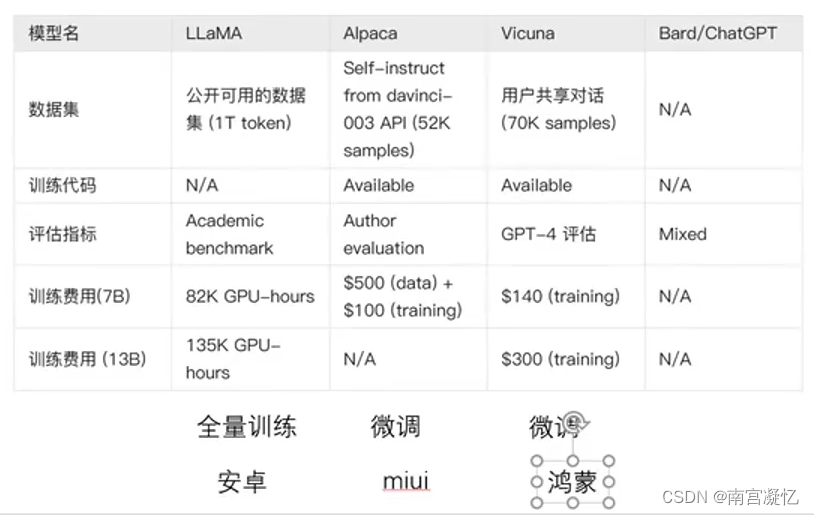
华驼模型

百川大模型
LLaMa+中文数据
LLaMa2.0

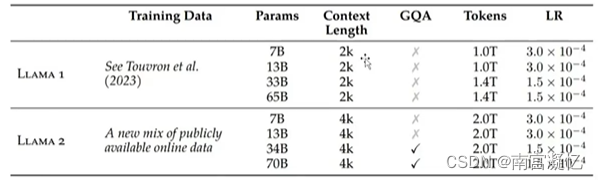
具备人的情商
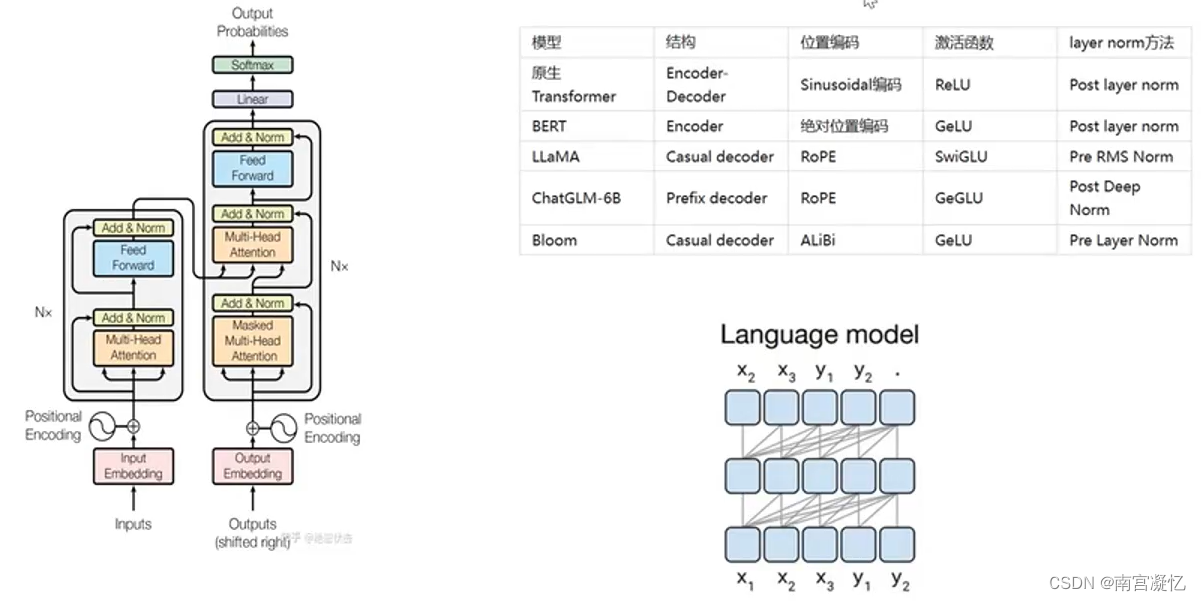
国内大模型清华6B(中英文数据各一半)、百度文心一言是原创,其它的套壳。
找大模型工作不要找研究型工作,而要找将大模型落地的工作。
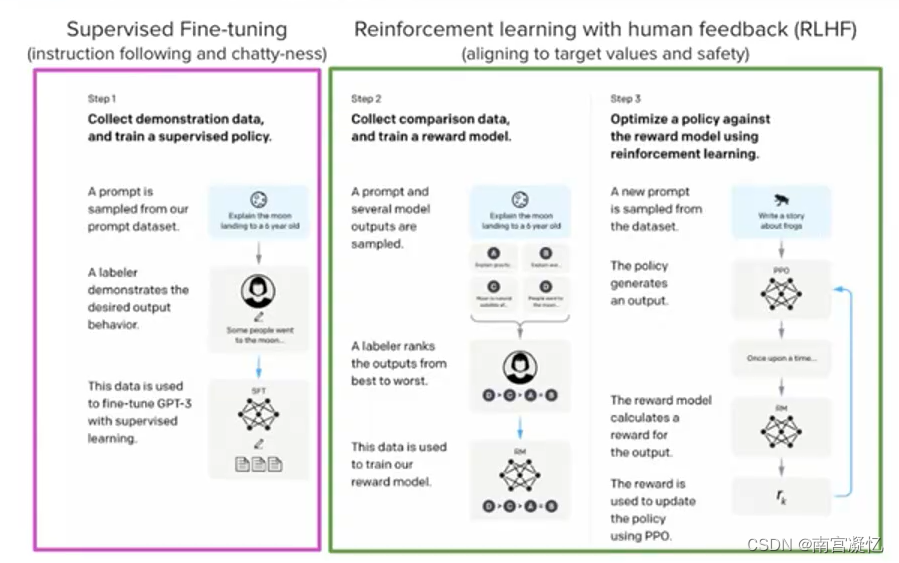
微调的本质
- 原生llama用的通用语料
- 在自己的数据上进行微调,让模型能够满足自己的需求
羊驼系列的共性
文章来源:https://blog.csdn.net/weixin_43409127/article/details/135716258
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 某联webpack解析(js逆向)
- C Primer Plus(第六版编程练习)8.11 编程练习 第5题
- JS 将字符串‘10.3%‘ 经过运算加2转换为 ‘12.3%‘
- MATLAB - 使用 MPC Designer 线性化 Simulink 模型
- 2024 年 最全的 21 款顶级数据恢复软件工具榜单
- 计算机毕业设计 基于Java的美食信息推荐系统的设计与实现 Java实战项目 附源码+文档+视频讲解
- SpringCloud GateWay实现路由限流
- 【Web实操11】定位实操_照片墙(无序摆放)
- 华为HarmonyOS 开发工具DevEco 中文插件 汉化
- 深入理解计算机硬件存储体系结构