深入浅出hdfs-hadoop基本介绍
一、Hadoop基本介绍
hadoop最开始是起源于Apache Nutch项目,这个是由Doug Cutting开发的开源网络搜索引擎,这个项目刚开始的目标是为了更好的做搜索引擎,后来Google 发表了三篇未来持续影响大数据领域的三架马车论文:?Google FileSystem、BigTable、Mapreduce开始掀起来了大数据的浪潮,paper原文可以参考我的这篇文章CSDN。
这三篇论文介绍了如何在分布式环境中进行分布式的存储和计算,后来这个项目逐渐演变为一个包括分布式存储系统(Hadoop Distributed File System)和分布式计算处理框架(MapReduce)的一个系统。
Hadoop中有核心的三个组件:HDFS,YARN和Mapreduce.
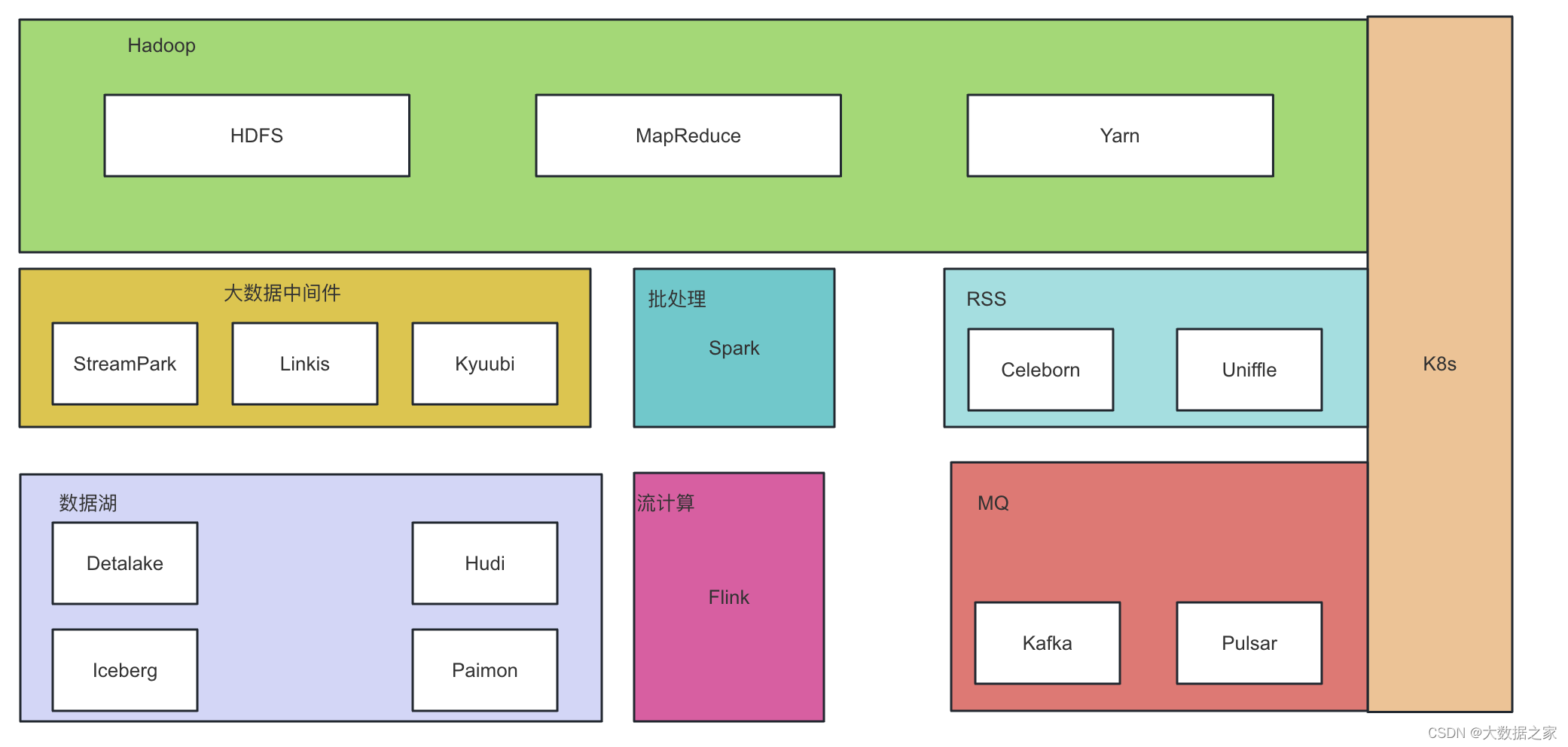
HDFS:主要是分布式的文件存储系统,管理节点是NameNode,存储节点是DataNode,还有其他的JournalNode和zkfc等可以满足HDFS在多NameNode下的的高可用功能。后面会详细介绍各个组件。
MapReduce: 分布式的计算框架,通过任务拆分为MAP + Reduce完成分布式的计算,作为第一代的分布式计算框架,更多依赖的是磁盘,在后续发展的Spark,Tez等引擎在落盘和内存计算中多了更多的策略,满足多种场景的高效数据计算。批处理引擎逐渐会以Spark引擎为主,流计算会以Flink为主,Hive 源码中早起的hive on spark支持会逐渐弱化。Flink batch在未来也会成为一个不确定性。
YARN:大数据的资源调度框架,这个也是MapReduce这个分布式计算框架默认的资源调度组件。主要有FairSchedule和CapacitySchedule,满足map和reduce的job可以在分布式的环境中进行资源调度,在云原生和多云发展背景下,native on k8s在一定程度上可能会替代掉yarn。
随着大数据的蓬勃发展,Hadoop生态持续发展,衍生出更多的开源项目,满足更多的实时和计算需求。下面列入了一些hadoop生态衍生出来的生态圈,覆盖批处理、流计算、大数据中间件、MQ、Remote Shuffer Service、数据湖和云原生等,后续会分篇幅进行应用场景介绍。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 海信电视各个系列方案刷机升级方法教程
- Vue的event-bus的js代码以及event-bus实现总结
- AI跟踪报道第25期-新加坡内哥谈技术-本周AI发展更新-酷炫来袭
- Java 集合面试题之链表
- 19.JavaSE
- SUSE Linux 15 SP5 安装图解
- Android 11.0 mtp模式下连接pc后显示的文件夹禁止删除copy重命名功能实现
- linux常用shell脚本
- Android 13 - Media框架(30)- MediaCodec(五)
- 浅谈VLAN和VXLAN