106、Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
简介
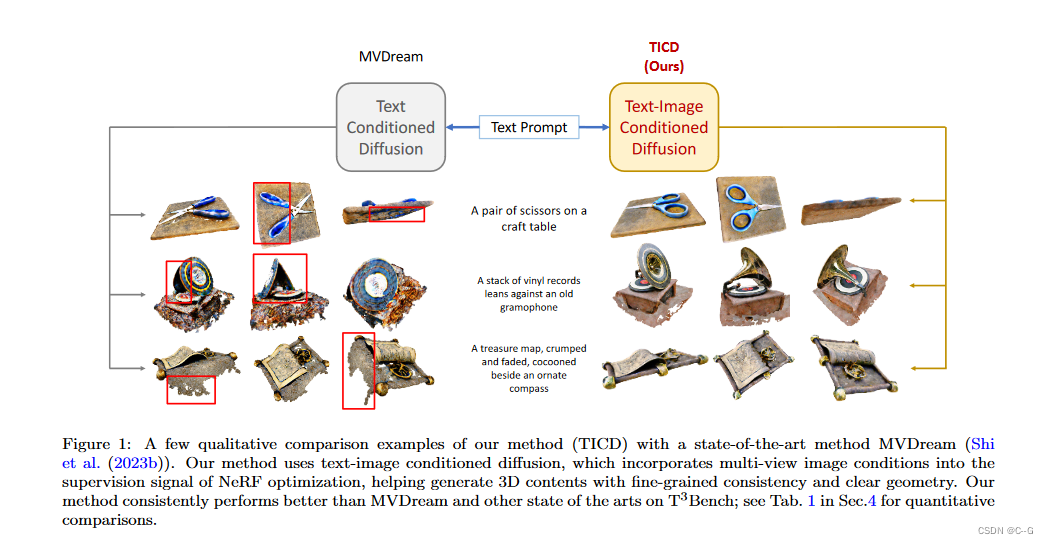
?很多工作在扩散先验中注入跨视图一致性,但仍然缺乏细粒度的视图一致性。论文提出的文本到3d的方法有效地减轻了漂浮物(由于密度过大)和完全空白空间(由于密度不足)的产生。
实现过程
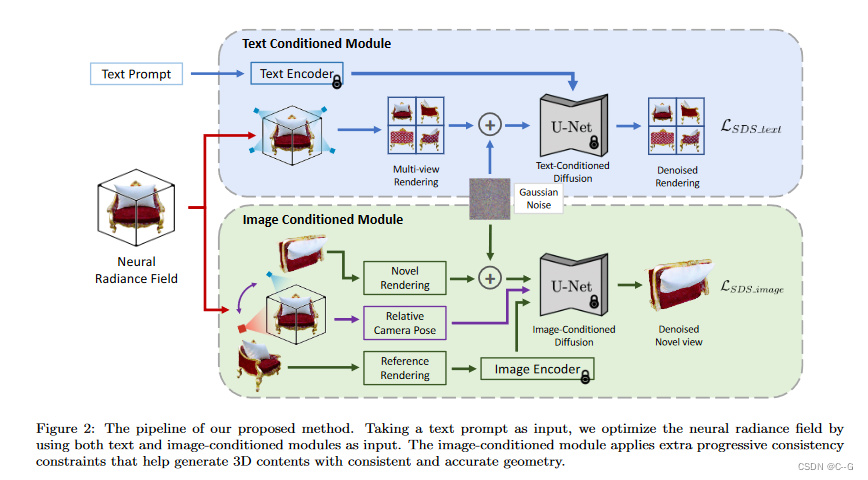
?简单而言,论文工作是 Dreamfusion+Zero123。
?使用两种不同的分数蒸馏进行监督:文本条件下的多视图扩散模型(维护文本的多视图一致性)和图像条件下的新视图扩散模型(维护视图之间的一致性)。
?对于3D表示,实现了threeststudio的隐式体积方法,该方法由多分辨率哈希网格和用于预测体素密度和RGB值的MLP网络组成
文本条件下的多视图扩散模型
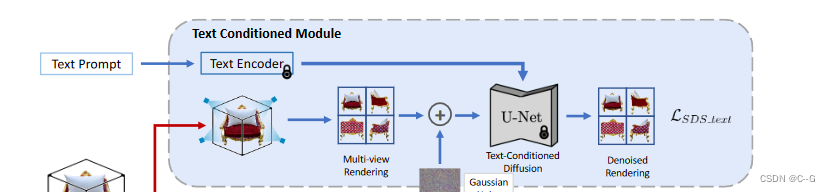
?对一组相机姿势 c 进行采样,并渲染这些视图 x = g(φ, c),称之为参考视图,视图 x 的选择使它们彼此正交。对于每个视图,采样一个时间步长 t,并计算扩散过程 z t i z^i_t zti? 的正演过程,给定文本 y 和NeRF渲染的带噪视图集 z t z_t zt?,文本条件扩散模型 x ^ θ 1 ( z t ; y , c , t ) \hat{x}_{θ_1} (z_t;y, c, t) x^θ1??(zt?;y,c,t) 计算分数函数 w.rt 到 z t z_t zt?,得到一个向高密度区域的更新方向。
?使用MVDream 的预训练模型作为多视图扩散模型
图像条件下的新视图扩散模型
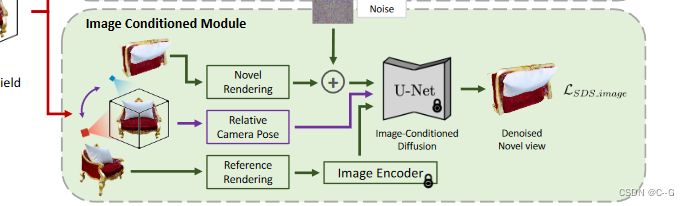
?将其作为额外的监督来指导不同的视图,并确保细粒度的多视图一致性。在相机位姿
c
j
c_j
cj?渲染额外的视图
x
j
x_j
xj? ,计算表示从相机位置 i 到 j 的相对相机外部
c
(
j
→
i
)
c^{(j→i)}
c(j→i)。公式中,图像条件扩散模型以渲染图像
x
j
x_j
xj? 和相对相机外部
c
(
j
→
i
)
c^{(j→i)}
c(j→i)作为条件。从均匀分布中抽样 t 。训练模型计算新视图
z
t
i
z^i_t
zti? 的分数函数,记为
x
^
θ
2
(
z
t
i
;
x
j
,
c
(
j
→
i
)
,
t
)
\hat{x}_{\theta_2}(z^i_t;x^j,c^{(j\rightarrow i)},t)
x^θ2??(zti?;xj,c(j→i),t)
?使用Zero-1-to-3 提供的Zero123-xl作为图像条件扩散模型
score distillation
?总的分数函数如下:
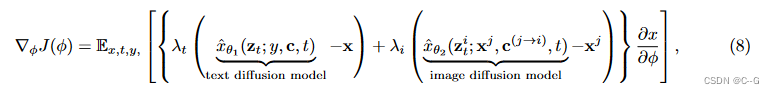
?式中
λ
t
λ_t
λt? 和
λ
i
λ_i
λi? 分别为文本扩散模型和图像扩散模型的比例因子
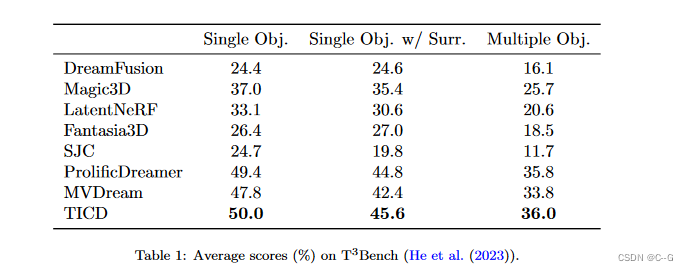
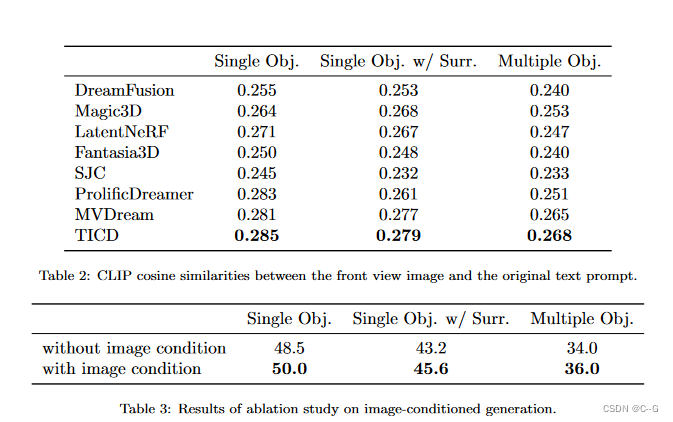
实验
?在视图选择方面,首先随机选择视场(fov)在[15,60]和高度在[0,30]之间的摄像机,用于多视图扩散模型,相机距离设置为物体大小(0.5)乘以NDC焦距和一个随机缩放因子,范围为[0.8,1.0],从上述集合中随机选择视图作为新视图扩散模型的参考视图。对于每个参考视图,在应用新的视图图像条件扩散模型之前,选择一个具有相同视场和海拔在[- 30,80]之间的额外随机摄像机。对于多视图模型和新视图模型,批处理大小分别从8和12开始,然后在5000次迭代后减少到4和4
?3D模型使用AdamW 优化器优化10000步。哈希网格和MLP组件的学习率分别设置为0.01和0.001。应用分数蒸馏采样,在前8000步中,最大和最小时间步分别从0.98减少到0.5和0.02。损失尺度因子λt和λi均设为1.0。渲染分辨率从64×64开始,在5000步之后增加到256×256。多视角模型和新视角模型的指导尺度分别为50.0和3.0。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- test coverate-03-测试覆盖率 EMMA 一款免费的Java代码覆盖工具 emma 和 jacoco 对比
- 学Java的第三天
- 【AI】免费搭建一个属于自己的GeminiProGpt
- FBX/3MF格式在线转换
- Android NestedScrollView悬浮固定顶部
- Find My产品种类越来越多,伦茨科技ST17H6x芯片为你的产品保驾护航
- 前端监控与埋点
- 公司想做一套数字化管理系统,该怎么做?
- 项目一:踏上Java开发之旅
- 汇编语言学习(4)