Centos安装Datax
发布时间:2024年01月11日
Centos7安装DataX
一、DataX简介
????????DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
源码地址点这里
二、DataX的数据源支持
????????DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 图数据库 | 阿里云 GDB | √ | √ | 读 、写 |
| Neo4j | √ | 写 | ||
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | √ | 读 、写 | |
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
三、安装DataX
1、下载DataX
在源码中可以下载到DataX安装包:datax.tar.gz。
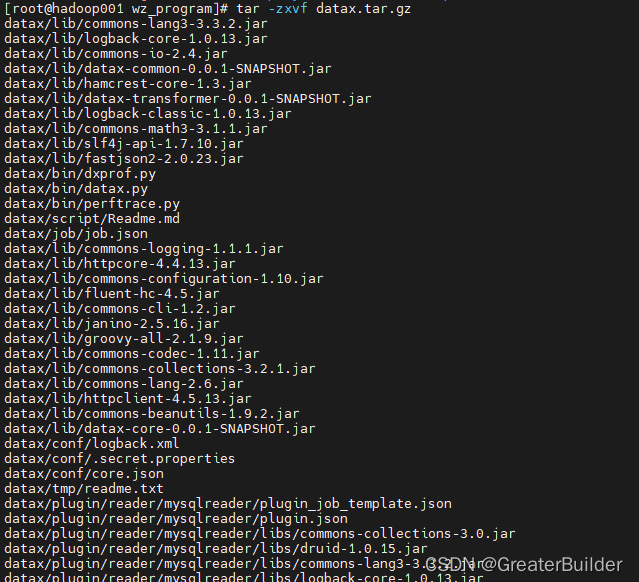
2、解压
tar -zxvf datax.tar.gz
3、检验是否安装成功
# 如下路径更换为自己的路径
python /wz_program/datax/bin/datax.py /wz_program/datax/job/job.json
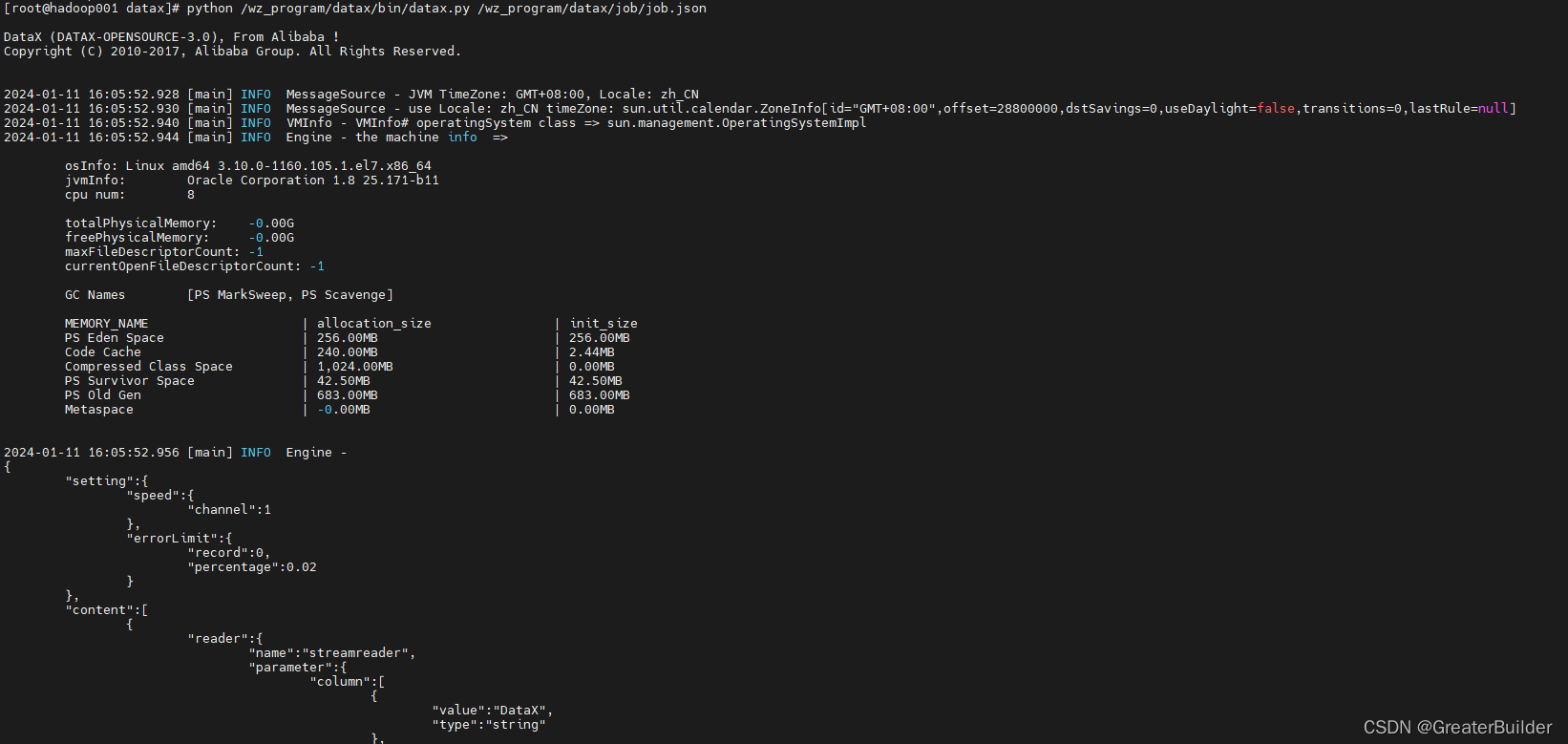
出现如下内容则说明已安装成功:

4、使用
????????DataX使用只需要根据自己同步的数据的数据源与数据的目的地选择对应的Reader和Writer,将Reader和Writer信息配置到一个json文件中,然后执行同步命令即可完成数据同步。
四、实践案例
描述:将mysql数据库user_info表中的1500条数据同步到HDFS的/user_info中(HDFS需要提前安装好)。
1、环境信息
mysql信息如下:
CREATE TABLE `user_info` (
`id` int NOT NULL AUTO_INCREMENT,
`user_id` int NOT NULL,
`username` varchar(255) NOT NULL,
`email` varchar(255) NOT NULL,
`phone_number` varchar(30) DEFAULT NULL,
`status` enum('active','inactive') DEFAULT 'active',
`score` int unsigned DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=16280 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
HDFS信息如下:
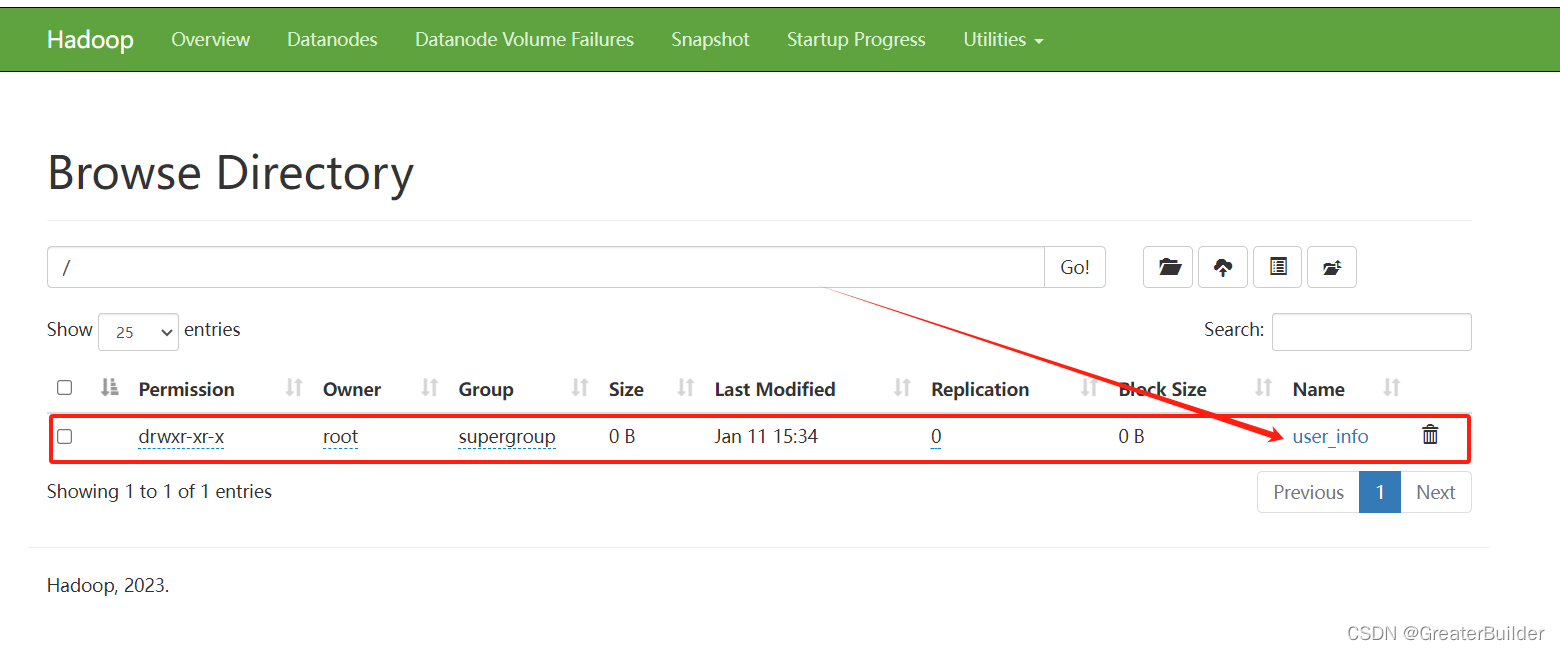
特别注意:DataX向HDFS同步数据时,一定要保证目标路径已存在,否则会同步失败。
hadoop fs -mkdir /user_info
2、编写同步的配置文件(user_info.json)
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [
"id",
"user_id",
"username",
"email",
"phone_number",
"status",
"score"
],
"where": "id>=3",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://*************:3306/hadoop"
],
"table": [
"user_info"
]
}
],
"password": "**********",
"splitPk": "",
"username": "root"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{
"name": "id",
"type": "bigint"
},
{
"name": "user_id",
"type": "bigint"
},
{
"name": "username",
"type": "string"
},
{
"name": "email",
"type": "string"
},
{
"name": "phone_number",
"type": "string"
},
{
"name": "status",
"type": "string"
},
{
"name": "score",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop001:8020",
"fieldDelimiter": "\t",
"fileName": "user_info",
"fileType": "text",
"path": "/user_info",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
MySQLReader配置说明:
{
"name": "mysqlreader", #Reader的名称,固定写法,可以从官方文档中获取到(如上DataX的数据源支持中的表格)
"parameter": {
"column": [ #需要同步的字段,["*"]则表示所有列
"id",
"user_id",
"username",
"email",
"phone_number",
"status",
"score"
],
"where": "id>=3", #where过滤条件,可以过滤掉不需要同步的数据
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://*************:3306/hadoop" #需要同步的数据库url
],
"table": [
"user_info" #需要同步的数据库表名
]
}
],
"password": "**********", #数据库密码
"splitPk": "", #分片字段,如果不指定则只会有单个Task
"username": "root" #数据库用户名
}
}
HDFSWriter的配置说明:
{
"name": "hdfswriter", #Writer的名称,固定写法,可以从官方文档中获取到(如上DataX的数据源支持中的表格)
"parameter": {
"column": [ #列信息,包括列明和类型的设置
{
"name": "id",
"type": "bigint"
},
{
"name": "user_id",
"type": "bigint"
},
{
"name": "username",
"type": "string"
},
{
"name": "email",
"type": "string"
},
{
"name": "phone_number",
"type": "string"
},
{
"name": "status",
"type": "string"
},
{
"name": "score",
"type": "string"
}
],
"compress": "gzip", #HDFS压缩类型,text文件支持gzip和bzip2;orc文件支持NONE和SNAPPY
"defaultFS": "hdfs://hadoop001:8020", #HDFS文件系统namenode节点地址
"fieldDelimiter": "\t", #同步到HDFS文件字段的分隔符
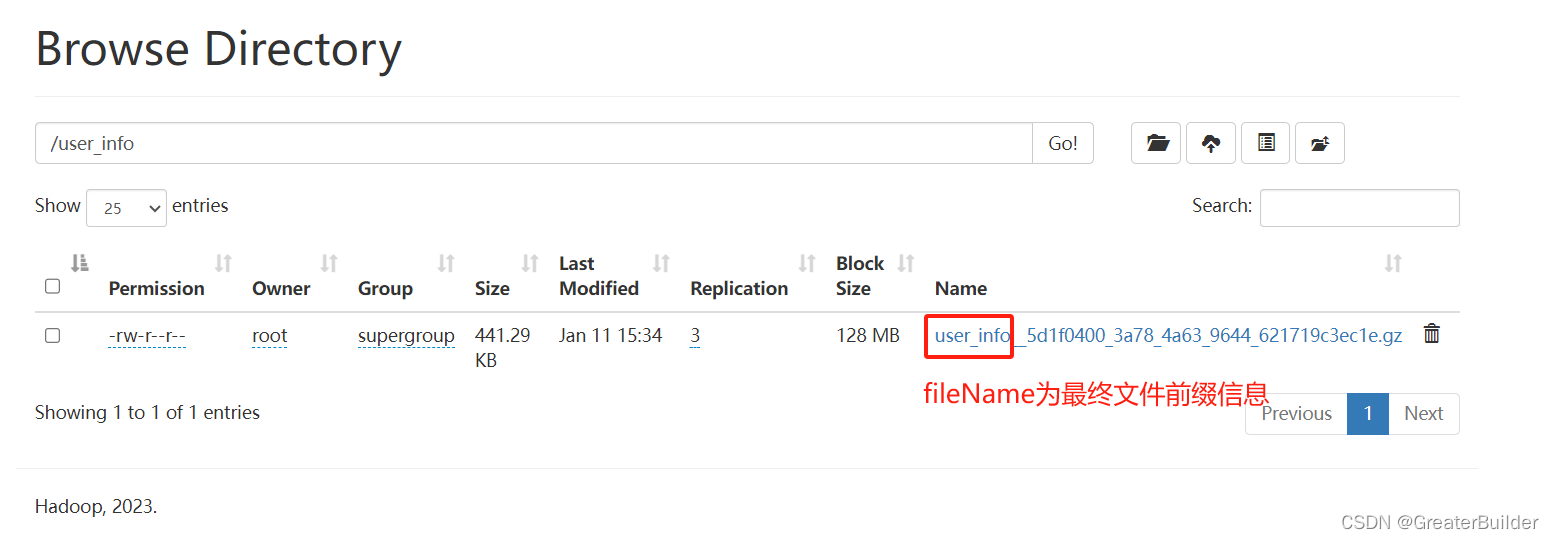
"fileName": "user_info", #HDFS文件名前缀,如下图所示
"fileType": "text", #HDFS文件类型,目前支持text和orc
"path": "/user_info", #HDFS文件系统目标路径
"writeMode": "append" #数据写入模式(append:追加;nonConflict:若写入目录有同名文件【前缀相同】,则会报错)
}
}
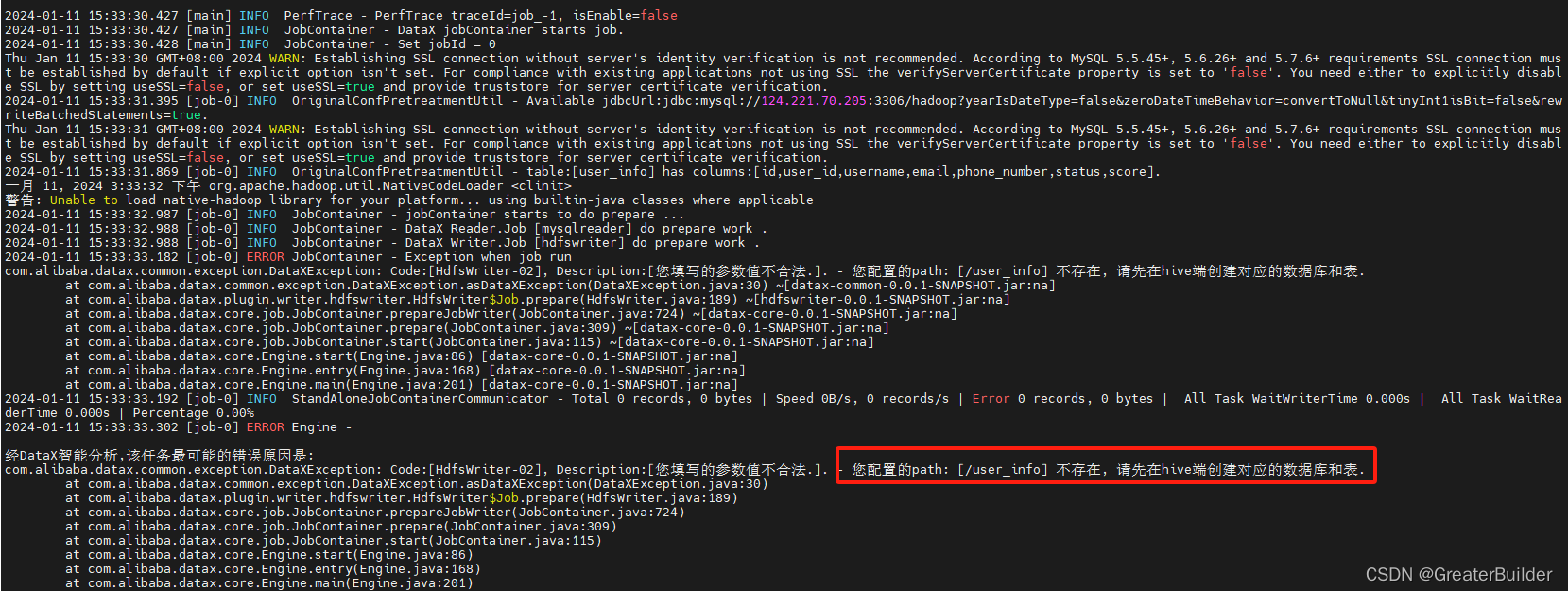
3、执行同步
python /wz_program/datax/bin/datax.py /wz_program/datax/job/user_info.json
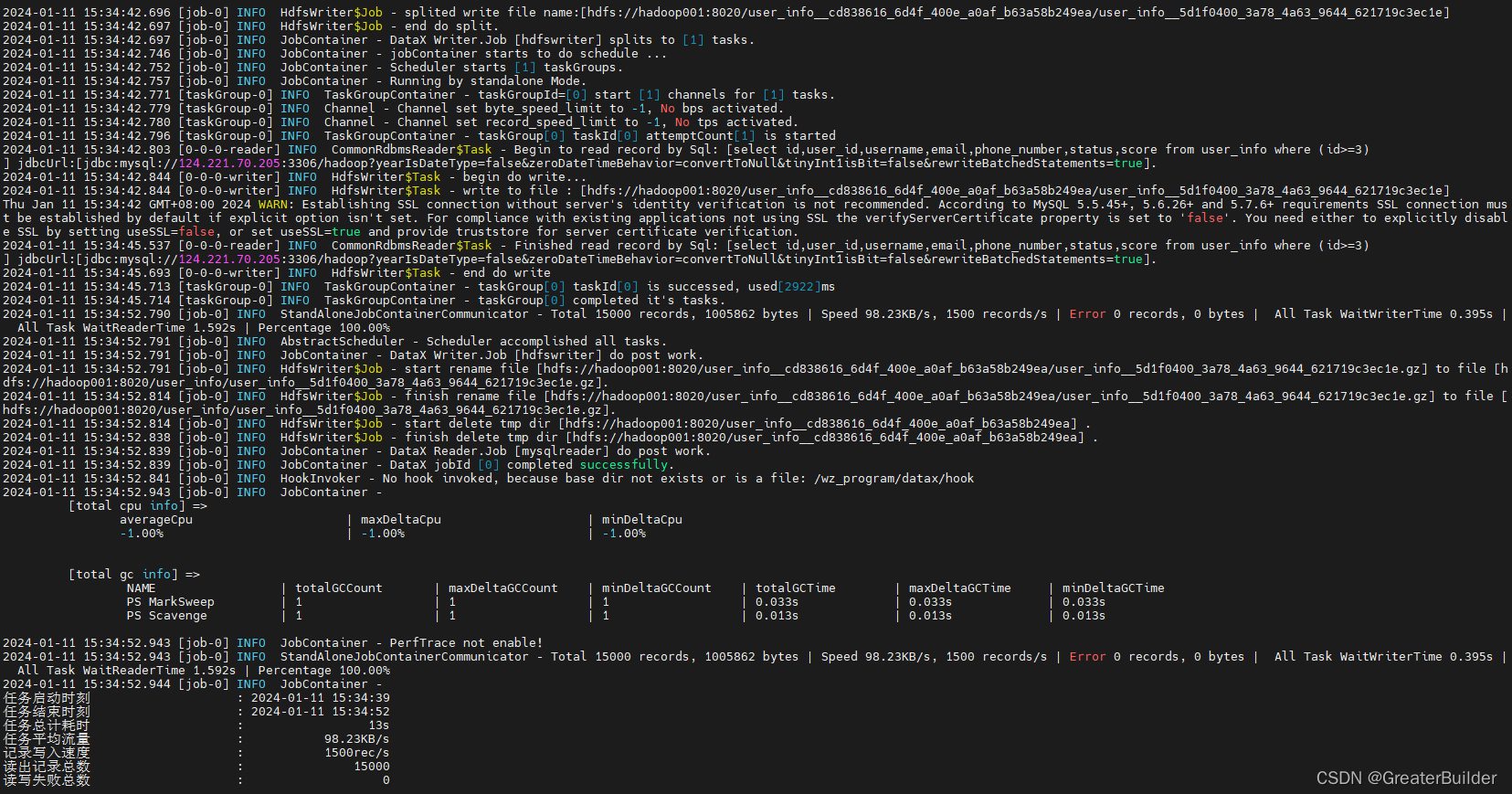
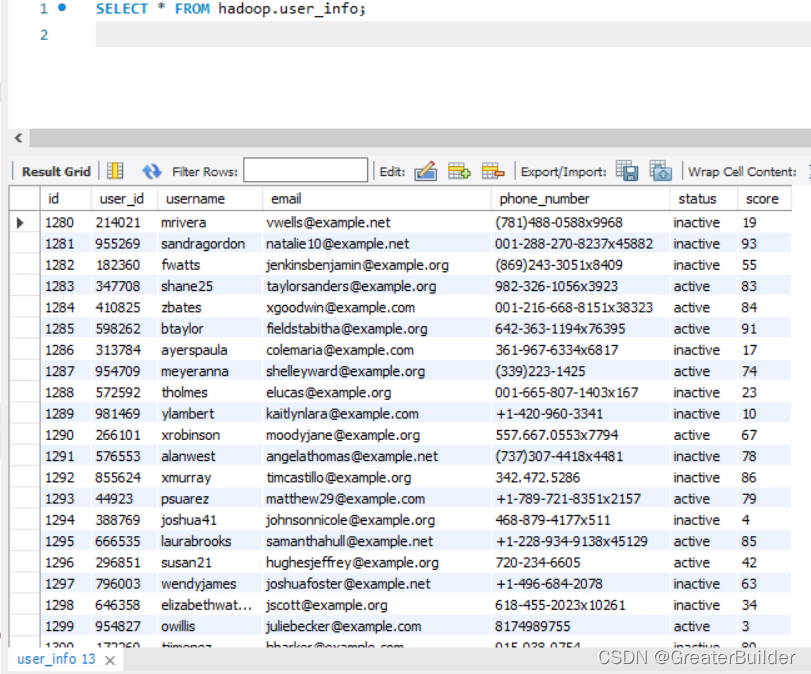
4、验证同步结果
进入hdfs查询同步后的文件,前缀即为我们配置的名称,下载该文件查询同步的结果:
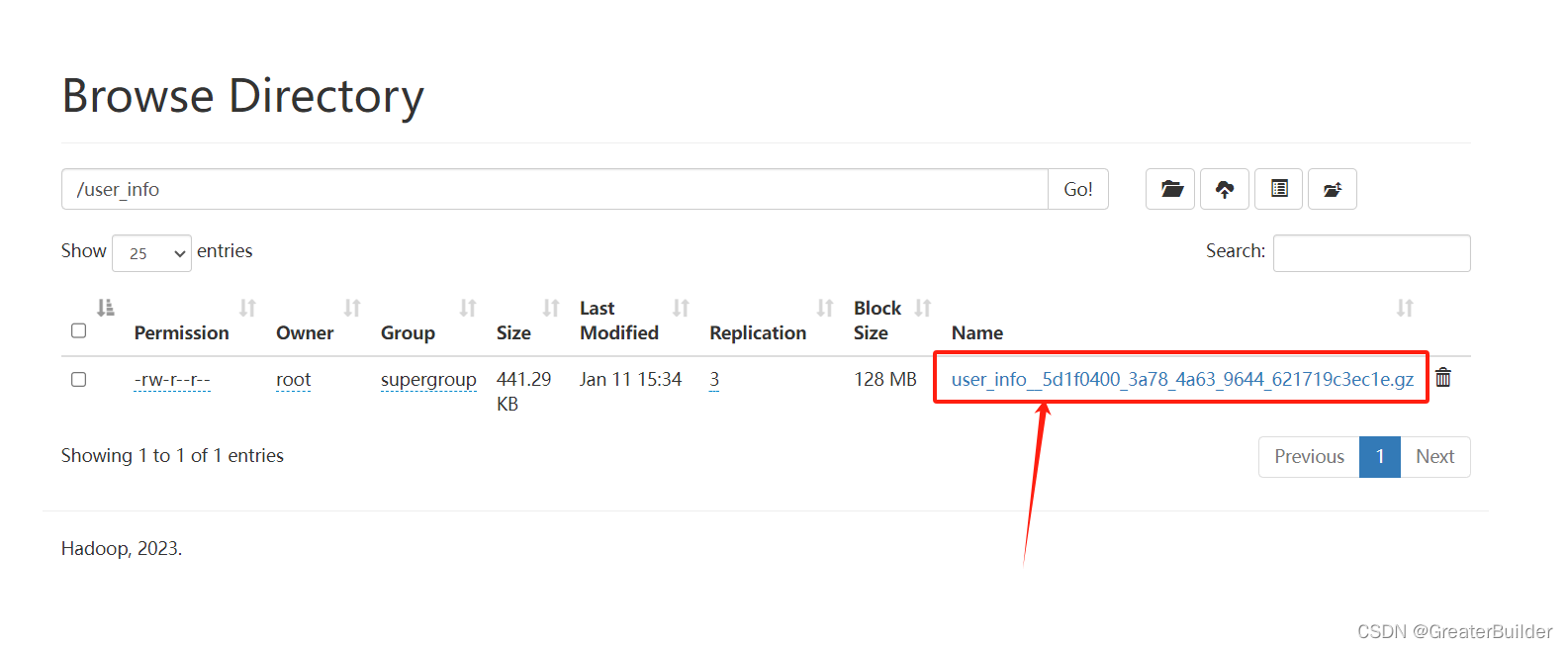
同步结果如下:
文章来源:https://blog.csdn.net/qq_26709459/article/details/135531332
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- fastadmin传递参数给html和js,通过身份判断动态显示列表头部住店和离店按钮
- MySQL数据库,表的增量备份与恢复
- P1379 八数码难题
- ERROR: requested WAL segment xxxx has already been removed 错误处理
- python中的多线程
- 2024最新适用于 Windows 、Mac 的最佳屏幕录制软件
- 企业官网搭建:打造专业形象的关键步骤
- 基于ssm汽车租赁系统业务管理子系统论文
- 也谈人工智能——AI科普入门
- 一文讲透使用SPSS统计分析软件如何处理缺失值?