【sklearn练习】datasets的使用
发布时间:2024年01月08日
一、数据集分类
1、fetch类的数据集:
以 "fetch" 开头的数据集,这些数据集通常不包含在 scikit-learn 的标准安装中,需要从远程服务器上下载。这些数据集通常比标准数据集更大,因此在使用它们之前,需要通过网络下载它们。
示例(1)
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces()
2、load类的数据集:
"load" 开头的数据集是一些较小且包含在 scikit-learn 标准安装中的示例数据集。这些数据集不需要从远程服务器下载,因为它们已经包含在 scikit-learn 的安装包中。
示例(1)

3、make类的数据集:
"load" 开头的数据集是一些较小且包含在 scikit-learn 标准安装中的示例数据集。这些数据集不需要从远程服务器下载,因为它们已经包含在 scikit-learn 的安装包中。
示例(1)
from sklearn.datasets import make_regression
import matplotlib.pyplot as plt
X, y = make_regression(n_samples=100, n_features=1, noise=0.1)
plt.scatter(X, y)
plt.show()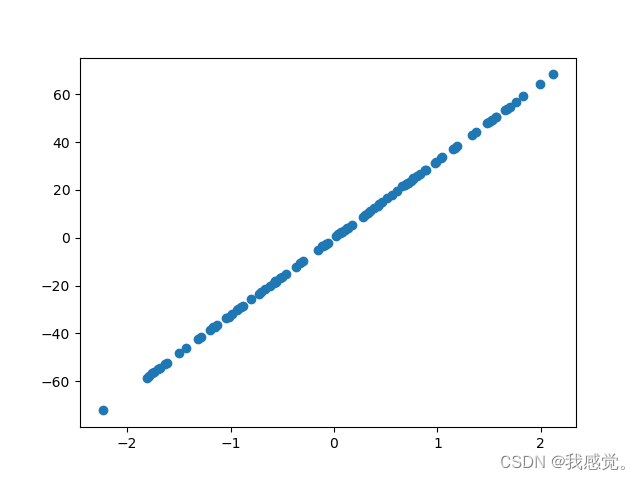
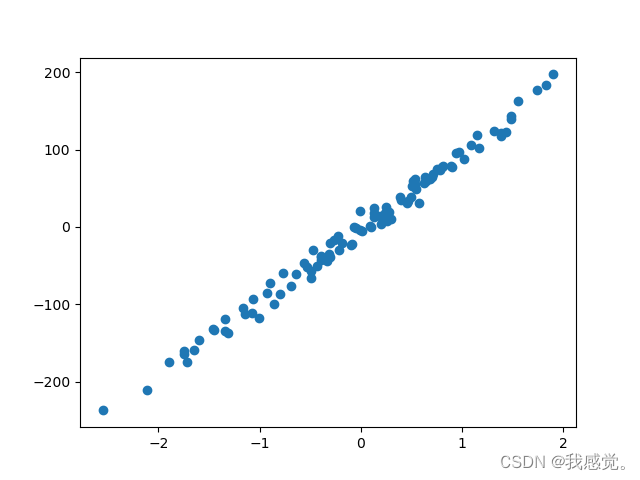
下面图是把noise改为10的图像:
文章来源:https://blog.csdn.net/m0_56997192/article/details/135447581
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 十种编程语言的对比分析
- 开源项目CuteSqlite开发笔记(七):CuteSqlite释放BETA版本啦
- C++折半插入排序详解以及代码实现
- [EFI]HP Spectre 13 v102nl电脑 Hackintosh 黑苹果efi引导文件
- RS0108YQ20 双向电压平转换器 润石 24Mbps 5.5V
- Diss一下ApiPost国产软件
- Win10 如何用powershell写个WOL开机脚本
- 免费在线数据库表结构设计工具itbuilder
- 光伏电站整体解决方案:光伏开发、设计和施工一体化
- dctcp 可扩展、低时延图解