【书生·浦语】大模型实战营—— OpenCompass 大模型评测
发布时间:2024年01月22日
模型评测?????
? ? ? ? 模型评测是指对真实应用场景下模型能力提升效果的测评,可以从模型知识、推理、语言长文本、智能体、多轮对话情感、认知、价值观等方面入手。一般来说可以通过自动化客观评测、人机交互评测以及基于大模型的评测进行评测。
评测原因

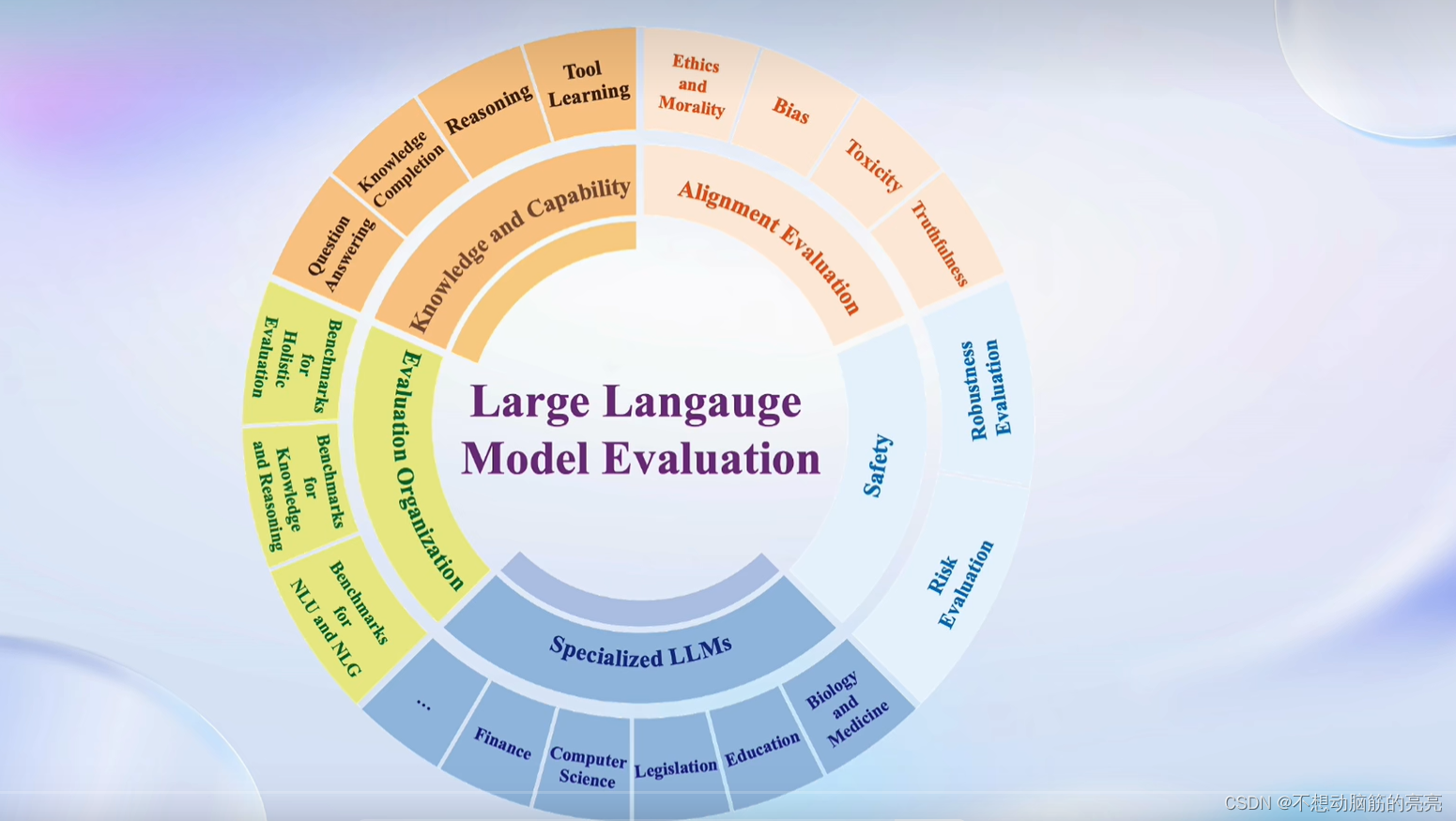
评测内容

评测方法
? ? ? ? 大模型评测根据模型类别有不同的方法。一般来说大模型可以分为只经过预训练的基座模型以及经过了SFT 或者RHF的对话模型?。针对基座模型评测时,需要在prompt中加上一些额外的isntruct。对话模型直接采用和人类对话的方式来进行评测即可。
- ??????基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
- 对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。

? ? ? ? 根据评测的方式可以分为主观评测和客观评测。
- 主观评测:人工评价
- 客观评测:问答题、选择题、判断题等


提示词工程
? ? ? ? 如果提示词换了,模型输出错误,只能说明模型的鲁棒性很差。

主流的评测框架

OpenCompass 能力框架


大模型评测的挑战

文章来源:https://blog.csdn.net/wudongliang971012/article/details/135748989
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 全球知名的五款JavaScript混淆加密工具详解
- 洛谷 P1523 旅行商简化版【线性dp+npc问题简化版】
- 【备战蓝桥杯】快来学吧~ 图论巩固,Delia的生物考试
- 基于方差分解分析气象/水文干旱驱动因素(含MATLAB全代码)
- ansible模块
- new mars3d.graphic.RectangleCombine({生成演示数据代码pt1与pt2详解
- element-ui Vue 封装组件按钮工具栏,使用slot插槽
- 作为一个后端必须要了解的事情
- 优雅而高效的JavaScript——try...catch语句(js异常处理)
- C++之多层 if-else-if 结构优化(三)