探索检索增强生成(RAG)技术的无限可能:Vector+KG RAG、Self-RAG、多向量检索器多模态RAG集成
探索检索增强生成(RAG)技术的无限可能:Vector+KG RAG、Self-RAG、多向量检索器多模态RAG集成
由于 RAG 的整体思路是首先将文本切分成不同的组块,然后存储到向量数据库中。在实际使用时,将计算用户的问题和文本块的相似度,并召回 top k 的组块,然后将 top k 的组块和问题拼接生成提示词输入到大模型中,最终得到回答。
优化点:
- 优化文本切分的方式,组块大小和重叠的大小都是可以调节的参数
- 多组块召回,可以在检索的时候使用较小长度的组块,然后输入到大模型时使用较大长度的组块获得更充分的上下文信息
- 优化向量模型,使用高性能的向量模型,比如目前我们在使用的 bge,有能力的去微调向量模型能达到更好的效果
- 增加重排序,向量模型召回一个较大数量的组块,然后使用重排序的模型去筛选一个较小数量的组块去生成提示词
- 提示词优化,增加相关的提示词约束可以让大模型输出的结果更稳定,质量更高
RAG 优化分为两个方向:RAG 基础功能优化、RAG 架构优化。我们分别展开讨论。
1.RAG 基础功能优化
对 RAG 的基础功能优化,我们要从 RAG 的流程入手 [1],可以在每个阶段做相应的场景优化。
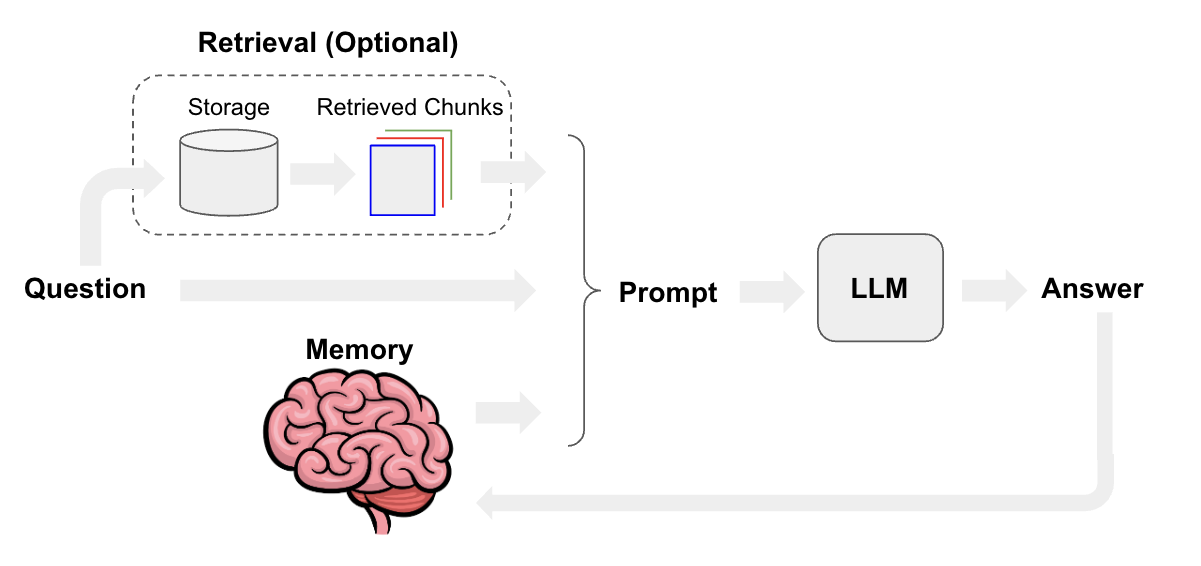
从 RAG 的工作流程看,能优化的模块有:文档块切分、文本嵌入模型、提示工程优化、大模型迭代。下面针对每个模块分别做说明
- 文档块切分:设置适当的块间重叠、多粒度文档块切分、基于语义的文档切分、文档块摘要。
- 文本嵌入模型:基于新语料微调嵌入模型、动态表征。
- 提示工程优化:优化模板增加提示词约束、提示词改写。
- 大模型迭代:基于正反馈微调模型、量化感知训练、提供大 context window 的推理模型。
此外,还可对 query 召回的文档块集合进行处理,比如:元数据过滤 [7]、重排序减少文档块数量 [2]。
2.RAG 架构优化
2.1 Vector+KG RAG
经典的 RAG 架构中,context 增强只用到了向量数据库。这种方法有一些缺点,比如无法获取长程关联知识 [3]、信息密度低。

那此题是否可解?答案是肯定的。一个比较好的方案是增加一路与向量库平行的 KG([知识图谱]上下文增强策略。其技术架构图大致如下 [4]:

图 3 中 query 进行 KG 增强是通过 NL2Cypher 模块实现的。根据我的实践,我们可用更简单的[图采样技术]来进行 KG 上下文增强。具体流程是:根据 query 抽取实体,然后把实体作为种子节点对图进行采样(必要时,可把 KG 中节点和 query 中实体先向量化,通过[向量相似度]设置种子节点),然后把获取的子图转换成文本片段,从而达到上下文增强的效果。
LangChain 官网提供了一个通过 Graph 对 RAG 应用进行增强的 DevOps 的例子,感兴趣的读者可以详细研究 [5]。
2.2 Self-RAG
经典的 RAG 架构中(包括 KG 进行上下文增强),对召回的上下文无差别地与 query 进行合并,然后访问大模型输出应答。但有时召回的上下文可能与 query 无关或者矛盾,此时就应舍弃这个上下文,尤其当大模型上下文窗口较小时非常必要(目前 4k 的窗口比较常见)。
那有解决办法吗?答案又是肯定的,一个较好的解决方案是 Self-RAG 技术。由于篇幅所限,此处介绍其推理过程,训练过程需要借助 GPT4 进行辅助打标,就不展开说了。详细过程可参考我对 Self-RAG 的总结 [6]。

如图 4 所示,右侧就是 Self-RAG 的工作流程。首先,根据 query判断是否需要检索。如果需要,才检索若干 passage,然后经一系列处理生成若干 [next segment]候选。最后,对这些候选 segment 进行排序,生成最终的 next segment。
Self-RAG 的推理过程相对训练较简单,其算法内容如下:

推理过程输入是:prompt x x x和前置生成 y < t y_{<t} y<t?,输出是下一时间步的 segment y t y_t yt?。注意这里的生成任务是 segment 粒度,而不是 token 粒度,主要是出于计算性能方面的考量。
首先由[语言模型] M 预测 Retrieve token 的值。如果为 No,按标准语言模型范式由 x x x 生成 y t y_t yt?,当 y y y 生成完成或到达 y T y_T yT? 时,再预测 IsUSE token 的值。如果 Retrieve token 为 Yes 的话,通过 Retriever 检索出若干个上下文,用 D 表示。针对每个上下文 d,先预测 IsREL token 的值,以此表达上下文与 prompt 是否相关;同时生成下一时间步的 segment y t 。 y_t。 yt?。。然后预测上下文 d 对 y t y_t yt?的支持程度,接着对每个 d 对应的输出 y t y_t yt?进行排序挑选出最优者。最后等 y y y 生成结束时,再预测 IsUSE 的值。
2.3 多向量检索器多模态 RAG
本小节涉及三种工作模式 [7],具体为:
- 半结构化 RAG(文本 + 表格)
- 多模态 RAG(文本 + 表格 + 图片)
- 私有化多模态 RAG(文本 + 表格 + 图片)
1)半结构化 RAG(文本 + 表格)

此模式要同时处理文本与表格数据。其核心流程梳理如下 [8]:
- 将原始文档进行版面分析(基于 Unstructured 工具 [9]),生成原始文本 和 原始表格。
- 原始文本和原始表格经 summary LLM 处理,生成文本 summary 和表格 summary。
- 用同一个 embedding 模型把文本 summary 和表格 summary 向量化,并存入多向量检索器。
- 多向量检索器存入文本 / 表格 embedding 的同时,也会存入相应的 summary 和 raw data。
- 用户 query 向量化后,用 ANN 检索召回 raw text 和 raw table。
- 根据 query+raw text+raw table 构造完整 prompt,访问 LLM 生成最终结果。
2)多模态 RAG(文本 + 表格 + 图片)
对多模态 RAG 而言,有三种技术路线 [10],见下图:

如图 7 所示,对多模态 RAG 而言有三种技术路线,如下我们做个简要说明:
- 选项 1:对文本和表格生成 summary,然后应用多模态 embedding 模型把文本 / 表格 summary、原始图片转化成 embedding 存入多向量检索器。对话时,根据 query 召回原始文本 / 表格 / 图像。然后将其喂给多模态 LLM 生成应答结果。
- 选项 2:首先应用多模态大模型(GPT4-V、LLaVA、FUYU-8b)生成图片 summary。然后对文本 / 表格 / 图片 summary 进行向量化存入多向量检索器中。当生成应答的多模态大模型不具备时,可根据 query 召回原始文本 / 表格 + 图片 summary。
- 选项 3:前置阶段同选项 2 相同。对话时,根据 query 召回原始文本 / 表格 / 图片。构造完整 Prompt,访问多模态大模型生成应答结果。
3)私有化多模态 RAG(文本 + 表格 + 图片)
如果数据安全是重要考量,那就需要把 RAG 流水线进行本地部署。比如可用 LLaVA-7b 生成图片摘要,Chroma 作为向量数据库,Nomic’s GPT4All 作为开源嵌入模型,多向量检索器,Ollama.ai 中的 LLaMA2-13b-chat 用于生成应答 [11]。
3. Self-RAG详解
一直在想两个问题:一是每次 query 时,通过向量库召回上下文是否必要。二是我们用到的推理 LLM 上下文窗口不会太大(比如 Baichuan2-7B/13B 只有 4096,大窗口模型 Baichuan2-192k、GPT-4 Turbo 128k、有 200k 窗口大小的零一万物的 Yi 又不容易拿到),每次 query 召回一大串上下文是否放得下。经调研,有两个方向值得深入研究:
- 在检索上下文有必要的前提下,基于 KG 可以召回高信息密度的上下文。
- 基于 Self-RAG 技术,可以按需检索上下文,同时还可进行自我评判。
3.1应用场景
一般的 RAG 应用会无差别地访问向量库获取上下文,而不管其是否真的需要。这样有可能会引入主题无关的上下文,进而导致低质量的文本生成内容。背后的原因是:推理 LLM 并没有对上下文进行适配性训练,以使生成结果与上下文语义保持一致。如图 1 左侧例子,检索上下文有可能引入有冲突的观点。

而图 1 右侧的 Self-RAG 可有效解决 RAG 中存在的无差别检索上下文的问题。他的大致原理如下:
- 预测 prompt 是否需要上下文来增强文本生成结果。如果需要,则标记一个特殊的 retrieval token,同时根据需要调用 retriever 模块。
- 并行处理检索的上下文,评判上下文对 prompt 的相关性,同时生成相应的结果。
- 评判每个上下文对相应结果的支持程度,同时选择一个最好的生成结果。
上述算法描述中涉及一系列特殊的 token,其具体含义如下所示:

如图 2 所示,Self-RAG 中共有 4 种反思标记(reflection token),大致分为 Retrieve 和 Critique 两大类。其中 Critique 又分为 IsREL、IsSUP、IsUSE 三小类,其中粗体表示某类 token 期望的取值。
3.2 模型推理
第一节从应用场景角度简要概括了 Self-RAG 的工作原理,本小节详细分析 Self-RAG 的推理过程。我们直接给出推理算法如下:

推理过程输入是:prompt x x xx 和前置生成 y < t y_{<t} y<t?,输出是下一时间步的 segment y t y_t yt?。注意这里的生成任务是 segment 粒度,而不是 token 粒度,主要是出于计算性能方面的考量。
首先由语言模型 M 预测 Retrieve token 的值。如果为 No,按标准语言模型范式由 x x x 生成 y t y_t yt?,当 y y y生成完成或到达 y T y_T yT? 时,再预测 IsUSE token 的值。如果 Retrieve token 为 Yes 的话,通过 Retriever 检索出若干个上下文,用 D 表示。针对每个上下文 d,先预测 IsREL token 的值,以此表达上下文与 prompt 是否相关;同时生成下一时间步的 segment y t y_t yt?。 然后预测上下文 d 对 y t y_t yt?的支持程度,接着对每个 d 对应的输出 y t y_t yt?进行排序挑选出最优者。最后等 y y yy生成结束时,再预测 IsUSE 的值。
通过生成 reflection token 自我评判输出,可以使大模型的推理过程更加可控,从而调整其行为以适应多个场景的要求。
3.2.1 自适应检索
Self-RAG 预测 retrieve token 来动态决定是否需要检索上下文。文中指出可以给定阈值,当 Retrieve=Yes 的归一化概率超过阈值时就会触发检索上下文的动作。
3.2.2 基于 critique token 的树解码
在每个 segment step t,如果需要检索的话,则会检索出 K 个上下文。文中提出一种基于 segment 的集束搜索策略(beam search),其 beam_size=B。这样在每个时间步 t,我们可以得到 top-B segment 候选,并且在生成结束时得到最好的 segment 序列。在时间步 t 时,每个上下文 d 对应的 segment 得分计算公式如下:
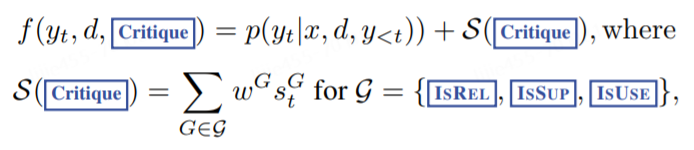
图 4 中的 G 代表 critique token group,比如 IsREL。在时间步 t 时,G 的得分为 s t G = p t ( r ^ ) ∑ i = 1 N G ?? p t ( r i ) s_t^{G}=\frac{p_t(\hat r)}{ {\textstyle \sum_{i=1}^{N^G}} \ \ p_t(r_i) } stG?=∑i=1NG???pt?(ri?)pt?(r^)? ,代表最期望的反思标记 r ^ \hat r r^相对有 N G N^G NG个不同取值的 critique token type G 的概率值。图 4 中的 w G w^G wG可在推理时进行调整,以定制其测试过程的行为。比如为了让 y y y很大程度上受上下文的支持,可给 IsSUP 较高的权重,而给其他 token 较低的权重,这是软性控制行为。通过在解码环节设置 critique,我们也可以释加硬性控制作为。比如当大模型生成一个不被期望的 token 时(IsSUP=No support),就可以放弃对应的 segment 候选。
3.3 模型训练
Self-RAG 的训练过程由两个模型构成:Critic、Generator。前者根据输入 x 和输出 y,生成反思标记 r。然后,我们可以根据 Critic 模型构造新的数据集(采用离线方式把反思标记写入原始数据集中),根据输入 x,来预测输出 y 和反思标记 r。
3.3.1 Critic model
如果采用人工方式为每个 segment 打标 reflection token,这将是一项繁重的工作。由于每种反思标记的定义、输入、输出均有不同,文中采用 GPT-4 为每种反思标记设置不同的指令数据,从而完成打标工作。以 Retrieve 为例 ,我们可以构造一个特定类型的指令数据,然后跟着 few-shot 样例 I,原始的输入 x 和输出 y,我们预测一个合适的反思标记。 p ( r ∣ I , x , y ) p(r|I,x,y) p(r∣I,x,y) 。基于这个思路,可以为每种反思标记生成 4k~20k 条标记数据,他们整体上就是 Critic model 的训练数据。
有了训练数据后,我们便可基于标准的条件语言模型构建训练目标如下:

文中指出 Critic model 可以用任意的语言模型初始化,因此采用与 Generator 同样的模型进行初始化。
3.3.2 Generator model
给定原始输入 x 和输出 y,我们可借助检索器和 Critic model 进行数据增强。对每个 segment y t ∈ y y_t \in y yt?∈y 而言,可用 Critic model 评估是否需要检索上下文来增强文本生成质量。如果需要检索过程,那么置 Retrieve=Yes,同时触发检索器得到 K 个上下文。对每个上下文,Critic model 评判其与 x 是否相关,并预测 IsREL token 的值。如果相关,则用 Critic model 进一步评判上下文是否支持模型生成内容,并预测 IsSUP 的值。接下来,把 IsREL 和 IsSUP 放在上下文或生成 segment 后面。当完整的 y 生成结束时,Critic model 预测整体的可用性 token IsUSE。于是,把反思标记融入原始的输出 + 原始输入,就形成了训练 Generator model 的增强数据。此过程可参考下图:

有了训练数据后,我们可以构造标准的下一标记预测目标函数如下:
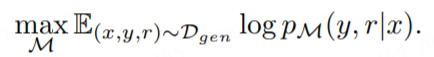
此处需要注意的是:Generator 不仅要预测输出,同时还要预测反思标记。在训练阶段,我们要把检索的上下文(图 6 中用 和 包围的内容)屏蔽掉,以此进行 loss 计算。同时要向原始的词汇表中添加反思标记 Critique、Retrieve,以此来扩充词表。
4.参考资料
- https://www.zhihu.com/question/628651389/answer/3321989558
- Chatbots | ? Langchain
- Rerankers and Two-Stage Retrieval | Pinecone
- Custom Retriever combining KG Index and VectorStore Index
- Enhanced QA Integrating Unstructured Knowledge Graph Using Neo4j and LangChain
- https://blog.langchain.dev/using-a-knowledge-graph-to-implement-a-devops-rag-application/
- AI pursuer:揭秘 Self-RAG 技术内幕
- Multi-Vector Retriever for RAG on tables, text, and images:Multi-Vector Retriever for RAG on tables, text, and images
- https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_Structured_RAG.ipynb?ref=blog.langchain.dev
- Unstructured | The Unstructured Data ETL for Your LLM
- https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_and_multi_modal_RAG.ipynb?ref=blog.langchain.dev
- https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_multi_modal_RAG_LLaMA2.ipynb?ref=blog.langchain.dev
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!