Kubernetes实战(十四)-k8s高可用集群扩容master节点
1?单master集群和多master节点集群方案
1.1?单Master集群

k8s 集群是由一组运行 k8s 的节点组成的,节点可以是物理机、虚拟机或者云服务器。k8s 集群中的节点分为两种角色:master 和 node。
- master 节点:master 节点负责控制和管理整个集群,它运行着一些关键的组件,如 kube-apiserver、kube-scheduler、kube-controller-manager 等。master 节点可以有一个或多个,如果有多个 master 节点,那么它们之间需要通过 etcd 这个分布式键值存储来保持数据的一致性。
- node 节点:node 节点是承载用户应用的工作节点,它运行着一些必要的组件,如 kubelet、kube-proxy、container runtime 等。node 节点可以有一个或多个,如果有多个 node 节点,那么它们之间需要通过网络插件来实现通信和路由。
一般情况下我们会搭建单master多node集群。它是一种常见的 k8s 集群架构,它只有一个 master 节点和多个 node 节点。这种架构的优点是简单易搭建,适合用于学习和测试 k8s 的功能和特性。这种架构的缺点是 master 节点成为了单点故障,如果 master 节点出现问题,那么整个集群就无法正常工作。
搭建 k8s 单 master 多 node 集群有多种方法,根据不同的需求和场景,可以选择合适的方式来搭建和运维node集群。一般来说,有以下几种常见的方式:
- 使用kubeadm:这是一种使用官方提供的工具kubeadm来快速创建和管理node集群的方式。kubeadm可以自动安装和配置node节点上所需的组件,如kubelet、kube-proxy、容器运行时等。这种方式适用于学习和测试目的,或者简单的生产环境。
- 使用kops:这是一种使用开源工具kops来在云服务商(如AWS、GCP等)上创建和管理node集群的方式。kops可以自动创建和配置云资源,如虚拟机、网络、存储等,并安装和配置node节点上所需的组件。这种方式适用于在云端部署高可用和可扩展的node集群。
- 使用其他工具或平台:这是一种使用其他第三方提供的工具或平台来创建和管理node集群的方式。例如,你可以使用Ansible、Terraform、Rancher等工具来自动化和定制node集群的创建和配置过程。或者,你可以使用云服务商提供的托管服务(如EKS、GKE、AKS等)来直接创建和管理node集群。这种方式适用于不同的需求和偏好,但可能需要更多的学习和调试成本。
1.2?Master 高可用架构
kubernetes多master集群是指使用多个master节点来提高集群的可用性和容错性的方案。master节点是负责控制和管理集群中的资源和服务的节点,它运行着以下组件:
- kube-apiserver:提供了HTTP REST接口的关键服务进程,是集群中所有资源的增、删、改、查等操作的唯一入口,也是集群控制的入口进程。
- kube-scheduler:负责资源调度(Pod调度)的进程,相当于公交公司的“调度室”。
- kube-controller-manager:集群中所有资源对象的自动化控制中心,可以将其理解为资源对象的“大总管”。
Kubernetes 作为容器集群系统,通过健康检查 + 重启策略实现了 Pod 故障自我修复能力,通过调度算法实现将 Pod 分布式部署,并保持预期副本数,根据 Node 失效状态自动在其他 Node 拉起 Pod,实现了应用层的高可用性。
针对 Kubernetes 集群,高可用性还应包含以下两个层面的考虑:Etcd 数据库的高可用性和 Kubernetes Master 组件的高可用性。
Master 节点扮演着总控中心的角色,通过不断与工作节点上的 Kubelet 和 kube-proxy 进行通信来维护整个集群的健康工作状态。如果 Master 节点故障,将无法使用 kubectl 工具或者 API 做任何集群管理。
Master 节点主要有三个服务 kube-apiserver、kube-controller-manager 和 kube-scheduler,其中 kube-controller-manager 和 kube-scheduler 组件自身通过选择机制已经实现了高可用,所以 Master 高可用主要针对 kube-apiserver 组件,而该组件是以 HTTP API 提供服务,因此对他高可用与 Web 服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
多 Master 架构图:
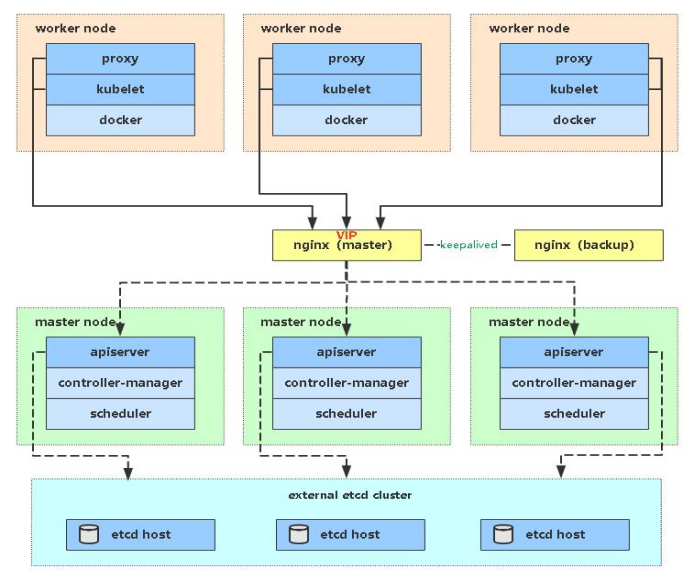
实现kubernetes master集群有多种方式,根据不同的需求和场景,可以选择合适的方式来搭建和运维master集群。一般来说,根据实现方式,负载均衡集群可以分为以下几种方案:
- 硬件负载均衡:硬件负载均衡是使用专门的硬件设备来实现负载均衡的方案,如 F5、Cisco 等。硬件负载均衡的优点是性能高、稳定性强,缺点是成本高、扩展性差。
- 软件负载均衡:软件负载均衡是使用普通的服务器和软件来实现负载均衡的方案,如 Nginx、HAProxy 等。软件负载均衡的优点是成本低、扩展性好,缺点是性能低、稳定性差。
- 混合负载均衡:混合负载均衡是结合硬件和软件来实现负载均衡的方案,如使用硬件设备作为全局入口,使用软件作为局部分发。混合负载均衡的优点是兼顾了性能和成本,缺点是复杂度高、维护难。
1.2.1?存储高可用集群
etcd:分布式键值存储系统,用于保存集群中所有资源对象的状态和元数据。
k8s配置高可用(HA)Kubernetes etcd集群。
可以设置 以下两种HA 集群:
- 使用堆叠(stacked)控制平面节点,其中 etcd 节点与控制平面节点共存
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行
1.2.1.1?堆叠(Stacked)etcd 拓扑--内置etcd集群
堆叠(Stacked)HA集群是一种这样的拓扑,其中 etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的一个组件运行。
每个控制平面节点运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。 kube-apiserver 使用负载均衡器暴露给工作节点。
每个控制平面节点创建一个本地etcd成员(member),这个 etcd 成员只与该节点的 kube-apiserver 通信。 这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例。
这种拓扑将控制平面和 etcd 成员耦合在同一节点上。相对使用外部 etcd 集群, 设置起来更简单,而且更易于副本管理。
然而,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则etcd 成员和控制平面实例都将丢失, 并且冗余会受到影响。你可以通过添加更多控制平面节点来降低此风险。
因此应该为 HA 集群运行至少三个堆叠的控制平面节点。
这是 kubeadm 中的默认拓扑。当使用 kubeadm init 和 kubeadm join --control-plane 时, 在控制平面节点上会自动创建本地 etcd 成员。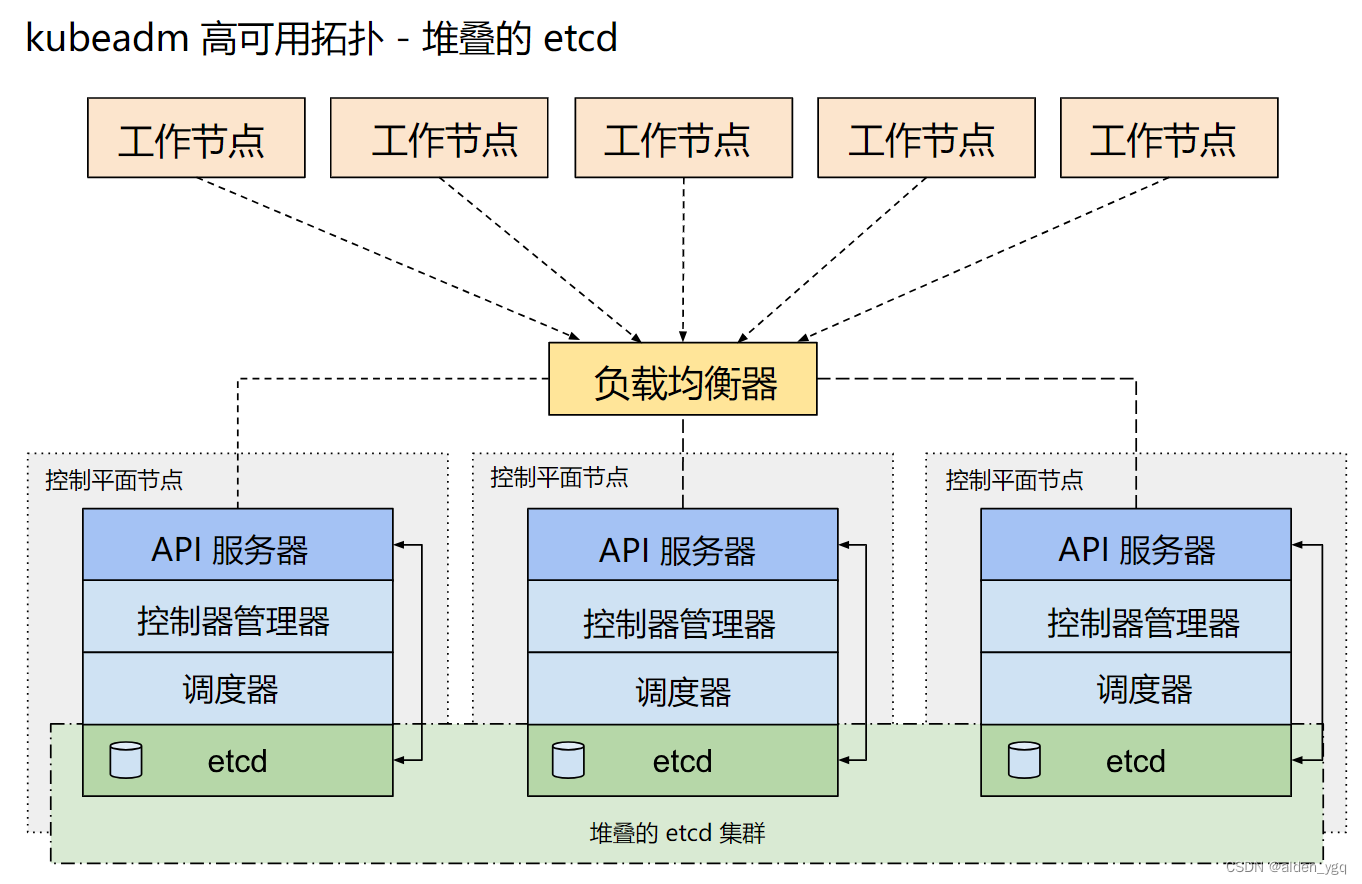
?1.2.1.2?外部 etcd 拓扑--外部etcd集群
具有外部 etcd 的 HA 集群是一种这样的拓扑, 其中 etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行。
就像堆叠的 etcd 拓扑一样,外部 etcd 拓扑中的每个控制平面节点都会运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。 同样,kube-apiserver 使用负载均衡器暴露给工作节点。但是 etcd 成员在不同的主机上运行, 每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信。
这种拓扑结构解耦了控制平面和 etcd 成员。因此它提供了一种 HA 设置, 其中失去控制平面实例或者 etcd 成员的影响较小,并且不会像堆叠的 HA 拓扑那样影响集群冗余。
但此拓扑需要两倍于堆叠 HA 拓扑的主机数量。 具有此拓扑的 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机。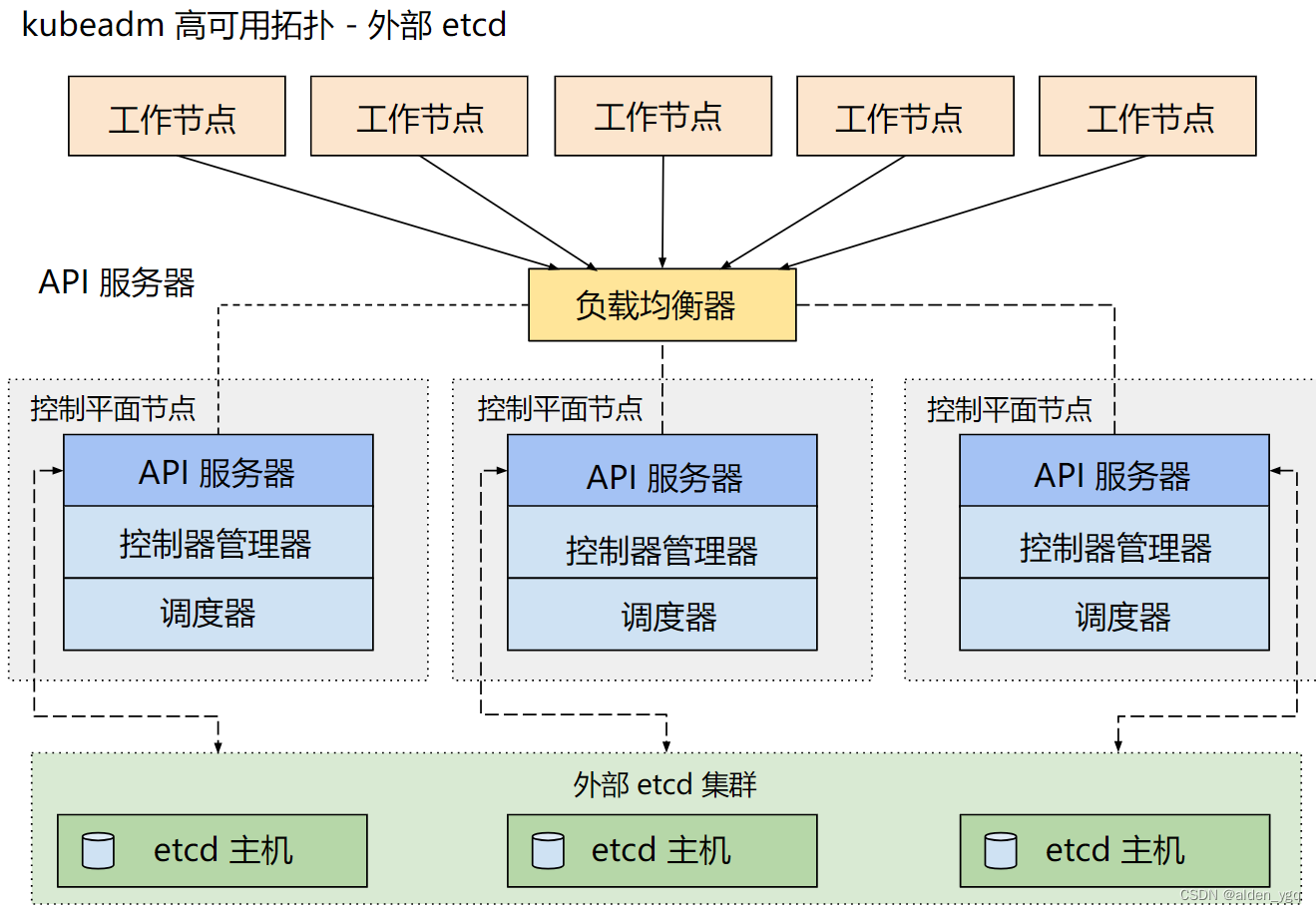
2 高可用集群部署实战
2.1?单master节点升级为高可用集群
2.1.1 部署负载均衡
nginx节点信息:10.220.43.211:16443
2.1.1.1 安装nginx
此处负载均衡以nginx为例。
$ yum install nginx -y2.1.1.2 配置nginx
$ vim /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 10.220.43.203:6443; # Master1 APISERVER IP:PORT
}
server {
listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}2.1.1.3 启动nginx
$ nginx -t
$ systemctl start nginx2.1.2 master切换
2.1.2.1 更新k8s证书?
ops-master-1操作。
如果是用kubeadm init 来创建的集群,那么需要导出一个kubeadm配置?。
$ kubectl -n kube-system get configmap kubeadm-config -o jsonpath='{.data.ClusterConfiguration}' > kubeadm.yaml
$ cat kubeadm.yaml
apiServer:
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.21.9
networking:
dnsDomain: cluster.local
podSubnet: 172.25.0.0/16
serviceSubnet: 192.168.0.0/16
scheduler: {}2.1.2.2?添加证书SANs信息
$ vim kubeadm.yaml
apiServer:
certSANs:
- 10.220.43.211
- 10.220.43.203
- 10.220.43.204
- 10.220.43.205
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 10.220.43.211:6443
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.21.9
networking:
dnsDomain: cluster.local
podSubnet: 172.25.0.0/16
serviceSubnet: 192.168.0.0/16
scheduler: {}2.1.2.3?生成新证书
2.1.2.3.1 备份旧证书
$ mkdir bak
$ mv /etc/kubernetes/pki/apiserver.{crt,key} bak/2.1.2.3.2?生成新证书
$ kubeadm init phase certs apiserver --config kubeadm.yaml
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local ops-master-1] and IPs [192.168.0.1 10.220.43.203 10.220.43.211 10.220.43.204 10.220.43.205]2.1.2.3.3?验证证书
确定包含新添加的SAN列表。
$ openssl x509 -in /etc/kubernetes/pki/apiserver.crt -text
......
X509v3 Subject Alternative Name:
DNS:kubernetes, DNS:kubernetes.default, DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster.local, DNS:ops-master-1, IP Address:192.168.0.1, IP Address:10.220.43.203, IP Address:10.220.43.211, IP Address:10.220.43.204, IP Address:10.220.43.205
......2.1.2.3.5?重启apiserver
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-5d4b78db86-rrgw4 1/1 Running 0 54m 172.25.13.1 ops-master-1 <none> <none>
calico-node-jk7zc 1/1 Running 0 51m 10.220.43.204 ops-worker-1 <none> <none>
calico-node-p2c7d 1/1 Running 0 54m 10.220.43.203 ops-master-1 <none> <none>
calico-node-v8z5x 1/1 Running 0 51m 10.220.43.205 ops-worker-2 <none> <none>
coredns-59d64cd4d4-gkrz6 1/1 Running 0 87m 172.25.13.2 ops-master-1 <none> <none>
coredns-59d64cd4d4-nmdfh 1/1 Running 0 87m 172.25.13.3 ops-master-1 <none> <none>
etcd-ops-master-1 1/1 Running 0 87m 10.220.43.203 ops-master-1 <none> <none>
kube-apiserver-ops-master-1 1/1 Running 0 87m 10.220.43.203 ops-master-1 <none> <none>
kube-controller-manager-ops-master-1 1/1 Running 0 87m 10.220.43.203 ops-master-1 <none> <none>
kube-proxy-f7mct 1/1 Running 0 51m 10.220.43.205 ops-worker-2 <none> <none>
kube-proxy-j9bmp 1/1 Running 0 51m 10.220.43.204 ops-worker-1 <none> <none>
kube-proxy-pm77c 1/1 Running 0 87m 10.220.43.203 ops-master-1 <none> <none>
kube-scheduler-ops-master-1 1/1 Running 0 87m 10.220.43.203 ops-master-1 <none> <none>$ kubectl delete pod kube-controller-manager-ops-master-1 -n kube-system
pod "kube-controller-manager-ops-master-1" deleted2.1.2.3.6?保存新配置
$ kubeadm init phase upload-config kubeadm --config kubeadm.yaml
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace2.1.2.4?更新配置
证书更新完成了,负载均衡也部署好了,接下来就需要把所有用到旧地址的组件配置修改成负载均衡的地址。
2.1.2.4.1?kubelet.conf
$ vim /etc/kubernetes/kubelet.conf
...
server: https://10.220.43.211:16443
name: kubernetes
...
$ systemctl restart kubelet2.1.2.4.2?controller-manager.conf
$ vim /etc/kubernetes/controller-manager.conf
...
server: https://10.220.43.211:16443
name: kubernetes
...
# 重启kube-controller-manager
$ kubectl delete pod -n kube-system kube-controller-manager-ops-master-12.1.2.4.3??scheduler.conf
$ vim /etc/kubernetes/scheduler.conf
...
server: https://10.220.43.211:16443
name: kubernetes
...
# 重启kube-scheduler
$ kubectl delete pod -n kube-system kube-scheduler-ops-master-12.1.2.4.4?kube-proxy
$ kubectl edit configmap kube-proxy -n kube-system
...
kubeconfig.conf: |-
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server: https://10.220.43.211:16443
name: default
contexts:
- context:
cluster: default
namespace: default
user: default
name: default
...
configmap/kube-proxy edited
$ kubectl rollout restart daemonset kube-proxy -n kube-system2.1.2.4.5?修改kubeconfig
~/.kube/config?和?/etc/kubernetes/admin.conf都需要修改。?
$ vim /etc/kubernetes/admin.conf
...
server: https://10.220.43.211:16443
name: kubernetes
...
$ vim /root/.kube/config
...
server: https://10.220.43.211:16443
name: kubernetes
...2.1.3?worker切换apiserver
2.1.3.1 kubelet.conf
$ vim /etc/kubernetes/kubelet.conf
...
server: https://10.220.43.211:16443
name: kubernetes
...
$ systemctl restart kubelet2.1.3.2?修改kubeconfig
只需要修改~/.kube/config?。
$ vim /etc/kubernetes/admin.conf
...
server: https://10.220.43.211:16443
name: kubernetes
...2.1.4?验证
2.1.4.1 master验证
ops-master-1验证。
$ cat /root/.kube/config | grep server
server: https://10.220.43.211:16443
$ kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-5d4b78db86-rrgw4 1/1 Running 0 65m
calico-node-jk7zc 1/1 Running 0 62m
calico-node-p2c7d 1/1 Running 0 65m
calico-node-v8z5x 1/1 Running 0 62m
coredns-59d64cd4d4-gkrz6 1/1 Running 0 97m
coredns-59d64cd4d4-nmdfh 1/1 Running 0 97m
etcd-ops-master-1 1/1 Running 0 98m
kube-apiserver-ops-master-1 1/1 Running 0 98m
kube-controller-manager-ops-master-1 1/1 Running 0 5m44s
kube-proxy-dhjxj 1/1 Running 0 2m30s
kube-proxy-rm64j 1/1 Running 0 2m32s
kube-proxy-xg6bp 1/1 Running 0 2m35s
kube-scheduler-ops-master-1 1/1 Running 0 4m16s
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ops-master-1 Ready control-plane,master 101m v1.21.9
ops-worker-1 Ready <none> 65m v1.21.9
ops-worker-2 Ready <none> 65m v1.21.92.1.4.2 worker验证?
ops-worker-1节点验证。?
$ kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-5d4b78db86-rrgw4 1/1 Running 0 74m
calico-node-jk7zc 1/1 Running 0 71m
calico-node-p2c7d 1/1 Running 0 74m
calico-node-v8z5x 1/1 Running 0 71m
coredns-59d64cd4d4-gkrz6 1/1 Running 0 107m
coredns-59d64cd4d4-nmdfh 1/1 Running 0 107m
etcd-ops-master-1 1/1 Running 0 107m
kube-apiserver-ops-master-1 1/1 Running 0 107m
kube-controller-manager-ops-master-1 1/1 Running 0 14m
kube-proxy-dhjxj 1/1 Running 0 11m
kube-proxy-rm64j 1/1 Running 0 11m
kube-proxy-xg6bp 1/1 Running 0 11m
kube-scheduler-ops-master-1 1/1 Running 0 13m$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ops-master-1 Ready control-plane,master 109m v1.21.9
ops-worker-1 Ready <none> 74m v1.21.9
ops-worker-2 Ready <none> 73m v1.21.92.2??高可用集群新增master节点
新master节点:10.220.43.209 ops-master-2
2.2.1 新master部署k8s服务
2.2.1.1 各节点增加新master 信息
# ops-master-1/ops-worker-1/ops-worker-2:
echo "10.220.43.209 ops-master-2" >> /etc/hosts2.2.1.2 k8s服务部署?
参考:Kubernetes实战(九)-kubeadm安装k8s集群-CSDN博客??
2.2.2? 新master加入集群
$ kubeadm join 10.220.43.211:16443 --token 9puv2h.sr5dvg9skqlqhofm --discovery-token-ca-cert-hash sha256:b85555d7fdf2e1f28afe09dcb649117a34ac330ace38434fb604e2705b5df207 --control-plane --certificate-key a96e54087b299b962dae6321e519386fd9bdb1876a6cd4067c55484a0fe0c5e0
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost ops-master-2] and IPs [10.220.43.209 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost ops-master-2] and IPs [10.220.43.209 127.0.0.1 ::1]
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local ops-master-2] and IPs [192.168.0.1 10.220.43.209 10.220.43.211 10.220.43.203 10.220.43.204 10.220.43.205]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[mark-control-plane] Marking the node ops-master-2 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node ops-master-2 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
This node has joined the cluster and a new control plane instance was created:
* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.加入成功。
2.2.3 查看状态
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ops-master-1 Ready control-plane,master 147m v1.21.9
ops-master-2 NotReady control-plane,master 27s v1.21.9
ops-worker-1 Ready <none> 111m v1.21.9
ops-worker-2 Ready <none> 111m v1.21.9状态更新需要等待,等到2-3分钟后再查看:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ops-master-1 Ready control-plane,master 150m v1.21.9
ops-master-2 Ready control-plane,master 3m46s v1.21.9
ops-worker-1 Ready <none> 114m v1.21.9
ops-worker-2 Ready <none> 114m v1.21.9$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-5d4b78db86-rrgw4 1/1 Running 0 117m 172.25.13.1 ops-master-1 <none> <none>
calico-node-f5s6w 1/1 Running 0 4m1s 10.220.43.209 ops-master-2 <none> <none>
calico-node-jk7zc 1/1 Running 0 114m 10.220.43.204 ops-worker-1 <none> <none>
calico-node-p2c7d 1/1 Running 0 117m 10.220.43.203 ops-master-1 <none> <none>
calico-node-v8z5x 1/1 Running 0 114m 10.220.43.205 ops-worker-2 <none> <none>
coredns-59d64cd4d4-gkrz6 1/1 Running 0 150m 172.25.13.2 ops-master-1 <none> <none>
coredns-59d64cd4d4-nmdfh 1/1 Running 0 150m 172.25.13.3 ops-master-1 <none> <none>
etcd-ops-master-1 1/1 Running 0 150m 10.220.43.203 ops-master-1 <none> <none>
etcd-ops-master-2 1/1 Running 0 3m56s 10.220.43.209 ops-master-2 <none> <none>
kube-apiserver-ops-master-1 1/1 Running 0 150m 10.220.43.203 ops-master-1 <none> <none>
kube-apiserver-ops-master-2 1/1 Running 0 3m56s 10.220.43.209 ops-master-2 <none> <none>
kube-controller-manager-ops-master-1 1/1 Running 1 5m9s 10.220.43.203 ops-master-1 <none> <none>
kube-controller-manager-ops-master-2 1/1 Running 0 3m56s 10.220.43.209 ops-master-2 <none> <none>
kube-proxy-dhjxj 1/1 Running 0 54m 10.220.43.203 ops-master-1 <none> <none>
kube-proxy-rm64j 1/1 Running 0 54m 10.220.43.204 ops-worker-1 <none> <none>
kube-proxy-xg6bp 1/1 Running 0 54m 10.220.43.205 ops-worker-2 <none> <none>
kube-proxy-zcvzs 1/1 Running 0 4m1s 10.220.43.209 ops-master-2 <none> <none>
kube-scheduler-ops-master-1 1/1 Running 1 56m 10.220.43.203 ops-master-1 <none> <none>
kube-scheduler-ops-master-2 1/1 Running 0 3m56s 10.220.43.209 ops-master-2 <none> <none>新master节点各种组件已将安装完毕。?
2.2.4 验证高可用
2.2.4.1 停掉ops-master-1
[root@ops-master-1 ~]# init 02.2.4.2?其他节点验证
[root@ops-master-2 etc]# kubectl get nodes
Error from server: etcdserver: request timed out[root@ops-worker-1 .kube]# kubectl get nodes
Error from server: rpc error: code = Unknown desc = OK: HTTP status code 200; transport: missing content-type field?经分析,是因为coredns均分布在ops-master-1节点上,当ops-master-1节点挂掉后,无可用coredns。
2.2.4.3?coredns打散分布
$ kubectl delete pod coredns-59d64cd4d4-gkrz6 -n kube-system
pod "coredns-59d64cd4d4-gkrz6" deleted$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-5d4b78db86-rrgw4 1/1 Running 1 125m 172.25.13.6 ops-master-1 <none> <none>
calico-node-f5s6w 1/1 Running 0 11m 10.220.43.209 ops-master-2 <none> <none>
calico-node-jk7zc 1/1 Running 0 122m 10.220.43.204 ops-worker-1 <none> <none>
calico-node-p2c7d 1/1 Running 1 125m 10.220.43.203 ops-master-1 <none> <none>
calico-node-v8z5x 1/1 Running 0 122m 10.220.43.205 ops-worker-2 <none> <none>
coredns-59d64cd4d4-nmdfh 1/1 Running 1 158m 172.25.13.5 ops-master-1 <none> <none>
coredns-59d64cd4d4-zr4hd 1/1 Running 0 40s 172.25.78.65 ops-worker-1 <none> <none>
etcd-ops-master-1 1/1 Running 1 158m 10.220.43.203 ops-master-1 <none> <none>
etcd-ops-master-2 1/1 Running 1 11m 10.220.43.209 ops-master-2 <none> <none>
kube-apiserver-ops-master-1 1/1 Running 1 158m 10.220.43.203 ops-master-1 <none> <none>
kube-apiserver-ops-master-2 1/1 Running 4 11m 10.220.43.209 ops-master-2 <none> <none>
kube-controller-manager-ops-master-1 1/1 Running 2 12m 10.220.43.203 ops-master-1 <none> <none>
kube-controller-manager-ops-master-2 1/1 Running 1 11m 10.220.43.209 ops-master-2 <none> <none>
kube-proxy-dhjxj 1/1 Running 1 62m 10.220.43.203 ops-master-1 <none> <none>
kube-proxy-rm64j 1/1 Running 0 62m 10.220.43.204 ops-worker-1 <none> <none>
kube-proxy-xg6bp 1/1 Running 0 62m 10.220.43.205 ops-worker-2 <none> <none>
kube-proxy-zcvzs 1/1 Running 0 11m 10.220.43.209 ops-master-2 <none> <none>
kube-scheduler-ops-master-1 1/1 Running 2 64m 10.220.43.203 ops-master-1 <none> <none>
kube-scheduler-ops-master-2 1/1 Running 1 11m 10.220.43.209 ops-master-2 <none> <none>coredns已打散。
此刻针对ops-master-1节点执行停机操作,但是集群仍然不可用。
经分析是etcd只有两个pod,由于etcd是分布式服务,必须保持基数格式才能完成选举。因此需要再部署一个master节点以保证etcd个数达到基数个。
此处建议使用外拓扑架构的etcd,而不是使用堆叠式的etcd部署架构。?
2.2.5 部署ops-master-3节点
参考:Kubernetes实战(九)-kubeadm安装k8s集群-CSDN博客??
2.2.6?验证
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ops-master-1 Ready control-plane,master 168m v1.21.9
ops-master-2 Ready control-plane,master 21m v1.21.9
ops-master-3 Ready control-plane,master 2m28s v1.21.9
ops-worker-1 Ready <none> 132m v1.21.9
ops-worker-2 Ready <none> 132m v1.21.9ops-master-1节点下线。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ops-master-1 NotReady control-plane,master 168m v1.21.9
ops-master-2 NotReady control-plane,master 22m v1.21.9
ops-master-3 NotReady control-plane,master 2m47s v1.21.9
ops-worker-1 Ready <none> 133m v1.21.9
ops-worker-2 Ready <none> 132m v1.21.9三个master均离线。
经查是因为新master的kubelet.conf配置仍然配置的是:10.220.43.203:6443,当节点ops-master-1(10.220.43.203)挂掉,新master节点将无法集群链接,导致node下线。
解决方案:
$ vim kubelet.conf
......
server: https://10.220.43.211:16443
......
$ systemctl restart kubelet$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ops-master-1 NotReady control-plane,master 4h15m v1.21.9
ops-master-2 Ready control-plane,master 108m v1.21.9
ops-master-3 Ready control-plane,master 88m v1.21.9
ops-worker-1 Ready <none> 3h39m v1.21.9
ops-worker-2 Ready <none> 3h39m v1.21.9?至此,高可用集群新增master节点完成。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 修改ssh端口讲解
- 【SD】语法格式 分析
- Linux嵌入式入门(一)--虚拟机下安装Ubuntu
- [python语言]数据类型
- 【Vue3】3-2 : 组件的概念及组件的基本使用方式
- Linux top命令详解,看这篇就够了
- STM32储存器和总线构架
- C#操作pdf之使用itext实现01-生成一个简单的table
- nacos可视化界面使用说明
- 消息队列-RockMQ-Demo案例&&拓展输入输出渠道