CFINet模型调试记录
CFINet是基于MMDetection框架开发的一款由粗略到精细的两阶段目标检测算法,该算法是在Faster-RCNN模型基础上实现的,下面开始其调试过程。
实验环境
尽量使用GPU运行,CPU运行会出现很多莫名其妙的错误。
硬件环境
CPU:i7-13700h,GPU:4060 8G,内存16G
软件环境
博主使用的是python3.7,其中MMDetection的某些包安装较为繁琐,具体可以参照博主这篇博客:
MMDetection环境配置
对于该模型,使用的具体环境依赖如下:
addict=2.4.0=pypi_0
appdirs=1.4.4=pypi_0
blas=1.0=mkl
brotli-python=1.0.9=py37hf2a7229_7
ca-certificates=2023.7.22=h56e8100_0
certifi=2023.7.22=pyhd8ed1ab_0
charset-normalizer=3.3.2=pyhd8ed1ab_0
cityscapesscripts=2.2.2=pypi_0
colorama=0.4.6=pypi_0
coloredlogs=15.0.1=pypi_0
cudatoolkit=11.6.0=hc0ea762_10
cycler=0.11.0=pypi_0
dataclasses=0.6=pypi_0
fairscale=0.4.6=pypi_0
filelock=3.12.2=pypi_0
fonttools=4.38.0=pypi_0
freetype=2.12.1=ha860e81_0
fsspec=2023.1.0=pypi_0
future=0.18.3=pypi_0
giflib=5.2.1=h8cc25b3_3
huggingface-hub=0.16.4=pypi_0
humanfriendly=10.0=pypi_0
idna=3.4=pyhd8ed1ab_0
imagecorruptions=1.1.2=pypi_0
imageio=2.31.2=pypi_0
importlib-metadata=6.7.0=pypi_0
intel-openmp=2021.4.0=haa95532_3556
joblib=1.3.2=pypi_0
jpeg=9e=h2bbff1b_1
kiwisolver=1.4.5=pypi_0
lerc=3.0=hd77b12b_0
libdeflate=1.17=h2bbff1b_1
libpng=1.6.39=h8cc25b3_0
libtiff=4.5.1=hd77b12b_0
libuv=1.44.2=h2bbff1b_0
libwebp=1.3.2=hbc33d0d_0
libwebp-base=1.3.2=h2bbff1b_0
lz4-c=1.9.4=h2bbff1b_0
markdown-it-py=2.2.0=pypi_0
matplotlib=3.5.3=pypi_0
mdurl=0.1.2=pypi_0
mkl=2021.4.0=haa95532_640
mkl-service=2.4.0=py37h2bbff1b_0
mkl_fft=1.3.1=py37h277e83a_0
mkl_random=1.2.2=py37hf11a4ad_0
mmcv=2.0.0rc3=pypi_0
mmcv-full=1.7.1=pypi_0
mmdet=2.26.0=dev_0
mmengine=0.9.0=pypi_0
networkx=2.6.3=pypi_0
ninja=1.10.2=haa95532_5
ninja-base=1.10.2=h6d14046_5
numpy=1.21.5=py37h7a0a035_3
numpy-base=1.21.5=py37hca35cd5_3
opencv-python=4.5.3.56=pypi_0
openssl=1.1.1w=h2bbff1b_0
packaging=23.2=pypi_0
pillow=9.5.0=pypi_0
pip=23.3.1=pypi_0
platformdirs=3.11.0=pypi_0
pycocotools=2.0.7=pypi_0
pygments=2.16.1=pypi_0
pyparsing=3.1.1=pypi_0
pyquaternion=0.9.9=pypi_0
pyreadline=2.1=pypi_0
pysocks=1.7.1=py37h03978a9_5
python=3.7.16=h6244533_0
python-dateutil=2.8.2=pypi_0
python_abi=3.7=2_cp37m
pytorch=1.12.0=py3.7_cuda11.6_cudnn8_0
pytorch-mutex=1.0=cuda
pywavelets=1.3.0=pypi_0
pyyaml=6.0.1=pypi_0
regex=2023.10.3=pypi_0
requests=2.31.0=pyhd8ed1ab_0
rich=13.6.0=pypi_0
safetensors=0.4.1=pypi_0
scikit-image=0.19.3=pypi_0
scikit-learn=1.0.2=pypi_0
scipy=1.7.3=pypi_0
setuptools=65.6.3=py37haa95532_0
shapely=2.0.2=pypi_0
six=1.16.0=pyhd3eb1b0_1
some-package=0.1=pypi_0
sqlite=3.41.2=h2bbff1b_0
termcolor=2.3.0=pypi_0
terminaltables=3.1.10=pypi_0
threadpoolctl=3.1.0=pypi_0
tifffile=2021.11.2=pypi_0
timm=0.9.12=pypi_0
tk=8.6.12=h2bbff1b_0
tomli=2.0.1=pypi_0
torchaudio=0.12.0=py37_cu116
torchvision=0.13.0=py37_cu116
tqdm=4.66.1=pypi_0
typing=3.7.4.3=pypi_0
typing_extensions=4.7.1=pyha770c72_0
urllib3=2.0.7=pyhd8ed1ab_0
vc=14.2=h21ff451_1
vs2015_runtime=14.27.29016=h5e58377_2
wheel=0.38.4=py37haa95532_0
win_inet_pton=1.1.0=pyhd8ed1ab_6
wincertstore=0.2=py37haa95532_2
xz=5.4.2=h8cc25b3_0
yapf=0.40.2=pypi_0
zipp=3.15.0=pypi_0
zlib=1.2.13=h8cc25b3_0
zstd=1.5.5=hd43e919_0
安装完环境后,需要执行相应的配置,首先下载CFINet的源代码,如果已经下载则无需再执行,随后需要执行set_up.py文件,将目录切换到CFINet目录下
git clone https://github.com/shaunyuan22/CFINet
cd CFINet
pip install -v -e .
如下图所示:

数据集下载
随后需要下载数据集,官方给出了两个数据集,分别是SODA-A与SODA-D,我们使用后一个,其中下载连接为:SODA-D下载链接
数据集预处理
下载完成数据集后,我们发现该数据集的标注格式为JSON文件,与COCO数据集相同,但不同的是,该数据集还需做进一步处理,称为切分化。
具体是执行tools/img_split.py文件。首先需要修改里面的一些配置信息,如下:
parser.add_argument('--cfgJson', default="./split_configs/split_train.json",help='config json for split images')#切分配置文件
parser.add_argument('--mode', type=str, default='val')#要切分的数据集
配置文件如下:
{
"nproc": 10,
"mode": "val",
"oriImgDir": "E:/datasets/SODAD/DivData/Images",
"oriAnnDir": "E:/datasets/SODAD/Annotations/",
"patchH": 800,
"patchW": 800,
"stepSzH": 150,
"stepSzW": 150,
"padVal": [
0, 0, 0
],
"ignFillVal": [
0, 0, 0
],
"interAreaIgnThr": 0.40,
"splDir": "E:/datasets/SODAD/SODAD/"
}
一定要通过该文件对数据集做预处理,否则就会报错,一定要预处理,先前博主脑子抽了没有预处理,导致出现了很多错误,如:
stack expects each tensor to be equal size, but got XXX at entry X and YYY at entry Y
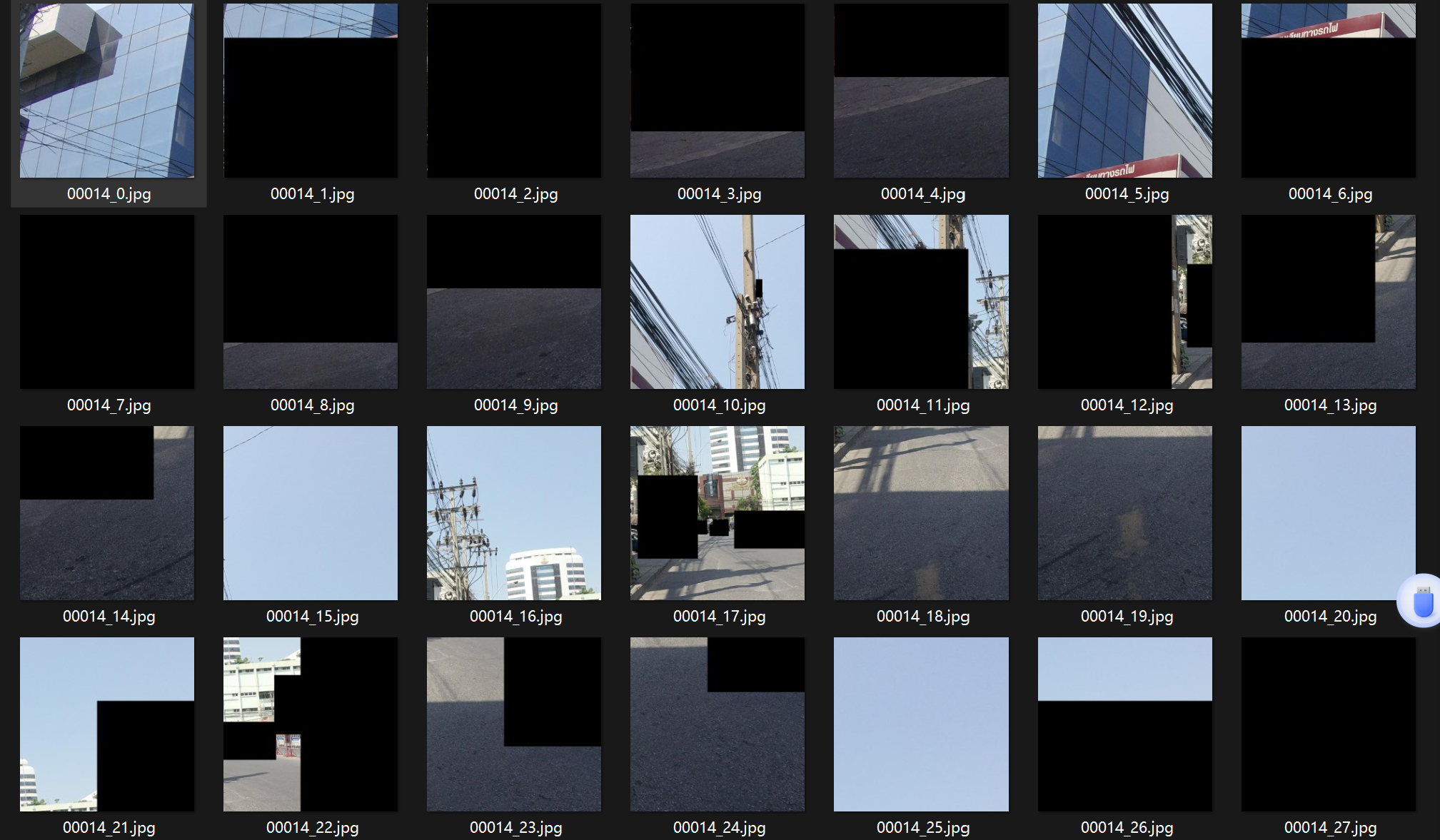
数据集的处理主要做了两个操作,分别是将一张图像剪切为多张固定大小的图像,并为图像添加掩膜,如下图所示:
从处理结果来看,黑框部分即为小目标的标注框,那么论文中有粗略到精细的意思应该便是将这个数据集中的图像进行切分,然后在这个新构建的数据集中进行实验,新构建的数据集即为精细数据集,而原始数据集即为粗略数据集。
修改配置文件
首先是tools/train.py文件,确定要训练的模型与配置文件:
parser.add_argument('--config',default="D:\graduate\programs\CFINet-master\CFINet-master\configs\cfinet/faster_rcnn_r50_fpn_cfinet_1x.py", help='train config file path')
随后创建一个文件夹work_dirs,用于存储日志与模型文件,如下图所示
找到刚刚的配置文件,根据里面的配置信息去修改数据集路径,batch-size,训练轮次等信息:
数据集配置文件路径:CFINet-master\configs\_base_\datasets\sodad.py,具体内容如下:
dataset_type = 'SODADDataset'
data_root = 'E:\datasets\SODAD\SODAD'#修改
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(800, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(800, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img']),
])
]
#修改下面的数据集路径
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
ann_file=data_root + '/Annotations/train.json',
img_prefix=data_root + '/Images/train/',
pipeline=train_pipeline,
ori_ann_file=data_root + '/Annotations/train_ori.json'
),
val=dict(
type=dataset_type,
ann_file=data_root + '/Annotations/val.json',
img_prefix=data_root + '/Images/val/',
pipeline=test_pipeline,
ori_ann_file=data_root + '/Annotations/val_ori.json'
),
test=dict(
type=dataset_type,
ann_file=data_root + '/Annotations/test.json',
img_prefix=data_root + '/Images/test/',
pipeline=test_pipeline,
ori_ann_file=data_root + '/Annotations/test_ori.json'
))
batch_size与epoch参数在CFINet-master\configs\cfinet\faster_rcnn_r50_fpn_cfinet_1x.py,分别对应samples_per_gpu与total_epochs 参数
修改完成后即可运行train.py文件了,运行界面如下:
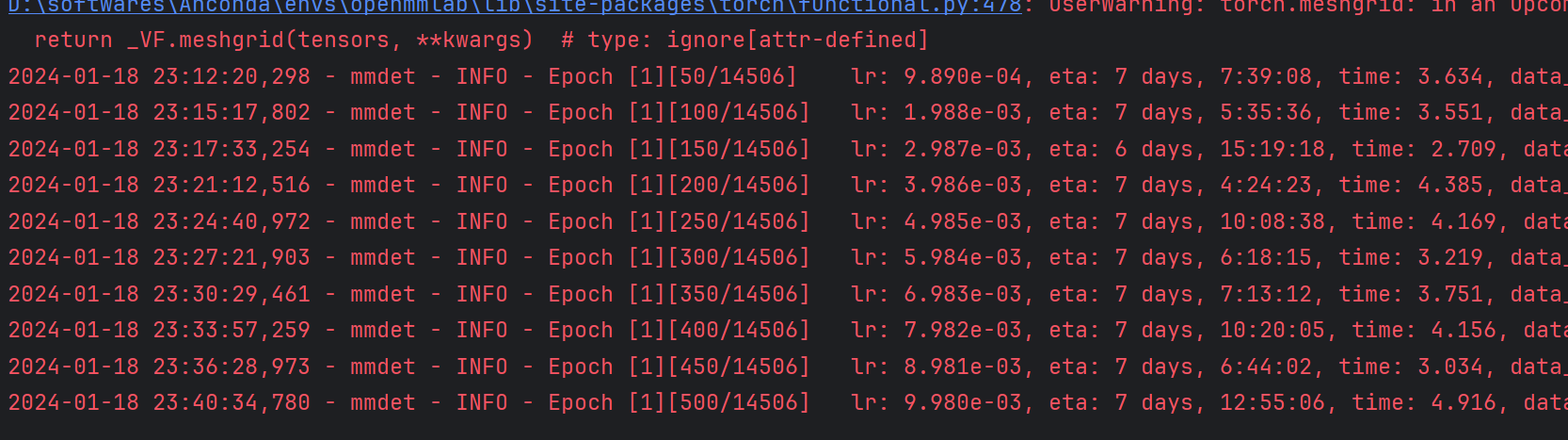
可以看到该模型的运行时间很长,预计需要7天。显存占用情况如下:

至此,该模型的调试过程便结束了,码字不易,给个赞呗。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Numpy生成01和范围数组
- 数据库 delete 表数据,磁盘空间还是被一直占用,为什么?
- [C#]winform部署yolov8图像分类的openvino格式的模型
- 基于SQL的可观测性现状观察
- 资料 分析
- MySQL高级DBA的理论与实践,MySQL数据库管理员从入门到精通
- Inscribe:应用非定向资产交易协议 布局巨大铭文赛道
- 优秘智能:开创AI人工智能未来,共筑智能生活之梦
- 基于ssm日用品网站设计论文
- TA百人计划学习笔记 2.6伽马矫正