Rust-所有权和移动语义
什么是所有权
拿C语言的代码来打个比方。我们可能会在堆上创建一个对象,然后使用一个指针来管理这个对象:
Foo *p =make_object("args");
接下来,我们可能需要使用这个对象:
use_object(p);
然而,这段代码之后,谁能猜得到,指针p指向的对象究竟发生了什么?它是否被修改过了?它还存在吗,是否已经被释放?是否有另外一个指针现在也同时指向这个对象?我们还能继续读取、修改或者释放这个对象吗?实际上,除了去了解use_object的内部实现之外,我们没办法回答以上问题。
对此,C++进行了一个改进,即通过“智能指针”来描述“所有权”(Ownership)概念。
这在一定程度上减少了内存使用bug,实现了“半自动化”的内存管理。
而Rust在此基础上更进一步,将“所有权”的理念直接融入到了语言之中。
“所有权”代表着以下意义:
- 每个值在Rust中都有一个变量来管理它,这个变量就是这个值、这块内存的所有者;
- 每个值在一个时间点上只有一个管理者;
- 当变量所在的作用域结束的时候,变量以及它代表的值将会被销毁。
拿前面已经讲过的字符串String类型来举例:

当我们声明一个变量s,并用String类型对它进行初始化的时候,这个变量s就成了这个字符串的“所有者”。如果我们希望修改这个变量,可以使用mut修饰s,然后调用String类型的成员方法来实现。
当main函数结束的时候,s将会被析构,它管理的内存(不论是堆上的,还是栈上的)则会被释放。
我们一般把变量从出生到死亡的整个阶段,叫作一个变量的“生命周期”。
比如这个例子中的局部变量s,它的生命周期就是从let语句开始,到main函数结束。
在上述示例的基础上,若做一点修改:

这里出现了编译错误。编译器显示,在let s1 =s;语句中,原本由s拥有的字符串已经转移给了s1这个变量。所以,后面继续使用s是不对的。
也就是前面所说的每个值只有一个所有者。变量s的生命周期从声明开始,到move给s1就结束了。
变量s1的生命周期则是从它声明开始,到函数结束。
而字符串本身,由String::from函数创建出来,到函数结束的时候就会销毁。
中间所有权的转换,并不会将这个字符串本身重新销毁再创建。
在任意时刻,这个字符串只有一个所有者,要么是s,要么是s1。
在用变量s初始化s1的时候,并不会造成s的生命周期结束。
这里只会调用string类型的复制构造函数复制出一个新的字符串,于是在后面s1和s都是合法变量。
在Rust中,我们要模拟这一行为,需要手动调用clone()方法来完成:

在Rust里面,不可以做“赋值运算符重载”,若需要“深复制”,必须手工调用clone方法。
这个clone方法来自于std::clone::Clone这个trait。clone方法里面的行为是可以自定义的。
移动语义
一个变量可以把它拥有的值转移给另外一个变量,称为“所有权转移”。
赋值语句、函数调用、函数返回等,都有可能导致所有权转移。

所有权转移的步骤分解如下。
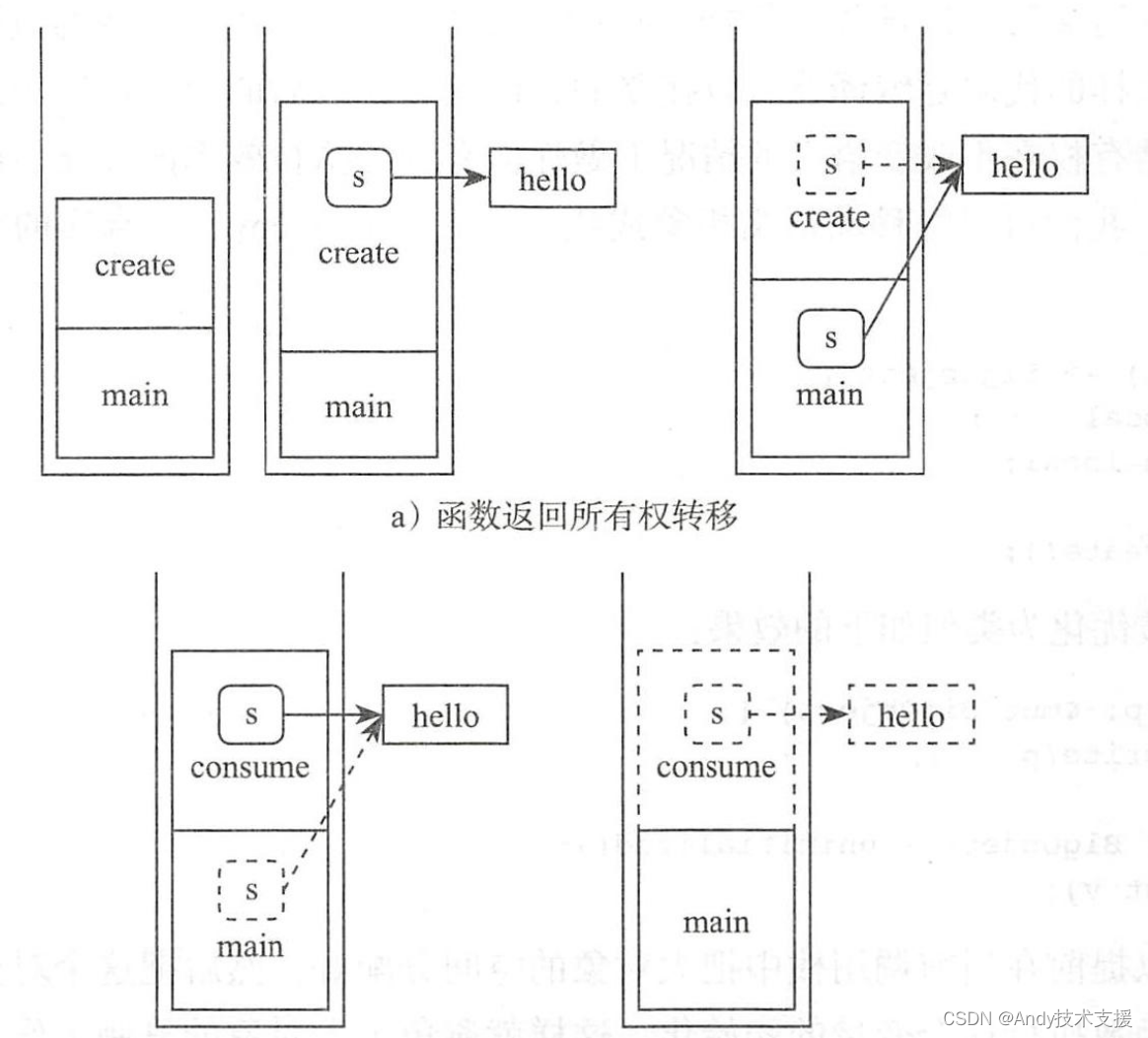
- main函数调用create函数。
- 在调用create函数的时候创建了字符串,在栈上和堆上都分配有内存。局部变量s是这些内存的所有者。
- create函数返回的时候,需要将局部变量s移动到函数外面,这个过程就是简单地按字节复制memcpy。
- 同理,在调用consume函数的时候,需要将main函数中的局部变量转移到consume函数,这个过程也是简单地按字节复制memcpy。
- 当consume函数结束的时候,它并没有把内部的局部变量再转移出来,这种情况下,consume内部局部变量的生命周期就该结束了。这个局部变量s生命周期结束的时候,会自动释放它所拥有的内存,因此字符串也就被释放了。
Rust中所有权转移的重要特点是,它是所有类型的默认语义。
这里再重复一遍,请大家牢牢记住,Rust中的变量绑定操作,默认是move语义,执行了新的变量绑定后,原来的变量就不能再被使用!一定要记住!
Rust的这一规定非常有利于编译器静态检查。
与之相对的,C++的做法就不一样了,它允许赋值构造函数、赋值运算符重载,因此在出现“构造”或者“赋值”操作的时候,有可能表达的是完全不同的含义,这取决于程序员如何实现重载。C++的这个设计具有巨大的灵活性,但是不恰当的实现也可能造成内存不安全。
而Rust的这一设计大幅降低了语言的复杂度,“移动语义”不可能执行用户的自定义代码,没有任何内存安全风险,而且满足异常安全。
在C++里面,std::vectorv1 =v2;是复制语义,而Rust里面的let v1:Vec=v2 ;是移动语义。如果要在Rust里面实现复制语义,需要显式写出函数调用let v1:Vec=v2.clone();。如果我们在C++中实现移动语义,则需要户自定义实现移动构造函数及移动赋值运算符。
对于“移动语义”,最后还需要强调的一点是,“语义”不代表最终的执行效率。
“语义”只是规定了什么样的代码是编译器可以接受的,以及它执行后的效果可以用怎样的思维模型去理解。
编译器有权在不改变语义的情况下做任何有利于执行效率的优化。
语义和优化是两个阶段的事情。我们可以把移动语义想象成执行了一个memcpy,但真实的汇编代码未必如此。比如:

完全可能被优化为类似如下的效果:

编译器可以提前在当前调用栈中把大对象的空间分配好,然后把这个对象的指针传递给子函数,由子函数执行这个变量的初始化。
这样就避免了大对象的复制工作,参数传递只是一个指针而已。
这么做是完全满足移动语义要求的,而且编译器还有权利做更多类似的优化。
复制语义
默认的move语义是Rust的一个重要设计,但是任何时候需要复制都去调用clone函数会显得非常烦琐。
对于一些简单类型,比如整数、bool,让它们在赋值的时候默认采用复制操作会让语言更简单。
比如下面这个程序就可以正常编译通过:

编译器并没有阻止v1被使用,这是为什么呢?
因为在Rust中有一部分“特殊照顾”的类型,其变量绑定操作是copy语义。
所谓的copy语义,是指在执行变量绑定操作的时候,v2是对v1所属数据的一份复制。
v1所管理的这块内存依然存在,并未失效,而v2是新开辟了一块内存,它的内容是从v1管理的内存中复制而来的。和手动调用clone方法效果一样,let v2 =v1;等效于let v2 =v1.clone();。
使用文件系统来打比方。
copy语义就像“复制、粘贴”操作。操作完成后,原来的数据依然存在,而新的数据是原来数据的复制品。
move语义就像“剪切、粘贴”操作。
操作完成后,原来的数据就不存在了,被移动到了新的地方。
这两个操作本身是一样的,都是简单的内存复制,区别在于复制完以后,原先那个变量的生命周期是否结束。
Rust中,在普通变量绑定、函数传参、模式匹配等场景下,凡是实现了std::marker::Copy trait的类型,都会执行copy语义。
基本类型,比如数字、字符、bool等,都实现了Copy trait,因此具备copy语义。
对于自定义类型,默认是没有实现Copy trait的,但是我们可以手动添上。示例如下:

编译通过。现在Foo类型也拥有了复制语义。在执行变量绑定、函数参数传递的时候,原来的变量不会失效,而是会新开辟一块内存,将原来的数据复制过来。
绝大部分情况下,实现Copy trait和Clone trait是一个非常机械化的、重复性的工作,clone方法的函数体要对每个成员调用一下clone方法。Rust提供了一个编译器扩展derive attribute,来帮我们写这些代码,其使用方式为#[derive(Copy,Clone)]。
只要一个类型的所有成员都具有Clone trait,我们就可以使用这种方法来让编译器帮我们实现Clone trait了。

Box类型
Box类型是Rust中一种常用的指针类型。它代表“拥有所有权的指针”,类似于C++里面的unique_ptr(严格来说,unique_ptr更像Option<Box>)。
 Box类型永远执行的是move语义,不能是copy语义。
Box类型永远执行的是move语义,不能是copy语义。
原因大家想想就可以明白,Rust中的copy语义就是浅复制。对于Box这样的类型而言,浅复制必然会造成二次释放问题。
对于Rust里面的所有变量,在使用前一定要合理初始化,否则会出现编译错误。
对于Box/&T /&mut T这样的类型,合理初始化意味着它一定指向了某个具体的对象,不可能是空。
如果用户确实需要“可能为空的”指针,必须使用类型option<Box>。
Rust里面还有一个保留关键字box(注意是小写)。它可以用于把变量“装箱”到堆上。目前这个语法依然是unstable状态,需要打开feature gate才能使用,示例如下:

Copy的实现条件
并不是所有的类型都可以实现Copy trait。Rust规定,对于自定义类型,只有所有成员都实现了Copy trait,这个类型才有资格实现Copy trait。
?
常见的数字类型、bool类型、共享借用指针&,都是具有Copy属性的类型。而Box、Vec、可写借用指针&mut等类型都是不具备Copy属性的类型。
对于数组类型,如果它内部的元素类型是Copy,那么这个数组也是Copy类型。对于元组tuple类型,如果它的每一个元素都是Copy类型,那么这个tuple也是Copy类型。
struct和enum类型不会自动实现Copy trait。只有当struct和enum内部的每个元素都是Copy类型时,编译器才允许我们针对此类型实现Copy trait。比如下面这个类型,虽然它的成员是Copy类型,但它本身不是Copy类型:

自动derive
绝大多数情况下,实现Copy Clone这样的trait都是一个重复而无聊的工作。因此,Rust提供了一个attribute,让我们可以利用编译器自动生成这部分代码。示例如下:

这里的derive会让编译器帮我们自动生成impl Copy和impl Clone这样的代码。自动生成的clone方法,会依次调用每个成员的clone方法。
通过derive方式自动实现Copy和手工实现Copy有微小的区别。
当类型具有泛型参数的时候,比如struct MyStruct{},通过derive自动生成的代码会自动添加一个T:Copy的约束。
目前,只有一部分固定的特殊trait可以通过derive来自动实现。
将来Rust会允许自定义的derive行为,让我们自己的trait也可以通过derive的方式自动实现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 西部市场的无限潜力与成都的崛起“2024成都电子信息展会”
- python深拷贝和浅拷贝
- 如何基于 ESP32 芯片测试 WiFi 连接距离、获取连接的 AP 信号强度(RSSI)以及 WiFi吞吐测试
- camtasia studio 2023如何录制微课
- ffmpeg6.0-ffplay.c源码分析(二)之整体框架大流程分析
- } expected.Vetur(1005)
- ES新特性和浏览器的 5 种 Observer
- 免费SSL证书安全吗?
- 在windows上安装cygwin
- 好用的网站性能监测与服务可用性监测工具盘点