机器学习实验报告- KNN算法
目录
一、算法介绍
1.1算法背景
K最近邻(KNN)算法是一种基本的模式识别和机器学习算法,发展于20世纪60年代。它是一种基于“类的相似性”进行分类的无参数算法,在许多实际应用中取得了良好的效果。在分类问题中,KNN算法将一个测试样本所在区域内训练样本的多数类作为该测试样本的预测类别;在回归问题中,KNN算法利用k个最近邻居的平均值或加权平均值预测连续变量。
1.2基本假设
KNN算法的基本假设是相似的样本具有相似的类别。这意味着,如果两个样本在特征空间中越相似,它们所属的类别也越相似。因此,KNN算法认为,未知样本所属的类别应该与其最近邻居的类别相同或相似。
1.3算法原理阐述
当我们要对一个未知样本进行分类时,K最近邻(KNN)算法会找出与该未知样本最相似的K个已知样本。这里的相似性是通过计算它们在特征空间中的距离来衡量的。然后,KNN算法会查看这K个最近邻居中哪个类别出现得最多,将该类别作为未知样本的预测类别。
我认为我们可以将KNN算法类比为选择身边K个朋友的方式。如果想知道某家餐厅的好坏,但你没有去过。可以问询身边的K个朋友他们对这家餐厅的评价。然后,你会选择其中出现最多次的评价作为你对这家餐厅的评价,认为它的好坏程度和多数朋友的评价相似。
简单的说,KNN算法的原理就是根据已知样本的特征和类别,在特征空间中找出与未知样本最相似的K个样本,通过多数投票的方式确定未知样本所属的类别。这种算法简单直观,可以应用于分类和回归问题,并且不需要事先训练模型,被广泛应用于各种领域的机器学习任务中。
1.4算法关键点
1.选择合适的K值,以避免过拟合或欠拟合。
KNN中的k是一个超参数,需要我们进行指定,一般情况下这个k和数据有很大关系,都是通过网格搜索、交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据)进行选择,从选取一个较小的k值开始,不断增加k的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
但是建议使用交叉验证的时候,k∈[2,20],使用交叉验证得到一个很好的k值。需注意最好k的取值为奇数,防止出现平票而无法分类的情况。
如下图
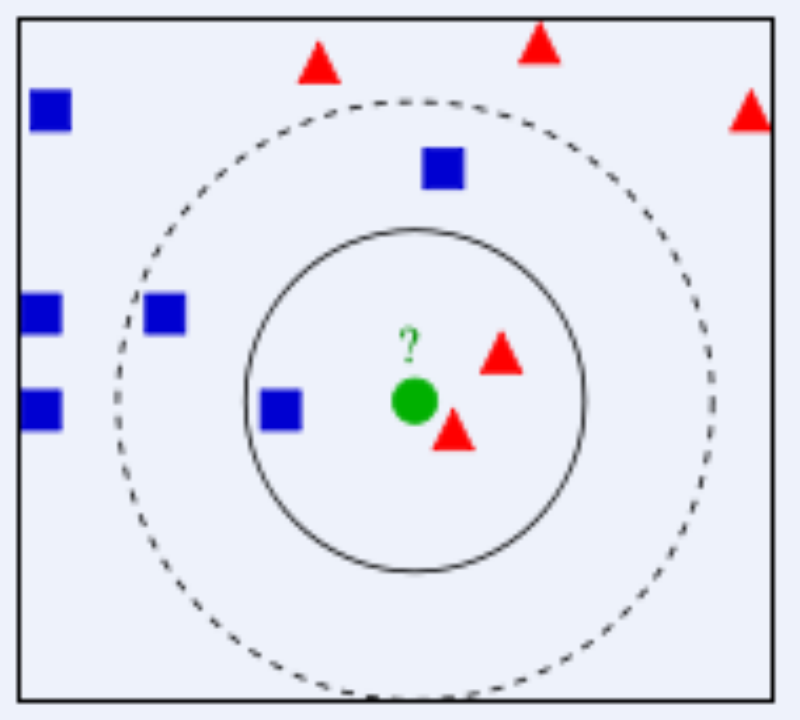
假设实线圈为k=3,圈内红色点更多,因此将新来的绿点归为红色点一类; ???假设虚线圈为k=5,圈内则是蓝色点更多,便将新来的绿点归为蓝色点一类。
???????????????
k值还可以表示我们的模型复杂度,k值越小,意味着模型复杂度变大,更容易过拟合(用极少数的样例来绝对这个预测的结果,很容易产生偏见,这就是过拟合)。k值越大,学习的估计误差越小,但是学习的近似误差就会增大,容易造成欠拟合。
2.选择合适的距离度量方法,以确保准确地衡量样本之间的相似性。
以下列出三种常用的距离度量方法,并解释欧式距离为KNN算法最合适的距离度量算法的原因
I ?欧式距离(Euclidean Distance)(2-范数)
欧式距离是最常用的距离度量方法,它计算样本之间的几何距离。在二维空间中,欧式距离计算公式为:
??????????????? ?
?
欧式距离对于连续特征适用,在高维空间中具有较好的表现。
II ??曼哈顿距离(Manhattan Distance)(1-范数)
曼哈顿距离是计算样本之间城市街区距离(也称为L1距离)的方法。在二维空间中,曼哈顿距离计算公式为:
???????????????
曼哈顿距离对于稀疏数据和离散特征适用,在某些应用场景下比欧氏距离更合适。
III ?切比雪夫距离(Chebyshev Distance):
切比雪夫距离是计算样本之间的最大坐标差的方法。在二维空间中,切比雪夫距离计算公式为:

切比雪夫距离对于异常值不敏感,在离群值较多的情况下可以使用。
在K最近邻(KNN)算法中,欧式距离常被用作KNN算法的距离度量方法,这是因为以下几个原因:
I?几何直观性:欧式距离对于连续特征的数据具有直观的几何解释。它衡量了样本在特征空间中的直线距离,更接近的样本在空间中更接近。
II?特征权重一致性:欧式距离在对各个特征值赋予相同权重时表现有效。KNN算法将每个特征都视为同等重要,欧式距离能够满足这个要求。
III?高效性:计算两个样本之间的欧式距离是一种简单而高效的计算方式。通过向量操作,可以快速地计算出所有训练样本与测试样本之间的欧式距离。
3.选取合理的分类决策规则
分类决策规则一般使用多数表决法。即如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
二、数据集描述
为了进一步掌握KNN算法,尝试使用KNN算法改进约会网站的配对效果。
2.1数据集介绍
这个数据集是由1000条数据组成,其中每条数据都有三个数值型特征和一个类别标签,具体信息如下:
(1)每年获得的飞行常客里程数(Continuous):
这个数值型特征表示一个人每年在飞机上旅行的里程数,即获得的飞行常客里程数。该特征为连续型变量。
(2)玩视频游戏所耗时间百分比(Continuous):
这个数值型特征表示一个人用于玩视频游戏的时间占其可用时间的百分比。该特征为连续型变量。
(3)每周消费的冰淇淋公升数(Continuous):
这个数值型特征表示一个人每周消费的冰淇淋的公升数。该特征为连续型变量。
(4)类别标签(Categorical):
类别标签表示一个人的魅力水平,共分为3个类别,分别是:
1代表“不喜欢的人”:表示该人的社交能力较差。
2代表“魅力一般的人”:表示该人有一定的社交魅力。
3代表“极具魅力的人”:表示该人在社交方面非常有魅力。
数据集格式如下,仅呈现部分数据

2.2 数据处理
(1)数据清洗:
数据清洗是指检查和处理数据集中的错误、缺失值和异常值等问题。常见的数据清洗方法包括:处理缺失值、处理异常值
(2)特征选择:
特征选择是指从原始数据集中选择最具有预测能力的特征子集。常用的特征选择方法包括:
过滤式选择、包装式选择、嵌入式选择
(3)归一化:
归一化是指将不同范围的特征值映射到统一的区间,以消除特征之间的量纲差异。
常见的归一化方法有:
最小-最大归一化(Min-Max Scaling)、标准化(Standardization)。
此次实验,在完成前期对数据的清洗和特征选择后,测试代码中的auto_norm(dataSet)函数实现了对数据的归一化处理。相关代码如下图所示:

通过对数据集进行归一化处理,可使得数据集中的特征值都在0到1之间。这可以消除不同特征之间的量纲差异,使得它们具有相同的重要性。
在对数据进行预处理后,得到有效的1000条数据,并依据其利用KNN算法进行实例测试。???????
三、算法实现
3.1代码实现(python)
完整代码由四个功能函数file_matrix()、auto_norm()、KNN()、datingClassTest()组成,最后进行调用。完整代码来自网络。为更好的理解KNN算法原理,本次实验对其进行复现,分析代码功能。
import?numpy?as?np
import?pandas?as?pd
import?operator
def?load_dataset(filename):
????"""
????加载数据集并进行预处理
????:param?filename:?数据集文件名
????:return:?特征矩阵和标签向量
????"""
????data?=?pd.read_csv(filename,?sep='\t').values
????features?=?data[:,?0:3]
????labels?=?data[:,?-1]
????return?features,?labels
def?normalize_dataset(dataset):
????"""
????数据集归一化
????:param?dataset:?特征矩阵
????:return:?归一化后的特征矩阵,范围和最小值
????"""
????min_vals?=?dataset.min(0)
????max_vals?=?dataset.max(0)
????ranges?=?max_vals?-?min_vals
????norm_dataset?=?(dataset?-?min_vals)?/?ranges
????return?norm_dataset,?ranges,?min_vals
def?kNN(inX,?dataset,?labels,?k):
????"""
????kNN算法
????:param?inX:?需要分类的数据
????:param?dataset:?样本数据集
????:param?labels:?样本数据的标签
????:param?k:?需要取出的前k个
????:return:?最有可能的分类
????"""
????dataset_size?=?dataset.shape[0]
????diff_mat?=?np.tile(inX,?(dataset_size,?1))?-?dataset
????sq_diff_mat?=?diff_mat?**?2
????sq_distances?=?sq_diff_mat.sum(axis=1)
????distances?=?sq_distances?**?0.5
????sorted_dist_indices?=?distances.argsort()
????class_count?=?{}
????for?i?in?range(k):
????????vote_i_label?=?labels[sorted_dist_indices[i]]
????????class_count[vote_i_label]?=?class_count.get(vote_i_label,?0)?+?1
????sorted_class_count?=?sorted(class_count.items(),?key=operator.itemgetter(1),?reverse=True)
????return?sorted_class_count[0][0]
def?dating_class_test():
????ho_ratio?=?0.10??#?用于测试的数据比例
????dataset,?labels?=?load_dataset('datingTestSet2.txt')??#?加载数据集
????norm_dataset,?ranges,?min_vals?=?normalize_dataset(dataset)??#?归一化数据集
????m?=?norm_dataset.shape[0]
????num_test_vecs?=?int(m?*?ho_ratio)
????error_count?=?0.0
????for?i?in?range(num_test_vecs):
????????classifier_result?=?kNN(norm_dataset[i,?:],?norm_dataset[num_test_vecs:m,?:],?labels[num_test_vecs:m],?4)
????????print("预测结果:%d,真实结果:%d"?%?(classifier_result,?labels[i]))
????????if?classifier_result?!=?labels[i]:
????????????error_count?+=?1.0
????print("测试集大小:%d,分类错误个数:%d"?%?(num_test_vecs,?error_count))
????print("分类错误率:%.2f%%"?%?(error_count?/?float(num_test_vecs)?*?100))
????accuracy?=?(1?-?error_count?/?float(num_test_vecs))?*?100
????print("准确率:%.2f%%"?%?accuracy)
if?__name__?==?'__main__':
????dating_class_test()代码功能简要分析:
(1)file_matrix(filename)函数
该函数的目的是读取源数据文件并将其转换为规整好的数据矩阵和类标签向量。
(2)auto_norm(dataSet)函数
该函数的目的是对数据集进行归一化处理,使得数据集中的特征值都在0到1之间。这可以消除不同特征之间的量纲差异,使得它们具有相同的重要性。
(3)kNN(inX,dataSet,lables,k)函数
此函数实现了k最近邻(kNN)算法。kNN算法用于分类问题,通过计算待分类数据点与已知类别数据点之间的距离,并选择距离最近的k个邻居来确定待分类数据点的类别。即根据样本数据集和标签,在给定一个待分类数据点时,利用k最近邻算法预测其所属的类别。
(4)datingClassTest()函数
此函数实现了一个名为datingClassTest的函数。该函数用于测试kNN算法在约会数据集上的分类准确率。该函数通过将数据集分为训练集和测试集,使用kNN算法对测试集中的样本进行分类预测,并计算分类错误率和分类准确率。
3.2代码复现结果
(1)测试集为100(下图仅截取了部分展示),k=4

测试的结果是错误率为4.00%,在接受范围之内。
(2)改变测试集大小,hoRatio取0.20,即测试集大小为200,k=4

测试的结果是准确率为92.50%
四、实验讨论
4.1关于KNN算法优缺点的讨论
(1)优点
I ??KNN算法是一种非参数方法,不需要对数据的分布进行假设,因此可以适用于各种数据类型和分布情况。
II ??KNN算法简单易懂,容易实现,在处理小规模数据时表现良好。
III ?KNN算法可以用于分类和回归问题,并可以处理多分类和回归问题。
IV ?KNN算法对噪声数据具有高度的鲁棒性,因为它可以排除异常值的影响。
(2)缺点
I ??KNN算法需要保存全部的训练数据,因此在处理大规模数据时,存储和计算复杂度都会较高。
II ?KNN算法对输入数据的维度非常敏感,如果特征空间的维度很高,则距离计算会变得非常困难,同时分类器的效果会受到影响。
III ?KNN算法的预测速度较慢,因为需要计算每个测试样本与所有训练样本之间的距离,时间复杂度为O(Nd),其中N为训练样本数,d为特征维数。
IV ?KNN算法对样本不平衡问题敏感。如果某个类别的样本数量远远超过其他类别,则会导致分类器准确率降低。
4.2关于k值对实验结果(准确率)影响的讨论
为了测试k值对KNN算法准确率的影响,分别从1到10取k进行准确率的计算,利用python绘制出了如下折线图
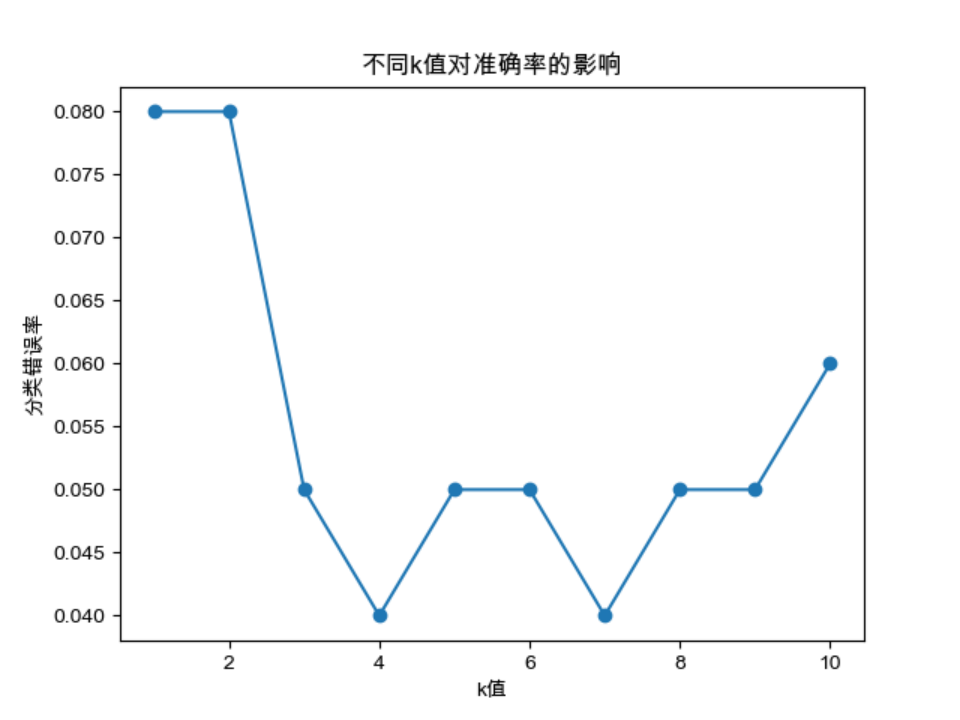
观察折线图,可得到如下结论:
I?随着k值的增大,分类错误率逐渐减小,并趋于稳定,但并不是k越大越好,因为如果k值过大,会使模型变得过于简单,无法捕捉到数据的复杂规律,导致误差增大。
II?在这个数据集上,选择k=4或7时可以得到最佳的分类准确率。
4.3关于测试集数目对KNN算法准确率的讨论
通过在原有代码的基础上进行修改,测试集大小将在10到500的范围内进行遍历,并绘制了测试集大小对准确率的影响图表,如下所示:
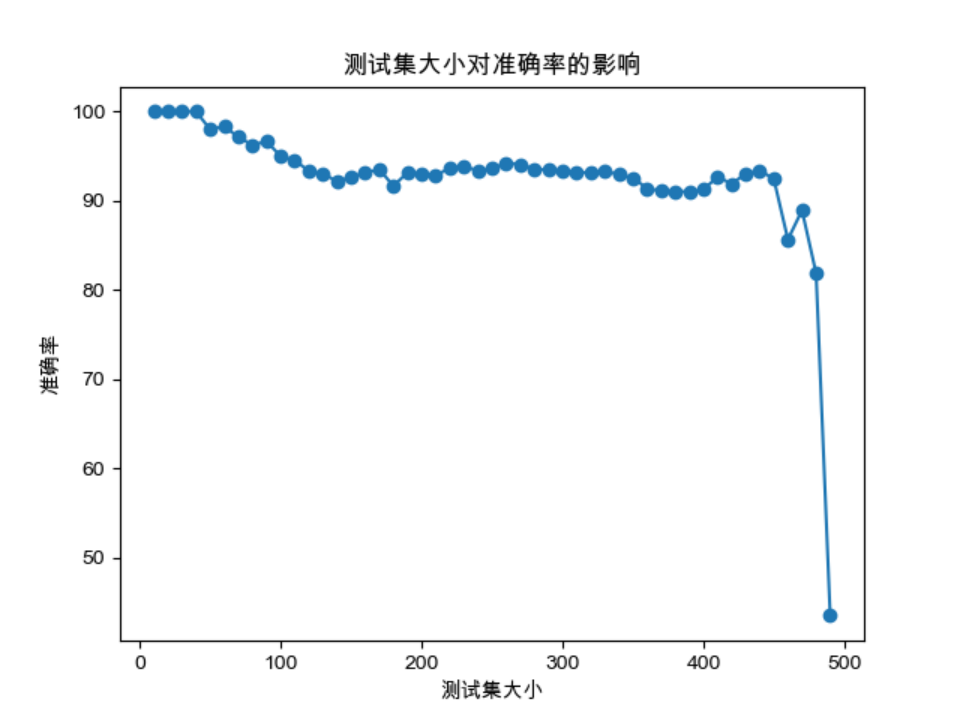
通过观察测试结果和准确率与测试集大小的关系图表,可以得出在200-300左右的测试集大小范围内,KNN算法能够获得较高的准确率。超过这个范围后,增加测试集的大小对准确率的提升较为有限。因为数据集的特性和分布导致了准确率的限制。
五、实验总结
K最近邻算法(KNN)是一种监督学习算法,属于非参数学习方法,其核心思想是如果一个样本在特征空间中的k个最临近的样本中的大多数属于某一个类别,则该样本也属于这个类别。
在本次实验中,我复现了K最近邻(KNN)算法,并对代码进行了分析和讨论。KNN算法是一种简单易懂且容易实现的分类算法,适用于各种数据类型和分布情况,并具有较高的鲁棒性。但是,KNN算法在处理大规模数据时存储和计算复杂度较高,对输入数据的维度敏感,并且预测速度较慢。在实验中,我们还讨论了K值对准确率的影响以及测试集大小对KNN算法准确率的影响。根据实验结果,选择合适的K值和测试集大小可以获得较高的准确率。
总的来说,KNN算法是一个简单但有效的分类算法,能够在很多问题中得到应用。通过本次实验,我对KNN算法有了更深入的理解,对其在实际应用中的优缺点有了更清晰的认识;除此之外,我对机器学习这门学科也有了更深厚的兴趣,因为不再是课堂上复杂深奥的机器学习理论。通过对代码的复现,算法也变得有趣起来。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【YOLO系列】YOLOv8 -【教AI的陶老师】
- [NISACTF 2022]midlevel
- 【MySQL】用户管理
- C语言-蓝桥杯算法提高VIP-产生数
- 【阿里云服务器数据迁移】 同一个账号 不同区域服务器
- 助力公益事业,吉林长春市第二社会福利院与清雷科技达成合作
- Redis HyperLogLog 命令
- 关键字:abstract关键字
- Developer’s Manual of CK_Label_V14
- 华为端口隔离高级用法经典案例