哈希表-散列表数据结构
1、什么是哈希表?
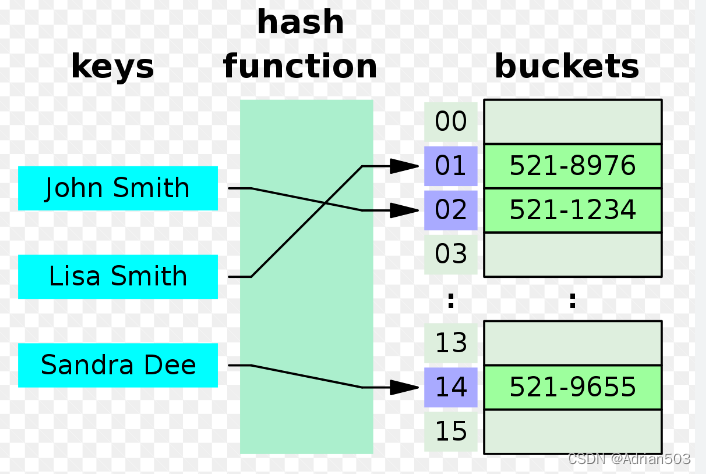
哈希表也叫散列表,哈希表是根据关键码值(key value)来直接访问的一种数据结构,也就是将关键码值(key value)通过一种映射关系映射到表中的一个位置来加快查找的速度,这种映射关系称之为哈希函数或者散列函数,存放记录的数组称之为哈希表。
哈希表采用的是一种转换思想,其中一个中要的概念是如何将「Key」转换成数组下标?
在哈希表中,这个过程有哈希函数来完成,但是并不是每个「Key」都需要通过哈希函数来将其转换成数组下标,有些「Key」可以直接作为数组的下标。
举例:
用哈希表来存放员工信息,我们可以利用员工号作为「Key」就可以直接作为数据的下标,不需要通过哈希函数进行转化。
如果我们用员工姓名作为「Key」,这时候我们就需要哈希函数来帮我们转换成数组的下标。
换句话说,哈希函数是帮我们把 非int 的「Key」转化成 int,用来做数组的下标。
在?uthash 开源C代码中,哈希函数主要使用了以下几种:

详细可以参考 https://troydhanson.github.io/uthash/userguide.html
2、哈希表主要解决什么问题?
?? ?
哈希表提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,插入和查找的时间复杂度都是为O(1),因为哈希表的查找速度非常快,所以在很多程序中都有使用哈希表,例如拼音检查器。
· 事先不需要排序。
· 搜寻速度与数据多少无关。
3、内核中哪些算法用的了哈希表?
?举例:
linux 跑起来的时候 有很多进程,那有很多 task_struct 怎么连接呢?
linux里面有三种数据结构来连接task_struct ,? 链表(方便遍历的时候用),树(方便找父进程),哈希表(方便从pid 找到task_struct)。
4、C语言如何使用哈希表?
uthash 是用宏实现的一个头文件,即可实现哈希表的一些列操作。
https://troydhanson.github.io/uthash/userguide.html#_a_hash_in_c
GitHub - troydhanson/uthash: C macros for hash tables and more
参考:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024济南老龄产业展,山东养老用品展,山东老年护理用品展
- 绝地求生:PUBG到底怎么穿?
- 腾讯云老客户如何变成新用户?薅新用户羊毛
- (每日持续更新)信息系统项目管理(第四版)(高级项目管理)考试重点整理第6章 项目管理理论(一)
- 图片处理convert命令详解
- react+mobx强制刷新之后会使保存的状态丢失怎么解决
- VUE--包管理器
- [RK-Linux] 移植Linux-5.10到RK3399(十)| 配置AP6256模组使能WIFI、BT功能
- 苍穹外卖项目笔记(10)— 订单处理、客户催单
- SpingBoot的项目实战--模拟电商【1.首页搭建】