Traceroute 详解
前言
如果您是网络管理员,系统管理员或任何系统操作团队的一员,那么您可能已经听说过名为TRACEROUTE的工具。默认情况下,它是大多数操作系统中都提供的非常方便的工具。
网络管理员和系统管理员在日常活动中最常使用此工具。它基本上是一个非常方便的网络诊断工具。跟踪路由工具的三个主要主要目标。通过traceroute实现的这些目标可以洞悉您的网络问题。
- 数据包通过的整个路径
- 路径中路由器和设备的名称和标识
- 网络延迟,或更具体地说是在路径上向每个设备发送和接收数据所花费的时间
它是一种工具,可用于确定数据到达目的地的路径,而无需实际发送数据。
就像我在文章中经常说的那样,了解特定工具的工作原理总是很有益的。因为它的用法不能帮助您理解问题并排除故障。但是其背后的工具概念始终可以使您深入了解问题。始终可以在网上甚至在Linux手册和信息页面中找到如何使用命令。
在本文中,我将解释traceroute的工作方式和traceroute工具的类型及其区别。我们还将研究Linux中可用于traceroute命令的细节。
敲黑板讲基础
您在互联网上发送的每个IP数据包都有一个称为TTL的字段。TTL表示生存时间。尽管将其称为“生存时间”,但实际上并非以秒为单位的时间,而是其他时间。
TTL不是用秒数来衡量的,而是用跳数来衡量的。它是数据包在丢弃之前可以通过互联网传播的最大跳数。
跃点只是源与目标之间所经过的计算机,路由器或其他网络设备。
如果根本没有TTL怎么办?如果IP数据包中没有TTL,则该数据包将不断地从一台路由器流向另一台路由器,并不断地搜索目的地。TTL值由发送者在其IP数据包内设置(使用系统或发送数据包的人不知道这些事情在幕后进行,而是由操作系统自动处理)。
如果在(跳)之间经过太多路由器后找不到目的地,并且TTL值变为0(表示不再需要被传输),则接收路由器将丢弃该数据包并通知原始发送者。
通知原始发送方TTL值已超过,它无法进一步转发数据包。
假设我需要达到10.1.136.23 IP地址,而我的默认TTL值为30跳。这意味着我最多可以经过30跳才能到达目的地,然后丢弃数据包。
但是介于两者之间的路由器将如何确定已达到TTL值限制。在发送到下一个路由器之前,位于源和目标之间的每个路由器将继续减小TTL值。这意味着如果我的默认TTL值为30,则我的第一个路由器会将其减小为29,然后将其发送到路径中的下一个路由器。
接收路由器将其设置为28,然后发送到下一个,依此类推。如果路由器接收到TT1为1的数据包(这意味着不再继续传输,也没有转发),则该数据包将被丢弃。但是丢弃该数据包的路由器将通知原始发送者TTL值已超过。
由接收到TTL为1的数据包的路由器发送回原始发送者的信息称为“ ICMP TTL超出消息”。当然,在互联网上,当您向接收方发送邮件时,接收方会知道发送方的地址。
因此,当路由器发送超过ICMP TTL的消息时,原始发送者将知道路由器的地址。
Traceroute利用此TTL超出的消息来查找穿过您的目的地路径的路由器(因为路由器发送的这些超出的消息将包含其地址)。
但是Traceroute如何使用TTL超时消息来找出两者之间的路由器/跳数?
您可能在想,TTL超时消息仅由接收到TTL为1的数据包的路由器发送。是的,您和接收方之间的每个路由器都不会发送TTL超时消息。然后,您将如何找到您与目的地之间的所有路由器/跳的地址。因为Traceroute的主要目的是识别您与目的地之间的跃点。
但是,您可以通过故意发送TTL值为1的IP数据包来利用路由器/跳之间发送TTL超出消息的行为。
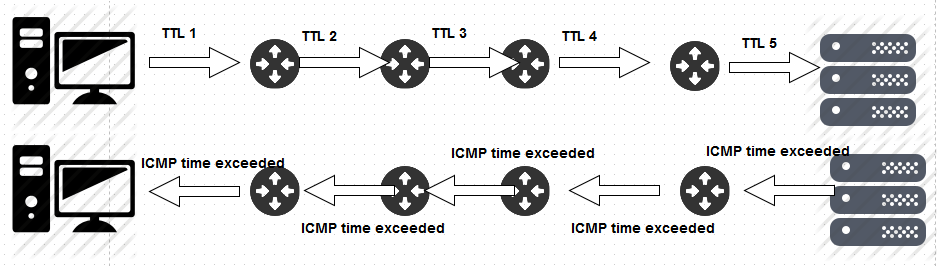
在下图中,请参见整个过程的示例图,其中,发送方向远程服务器之一进行跟踪路由。
因此,假设我想对Google的公用DNS服务器(8.8.8.8)进行跟踪路由。我的traceroute命令及其结果如下所示。
?root@workstation:~# traceroute -n 8.8.8.8 ?traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets ? 1 192.168.0.1 6.768 ms 6.462 ms 6.223 ms ? 2 183.83.192.1 5.842 ms 5.543 ms 5.288 ms ? 3 183.82.14.5 5.078 ms 6.755 ms 6.468 ms ? 4 183.82.14.57 20.789 ms 27.609 ms 27.931 ms ? 5 72.14.194.18 17.821 ms 17.652 ms 17.465 ms ? 6 66.249.94.170 19.378 ms 15.975 ms 23.017 ms ? 7 209.85.241.21 16.633 ms 16.607 ms 17.428 ms ? 8 8.8.8.8 17.144 ms 17.662 ms 17.228 ms ?
让我们看看到底发生了什么。当我执行traceroute -n 8.8.8.8的命令时,我的计算机要做的是制作一个UDP数据包,该UDP数据包将包含以下内容。
- 我的源地址(这是我的IP地址)
- 目的地址(8.8.8.8)
- 无特殊用途和功能的目的地UDP端口号。意味着traceroute实用程序会将数据包发送到范围为33434至33534的UDP端口,该端口通常未使用。
因此,让我们看看这东西是如何工作的。
步骤1:“?我的源地址”将创建一个数据包,该数据包的目标ip地址为8.8.8.8,目标端口号介于33434至33534之间。重要的是,它使TTL值1
步骤2:?当然,我的数据包将到达网关服务器。看到接收到的数据包后,我的网关服务器将TTL减小1(中间的所有路由器/跳台都将TTL值减小1)。一旦将TTL减少1(1-1 = 0)的值,则TTL值将变为零。因此,我的网关服务器将发回TTL超时消息。请记住,当我的网关服务器向我发送TTL超出消息时,它将发送我发送的初始数据包的前28个字节的标头。
步骤3:?收到此TTL超时消息后,我的traceroute程序将知道源地址和有关第一跳的其他详细信息(这是我的网关服务器。)。
步骤4:现在,traceroute程序将再次发送相同的UDP数据包,其目标地址为8.8.8.8,并在33434至33534之间发送一个随机的UDP目标端口。但这一次,我将设置初始?TTL2?。?这是因为我的网关路由器会将其减少1,然后转发发送到下一跳/路由器的同一数据包(由我的网关发送到其下一跳的数据包的TTL值为1)。
步骤5:在接收到UDP数据包后,到我的网关服务器的下一跳将再次将其减小为1,这意味着现在TTL再次变为0。因此,它将向我发送回ICMP超时消息,并带有其源地址,并且也是我发送的数据包的第一个28字节标头。
步骤6:?在收到超过TTL时间的消息后,我的traceroute程序将了解该跃点/路由器的IP地址,并将其显示在我的屏幕上。
步骤7:现在,我的traceroute程序再次使用类似的UDP数据包,并使用一个随机udp端口,其目标地址为8.8.8.8。但是这次,ttl的值设为3,这样当ttl到达第三个跃点/路由器时,ttl将自动变为0(请记住,我的网关及其下一个跃点会将其减小1)。这样它就会以TTL超时消息答复我,并且我的traceroute程序将知道该跃点/路由器的IP地址。
步骤8:在收到该答复后,traceroute程序将再次生成TTL值为4的UDP数据包。如果我也超过了TTL时间,那么我的traceroute程序将发送TTL为5的UDP数据包,依此类推。
但是我的traceroute程序将如何知道8.8.8.8的最终目标已经到达。traceroute程序会知道这一点,因为,当数据包8.8.8.8的原始接收者(记住所有UDP数据包的目标地址为8.8.8.8)收到请求时,它将向我发送一条消息,该消息将完全不同从所有消息“ TTL时间已超出”。
当原始接收者(8.8.8.8)获得我的UDP数据包时,它将向我发送“ ICMP目标/端口不可达”消息。这势必会发生,因为我们总是在33434至33534之间发送一个随机UDP端口。因此,我的Traceroute程序将知道我们已经到达了最终目的地,并且将停止发送任何其他数据包。
现在,用言语描述的任何东西都称为理论。我们需要通过在执行traceroute时执行tcpdump来确认这一点。让我们看一下tcpdump的输出。请注意,我不会向您显示tcpdump的整个输出,因为它太长了。
在Linux机器的一个终端上运行traceroute。在另一个终端上,运行以下tcpdump命令以查看发生了什么。
?root@workstation:~# tcpdump -n '(icmp or udp)' -vvv ?12:13:06.585187 IP (tos 0x0, ttl 1, id 37285, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.43143 > 8.8.8.8.33434: [bad udp cksum 0xd157 -> 0x0e59!] UDP, length 32 ?12:13:06.585218 IP (tos 0x0, ttl 1, id 37286, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.38682 > 8.8.8.8.33435: [bad udp cksum 0xd157 -> 0x1fc5!] UDP, length 32 ?12:13:06.585228 IP (tos 0x0, ttl 1, id 37287, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.48381 > 8.8.8.8.33436: [bad udp cksum 0xd157 -> 0xf9e0!] UDP, length 32 ?12:13:06.585237 IP (tos 0x0, ttl 2, id 37288, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.57602 > 8.8.8.8.33437: [bad udp cksum 0xd157 -> 0xd5da!] UDP, length 32 ?12:13:06.585247 IP (tos 0x0, ttl 2, id 37289, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.39195 > 8.8.8.8.33438: [bad udp cksum 0xd157 -> 0x1dc1!] UDP, length 32 ?12:13:06.585256 IP (tos 0x0, ttl 2, id 37290, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.47823 > 8.8.8.8.33439: [bad udp cksum 0xd157 -> 0xfc0b!] UDP, length 32 ?12:13:06.585264 IP (tos 0x0, ttl 3, id 37291, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.52815 > 8.8.8.8.33440: [bad udp cksum 0xd157 -> 0xe88a!] UDP, length 32 ?12:13:06.585273 IP (tos 0x0, ttl 3, id 37292, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.51780 > 8.8.8.8.33441: [bad udp cksum 0xd157 -> 0xec94!] UDP, length 32 ?12:13:06.585281 IP (tos 0x0, ttl 3, id 37293, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.34782 > 8.8.8.8.33442: [bad udp cksum 0xd157 -> 0x2efa!] UDP, length 32 ?12:13:06.585290 IP (tos 0x0, ttl 4, id 37294, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.53015 > 8.8.8.8.33443: [bad udp cksum 0xd157 -> 0xe7bf!] UDP, length 32 ?12:13:06.585299 IP (tos 0x0, ttl 4, id 37295, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.58417 > 8.8.8.8.33444: [bad udp cksum 0xd157 -> 0xd2a4!] UDP, length 32 ?12:13:06.585308 IP (tos 0x0, ttl 4, id 37296, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.55943 > 8.8.8.8.33445: [bad udp cksum 0xd157 -> 0xdc4d!] UDP, length 32 ?12:13:06.585318 IP (tos 0x0, ttl 5, id 37297, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.33265 > 8.8.8.8.33446: [bad udp cksum 0xd157 -> 0x34e3!] UDP, length 32 ?12:13:06.585327 IP (tos 0x0, ttl 5, id 37298, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.53485 > 8.8.8.8.33447: [bad udp cksum 0xd157 -> 0xe5e5!] UDP, length 32 ?12:13:06.585335 IP (tos 0x0, ttl 5, id 37299, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.40992 > 8.8.8.8.33448: [bad udp cksum 0xd157 -> 0x16b2!] UDP, length 32 ?12:13:06.585344 IP (tos 0x0, ttl 6, id 37300, offset 0, flags [none], proto UDP (17), length 60) ? ? 192.168.0.102.41538 > 8.8.8.8.33449: [bad udp cksum 0xd157 -> 0x148f!] UDP, length 32
上面的输出仅显示了我的机器发送的UDP数据包。我将分别显示答复消息,以使其更加清楚。
注意每行的TTL值。它从1的TTL开始,然后从2开始,然后从3直到TTL6。但是您可能想知道为什么我的服务器发送3 UDP消息,其TTL值为1,然后是2然后是3。
其背后的原因是要计算平均往返时间。Traceroute程序向每个跃点发送三个UDP数据包,以测量确切的平均往返时间。往返时间不过是发送和接收回复所花费的时间(以毫秒为单位)。为了避免混淆,我一开始就没有提到这一点。
因此,最重要的是我的traceroute程序向每个跃点发送了三个UDP数据包,以简单地计算往返平均值。因为traceroute在您的输出中显示了这三个值。请更仔细地查看traceroute输出。它显示每个跃点三个毫秒的值。
现在,让我们看看通过TCPDUMP从所有跃点获得的回复。请注意,下面显示的回复消息是我上面所做的同一tcpdump的一部分,但为了让您更清楚地单独显示了消息。
需要注意的另一件事是,我的traceroute程序每次发送一个不同的随机UDP端口号。这是为了识别答复属于哪个数据包。如前所述,跃点和目的地发送的回复消息包含我们发送的原始数据包的标头,因此traceroute程序可以准确计算往返时间(对于发送到每个跃点的每三个UDP数据包),因为它可以轻松识别答复并相互关联。随机端口号是用于标识回复的标识符。
回复消息如下所示。
?192.168.0.1 > 192.168.0.102: ICMP time exceeded in-transit, length 68 ? ? ? ? IP (tos 0x0, ttl 1, id 37285, offset 0, flags [none], proto UDP (17), le ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ngth 60) ? ? 192.168.0.1 > 192.168.0.102: ICMP time exceeded in-transit, length 68 ? ? ? ? IP (tos 0x0, ttl 1, id 37286, offset 0, flags [none], proto UDP (17), le ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ngth 60) ? ? 183.83.192.1 > 192.168.0.102: ICMP time exceeded in-transit, length 60 ? ? ? ? IP (tos 0x0, id 37288, offset 0, flags [none], proto UDP (17), length 60 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ) ? ? 192.168.0.1 > 192.168.0.102: ICMP time exceeded in-transit, length 68 ? ? ? ? IP (tos 0x0, ttl 1, id 37287, offset 0, flags [none], proto UDP (17), le ? ?
请注意上面显示的回复中的ICMP time over消息(我没有显示所有回复消息)。
现在,让我显示与“ ICMP超时”消息不同的最终消息。如前所述,此消息是无法访问的目标端口。我的traceroute程序将知道我们已经到达目的地了。
?8.8.8.8 > 192.168.0.102: ICMP 8.8.8.8 udp port 33458 unreachable, length 68 ? ? ? ? IP (tos 0x80, ttl 2, id 37309, offset 0, flags [none], proto UDP (17), l ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ength 60) ? ? 8.8.8.8 > 192.168.0.102: ICMP 8.8.8.8 udp port 33457 unreachable, length 68 ? ? ? ? IP (tos 0x80, ttl 1, id 37308, offset 0, flags [none], proto UDP (17), l ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ength 60) ? ? 8.8.8.8 > 192.168.0.102: ICMP 8.8.8.8 udp port 33459 unreachable, length 68 ? ? ? ? IP (tos 0x80, ttl 2, id 37310, offset 0, flags [none], proto UDP (17), l ?
请注意,从8.8.8.8到我的traceroute程序有3条回复。如前所述,traceroute使用不同的端口发送三个类似的UDP数据包,以简单地计算往返时间。最终目的地没有什么不同。
不同类型的Traceroute程序
有不同类型的traceroute程序。他们每个人的工作略有不同。但是它们背后的总体概念是相同的。它们全部使用TTL值。
为什么要使用不同的实现?那是因为您可以使用适合您的环境的一种。如果假设防火墙阻止了UDP流量,则可以为此使用另一个跟踪路由。 不同类型将在下面提到。
- UDP跟踪路由
- ICMP跟踪路由
- TCP跟踪路由
我们之前使用的是UDP traceroute。它是linux traceroute程序使用的默认协议。但是,您可以通过以下命令要求Linux中的traceroute实用程序使用ICMP代替UDP。
?root@workstation:~# traceroute -I -n 8.8.8.8
跟踪路由的ICMP与UDP跟踪路由的工作方式相同。Traceroute程序将发送ICMP Echo Request消息,并且之间的跃点将以ICMP Time beyond消息进行回复。但是最终目的地将以ICMP Echo答复进行答复。
Windows操作系统中可用的Tracert命令默认情况下使用ICMP traceroute方法。
现在,最后一个是最有趣的一个。它称为TCP traceroute。之所以使用它,是因为几乎所有的防火墙和路由器之间都允许您发送TCP通信。如果数据包是通过端口80发送的,该端口是Web流量,则大多数路由器都允许该数据包。默认情况下,TCPTRACEROUTE将TCP SYN请求发送到端口80。
源和目标之间的所有路由器都将发送TTL超时消息,并且如果端口80关闭,则目标将发送RST数据包,或者将发送SYN / ACK数据包(但是tcptraceroute不会在接收到以下消息后建立tcp连接) SYN / ACK数据包,traceroute程序将发送一个RST数据包以关闭连接)。因此,traceroute程序知道目的地已经到达。
请注意,我在先前显示的traceroute命令中使用的-n选项不会进行DNS名称解析。否则,traceroute将发送dns查询途中发现的所有跃点。
现在主要的问题是我应该从icmp,udp和tcp traceroutes中使用哪一个?
一切都取决于当时的情况。假设源和目的地之间的路由器阻塞了特定协议,源就必须尝试使用其他协议。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【2023-08-19】美团秋招笔试五道编程题解
- 基于java的旅游景区预约管理系统(源码+开题)
- 31--设计模式、面向对象设计原则
- python+requests搭建接口自动化测试框架
- Windows下Navicat15.0连接Oracle11g报ORA-28547解决
- easyrecovery数据恢复软件15安装下载免注册版本下载
- C++一般类成员
- 【GitHub项目推荐--6 个 Github 项目学习 Spring Boot】【转载】
- 【Java 并发】ThreadPool
- MySQL的事务以及springboot中如何使用事务