SparkSQL 是什么
SparkSQL 是什么
-
数据分析的方式
数据分析的方式大致上可以划分为 SQL 和 命令式两种
-
命令式
在前面的
RDD部分, 非常明显可以感觉的到是命令式的, 主要特征是通过一个算子, 可以得到一个结果, 通过结果再进行后续计算.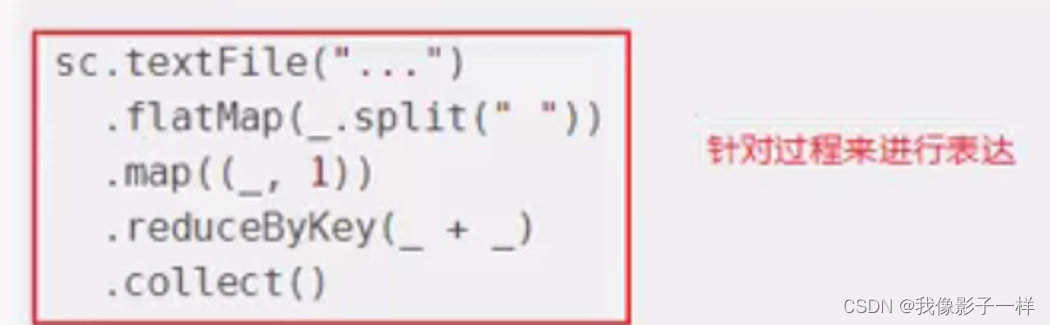
命令式的优点
- 操作粒度更细, 能够控制数据的每一个处理环节
- 操作更明确, 步骤更清晰, 容易维护
- 支持非结构化数据的操作
命令式的缺点
- 需要一定的代码功底
- 写起来比较麻烦
-
SQL
对于一些数据科学家, 要求他们为了做一个非常简单的查询, 写一大堆代码, 明显是一件非常残忍的事情, 所以
SQL on Hadoop是一个非常重要的方向.
SQL 的优点
- 表达非常清晰, 比如说这段
SQL明显就是为了查询三个字段, 又比如说这段SQL明显能看到是想查询年龄大于 10 岁的条目
SQL 的缺点
- 想想一下 3 层嵌套的
SQL, 维护起来应该挺力不从心的吧 - 试想一下, 如果使用
SQL来实现机器学习算法, 也挺为难的吧
SQL擅长数据分析和通过简单的语法表示查询, 命令式操作适合过程式处理和算法性的处理. 在Spark出现之前, 对于结构化数据的查询和处理, 一个工具一向只能支持SQL或者命令式, 使用者被迫要使用多个工具来适应两种场景, 并且多个工具配合起来比较费劲.而
Spark出现了以后, 统一了两种数据处理范式, 是一种革新性的进步. - 表达非常清晰, 比如说这段
-
-
SparkSQL 的特点
因为
SQL是数据分析领域一个非常重要的范式, 所以Spark一直想要支持这种范式, 而伴随着一些决策失误, 这个过程其实还是非常曲折的
-
Hive
解决的问题
Hive实现了SQL on Hadoop, 使用MapReduce执行任务- 简化了
MapReduce任务
新的问题
Hive的查询延迟比较高, 原因是使用MapReduce做调度
-
Shark
解决的问题
Shark改写Hive的物理执行计划, 使用Spark作业代替MapReduce执行物理计划- 使用列式内存存储
- 以上两点使得
Shark的查询效率很高
新的问题
Shark重用了Hive的SQL解析, 逻辑计划生成以及优化, 所以其实可以认为Shark只是把Hive的物理执行替换为了Spark作业- 执行计划的生成严重依赖
Hive, 想要增加新的优化非常困难 Hive使用MapReduce执行作业, 所以Hive是进程级别的并行, 而Spark是线程级别的并行, 所以Hive中很多线程不安全的代码不适用于Spark
由于以上问题,
Shark维护了Hive的一个分支, 并且无法合并进主线, 难以为继 -
SparkSQL
解决的问题
Spark SQL使用Hive解析SQL生成AST语法树, 将其后的逻辑计划生成, 优化, 物理计划都自己完成, 而不依赖Hive- 执行计划和优化交给优化器
Catalyst - 内建了一套简单的
SQL解析器, 可以不使用HQL, 此外, 还引入和DataFrame这样的DSL API, 完全可以不依赖任何Hive的组件 Shark只能查询文件,Spark SQL可以直接降查询作用于RDD, 这一点是一个大进步
新的问题
- 对于初期版本的
SparkSQL, 依然有挺多问题, 例如只能支持SQL的使用, 不能很好的兼容命令式, 入口不够统一等
-
Dataset
SparkSQL在 2.0 时代, 增加了一个新的API, 叫做Dataset,Dataset统一和结合了SQL的访问和命令式API的使用, 这是一个划时代的进步
在Dataset中可以轻易的做到使用SQL查询并且筛选数据, 然后使用命令式API进行探索式分析重要性
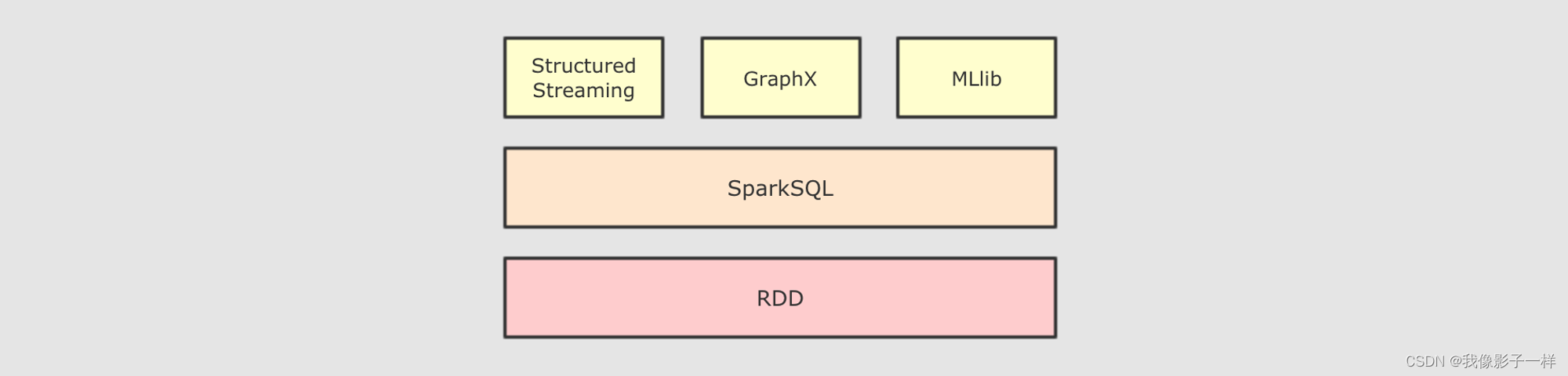
SparkSQL不只是一个SQL引擎,SparkSQL也包含了一套对 结构化数据的命令式API, 事实上, 所有Spark中常见的工具, 都是依赖和依照于SparkSQL的API设计的 -
总结
**SparkSQL是一个为了支持SQL而设计的工具, 但同时也支持命令式的API**
-
-
SparkSQL 的应用场景
定义 特点 举例 结构化数据 有固定的 Schema 有预定义的 Schema 关系型数据库的表 半结构化数据 没有固定的 Schema,但是有结构 没有固定的Schema,有结构信息,数据一般都是自述的 指一些有结构的文件格式。例如JSON 非结构化数据 没有固定的 Schema,也没有结构 没有固定的 Schema,也没有结构 指文档图片之类的格式 -
结构化数据
一般指数据有固定的
Schema, 例如在用户表中,name字段是String型, 那么每一条数据的name字段值都可以当作String来使用+----+--------------+---------------------------+-------+---------+ | id | name | url | alexa | country | +----+--------------+---------------------------+-------+---------+ | 1 | Google | https://www.google.cm/ | 1 | USA | | 2 | 淘宝 | https://www.taobao.com/ | 13 | CN | | 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN | | 4 | 微博 | http://weibo.com/ | 20 | CN | | 5 | Facebook | https://www.facebook.com/ | 3 | USA | +----+--------------+---------------------------+-------+---------+ // 1.字段有约束 // 2.字段类型也有的约束 -
半结构化数据
一般指的是数据没有固定的 Schema, 但是数据本身是有结构的
{ "firstName": "John", "lastName": "Smith", "age": 25, "phoneNumber": [ { "type": "home", "number": "212 555-1234" }, { "type": "fax", "number": "646 555-4567" } ] } // 有列、每一列有类型,可以修改没有严格的约束 -
没有固定 Schema
指的是半结构化数据是没有固定的 Schema 的, 可以理解为没有显式指定 Schema
比如说一个用户信息的 JSON 文件, 第一条数据的 phone_num 有可能是 String, 第二条数据虽说应该也是 String, 但是如果硬要指定为 BigInt, 也是有可能的
因为没有指定 Schema, 没有显式的强制的约束 -
有结构
虽说半结构化数据是没有显式指定 Schema 的, 也没有约束, 但是半结构化数据本身是有有隐式的结构的, 也就是数据自身可以描述自身
例如 JSON 文件, 其中的某一条数据是有字段这个概念的, 每个字段也有类型的概念, 所以说 JSON 是可以描述自身的, 也就是数据本身携带有元信息 -
SparkSQL 处理什么数据的问题?
- Spark 的 RDD 主要用于处理 非结构化数据 和 半结构化数据
- SparkSQL 主要用于处理 结构化数据
-
SparkSQL 相较于 RDD 的优势在哪?
- SparkSQL 提供了更好的外部数据源读写支持
- 因为大部分外部数据源是有结构化的, 需要在 RDD 之外有一个新的解决方案, 来整合这些结构化数据源
- SparkSQL 提供了直接访问列的能力
- 因为 SparkSQL 主要用做于处理结构化数据, 所以其提供的 API 具有一些普通数据库的能力
- SparkSQL 提供了更好的外部数据源读写支持
-
总结: SparkSQL 适用于什么场景?
SparkSQL 适用于处理结构化数据的场景
-
-
本章总结
- SparkSQL 是一个即支持 SQL 又支持命令式数据处理的工具
- SparkSQL 的主要适用场景是处理结构化数据
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【EI会议--快速录用】2024年应用力学与半导体国际学术会议(IACAMS 2024)
- c# OpenCV 检测(斑点检测、边缘检测、轮廓检测)(五)
- 认识字面量
- Linux系统创建并自动启用交换文件
- xray主动扫描和被动扫描
- 3个.NET开源简单易用的任务调度框架
- 时光之美,摩登π:复古韵味,智能生活,感受独特时代氛围
- 创建.gitignore,忽视不必要提交的文件
- Apache Flink连载(二十一):Flink On Yarn运行原理-Yarn Application模式
- 鸿蒙原生应用的“朋友圈”正在进一步扩大!