【MySQL故障】主从延迟越来越大
问题背景
研发执行了一个批量更新数据的操作,操作的表是个宽表,大概有90多个字段,数据量有800多w,但是研发是根据ID按行更新。更新开始后,该集群的主从延迟越来越大。
问题现象?
1 从库应用binlog基本无落后,sql_thread 无落后。
2 从库落后主库很多个binlog
3 从库的io_thread一直处于?Queueing master event to the relay log 状态
4 Seconds_Behind_Master数值越来越大
问题分析
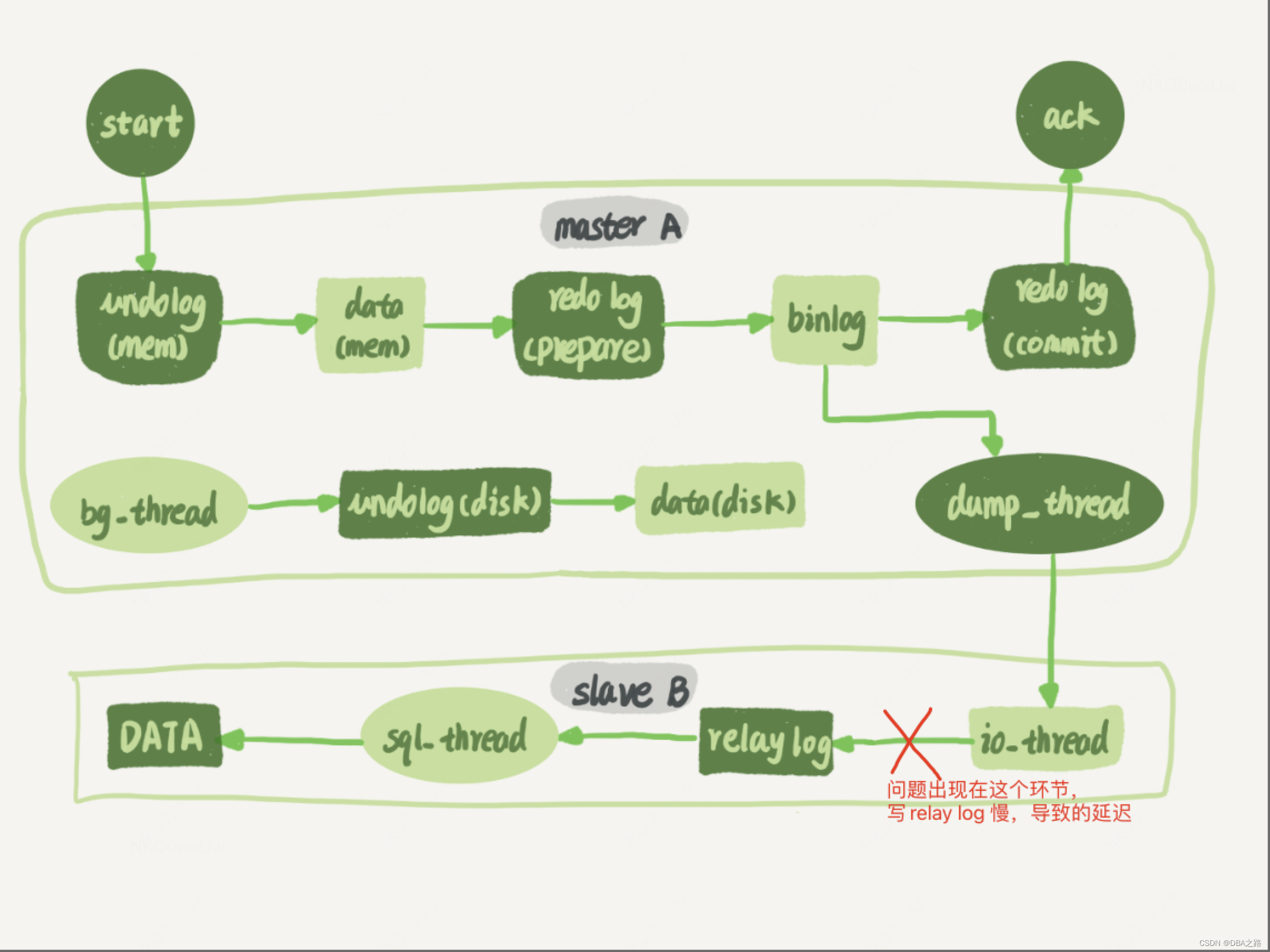
出现主从延迟后,首先分析是io_thread(拉取日志然后写中继日志) 还是 sql_thread(应用中级日志)。
另外需要明确 Seconds_Behind_Master是从库本地时间 - 主库binlog event的时间
sql_thread延迟的原因大概有
- 大事务 ,执行时间长
- DDL,执行时间长
- 元数据锁,主库完成变更后,在从库上应用的时候,从库刚好有个该表的长查询。造成该表所有的更新都被堵塞等待元数据锁
- 延迟从库,
- 并行复制,有无开启,并发度等
- 表上无主键
- 从库上备份,一般备份工具在备份非InnoDB 存储引擎的时候都会执行FTWRL
io_thread延迟的原因大概有
- 网络问题,网卡流量大,造成的网络拥塞
- 磁盘IO瓶颈
排查过程
首先确认落后是在 IO_thread(拉取binlog日志) 还是在 SQL_thread(应用binlog日志)
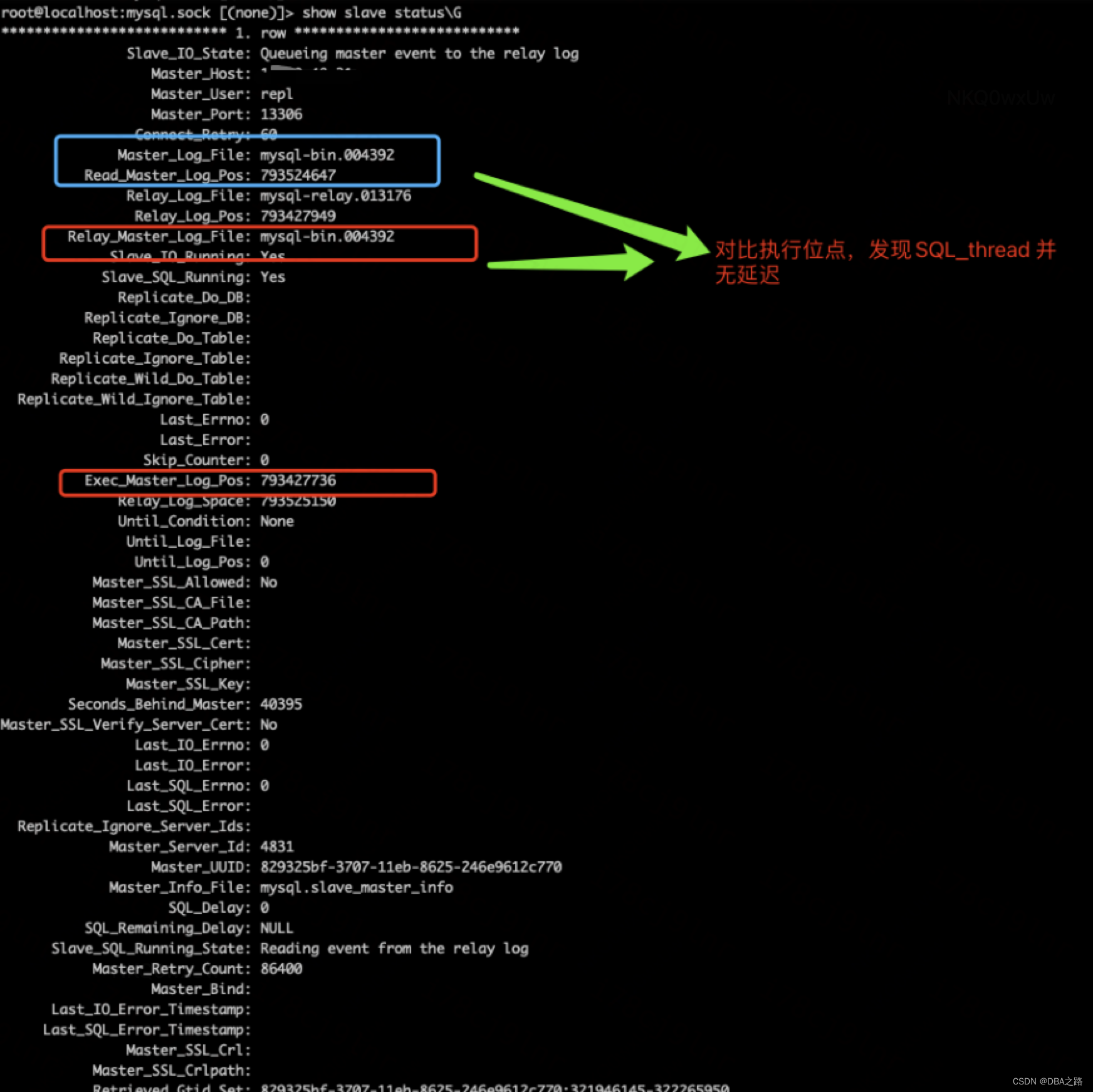
对比执行的文件和位点
Master_Log_File 与 Read_Master_Log_Pos (读取到的主库的binlog文件和位点)
Relay_Master_Log_File 与 Exec_Master_Log_Pos(sql_thread 应用的relay_log对应主库文件和位点)
发现文件编号基本一直,位点也相差无几,说明sql_thread 并无落后
再次确认,查看主库上有无大事务,DDL, 从库上有无长查询阻塞DDL,从库上备份等。该表有无主键,逐个排查并没有发现以上问题。
查看主库的此刻binlog 编号 与 从库获取到的标号,发现落后很多。
应该是IO_thread 拉取? 然后 转写为 relay_log 的过程比较慢,这个过程主要设计到网络 和 磁盘IO的问题

在从库上查看会话 ,有个会话一直处于 Queueing master event to the relay log,查看官方文档 ,
The thread has read an event and is copying it to the relay log so that the SQL thread can process it. 该线程读取binlog中的 event 然后复制为中继日志,以便sql thread 可以应用这些event.
从官方文档中可以看到 该会话一直在将主库的event 写成从库的relay log

在服务器上通过IOTOP 命令查看磁盘IO状况
发现有个线程IOwait 一直很高 ,保持在70% 到 80%

通过查询 服务器上该线程ID 刚好 对应 数据库中写relay log的会话id.

此刻基本定位到是写relay 很慢,应该是和该表是宽表,
修改relay log的落盘参数,sync_relay_log 原来设置的是1 ,该大一些
set global sync_relay_log=100000;

总结?
参考:
类似问题:
https://www.cnblogs.com/zping/p/10861902.html
主从延迟原因
https://www.cnblogs.com/ivictor/p/17331981.html
官方文档??I/O Thread States
MySQL :: MySQL 5.7 Reference Manual :: 8.14.6 Replication Replica I/O Thread States
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【分享&备忘录】Postgresql/pgsql 根据规则,批量联级删除多张表
- Python 爬虫 小案例 之 快手下载视频
- Pandas.Series.idxmin() 最小值索引 详解 含代码 含测试数据集 随Pandas版本持续更新
- 鸿道(Intewell)工业操作系统推动新型工业化时代下的产教融合
- HiveSql语法优化二 :join算法
- Elastic Search的RestFul API入门:alias别名
- 如何有效构建进攻性的网络安全防护策略
- 华清远见作业第二十五天——IO(第八天)
- fs-extra 文件操作的常用API
- 基于ssm vue的风景文化管理平台源码和论文