4. ID 策略
在创建表的时候我故意没有设置主键的增长策略,现在我们来插入一条数据,看看主键是如何增长的:
@Test
void contextLoads() {
Employee employee = new Employee();
employee.setLastName("lisa");
employee.setEmail("lisa@qq.com");
employee.setAge(20);
employeeService.save(employee);
}
插入成功后查询一下数据表:
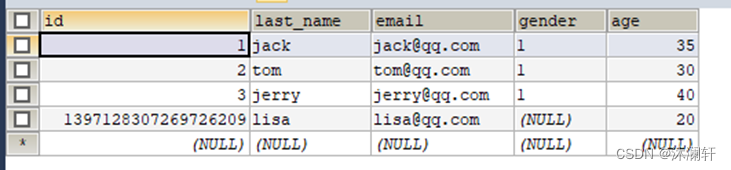
可以看到 id 是一串相当长的数字,这是什么意思呢?提前剧透一下,这其实是分布式 id,那又何为分布式 id 呢?
对于一个大型应用,其访问量是非常巨大的,就比如说一个网站每天都有人进行注册,注册的用户信息就需要存入数据表,随着日子一天天过去,数据表中的用户越来越多,此时数据库的查询速度就会受到影响,所以一般情况下,当数据量足够庞大时,数据都会做分库分表的处理。
然而,一旦分表,问题就产生了,很显然这些分表的数据都是属于同一张表的数据,只是因为数据量过大而分成若干张表,那么这几张表的主键 id 该怎么管理呢?每张表维护自己的 id?那数据将会有很多的 id 重复,这当然是不被允许的,其实,我们可以使用算法来生成一个绝对不会重复的 id,这样问题就迎刃而解了,事实上,分布式 id 的解决方案有很多:
- UUID
- SnowFlake
- TinyID
- Uidgenerator
- Leaf
- Tinyid
以 UUID 为例,它生成的是一串由数字和字母组成的字符串,显然并不适合作为数据表的 id,而且 id 保持递增有序会加快表的查询效率,基于此,MyBatisPlus 使用的就是 SnowFlake(雪花算法)。
Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
- 第 0 位: 符号位(标识正负),始终为 0,没有用,不用管。
- 第 1~41 位 :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
- 第 42~52 位 :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
- 第 53~64 位 :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
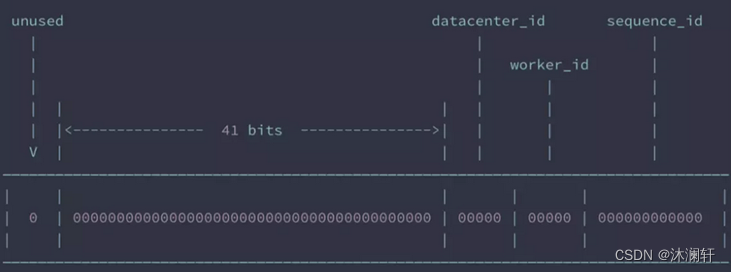
这也就是为什么插入数据后新的数据 id 是一长串数字的原因了,我们可以在实体类中使用 @TableId 来设置主键的策略:
@Data
@TableName("tbl_employee")
public class Employee {
@TableId(type = IdType.AUTO) // 设置主键策略
private Long id;
private String lastName;
private String email;
private Integer age;
}
MyBatisPlus 提供了几种主键的策略:
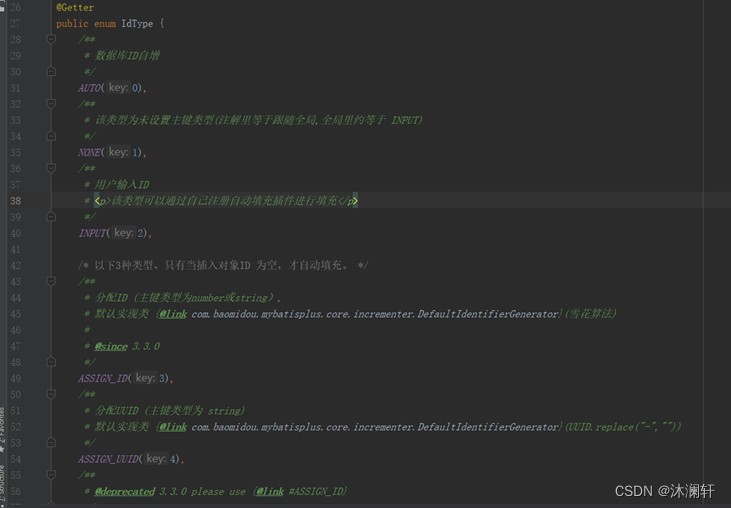
- AUTO 表示数据库自增策略,该策略下需要数据库实现主键的自增(auto_increment),
- ASSIGN_ID 是雪花算法,默认使用的是该策略,ASSIGN_UUID 是 UUID 策略,一般不会使用该策略。
当实体类的主键名为 id,并且数据表的主键名也为 id 时,此时 MyBatisPlus 会自动判定该属性为主键 id,倘若名字不是 id 时,就需要标注 @TableId 注解,若是实体类中主键名与数据表的主键名不一致,则可以进行声明:
@TableId(value = "uid",type = IdType.AUTO) // 设置主键策略
private Long id;
还可以在配置文件中配置全局的主键策略:
mybatis-plus:
global-config:
db-config:
id-type: auto
这样能够避免在每个实体类中重复设置主键策略。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 写一个linux下的进程守护脚本
- Spring Cloud 系列:Seata 中TCC模式具体实现
- 简单二分查找(C++算法)
- 案例090:基于微信小程序的体育资讯系统设计与实现
- ARM CCA机密计算硬件架构之内存管理
- pytorch 分布式训练
- 设计模式——责任链模式(行为模式)
- workflow系列教程(4)Parallel并联任务流
- 优化用户体验测试应用领域:提升产品质量与用户满意度
- 基于java的电子服务网站系统设计与实现